
python爬蟲——豆瓣電影Top250
主要功能
1.利用lxml爬取豆瓣電影top250https://movie.douban.com/top250
2.用xpath確定所爬取資料的位置
3.獲取資料,將資料寫到txt文件中儲存
實現步驟
1.網頁分析,進入網站(本文使用的是谷歌瀏覽器)
2.按F12開啟開發者工具,找到Elements,進行網頁內容的分析
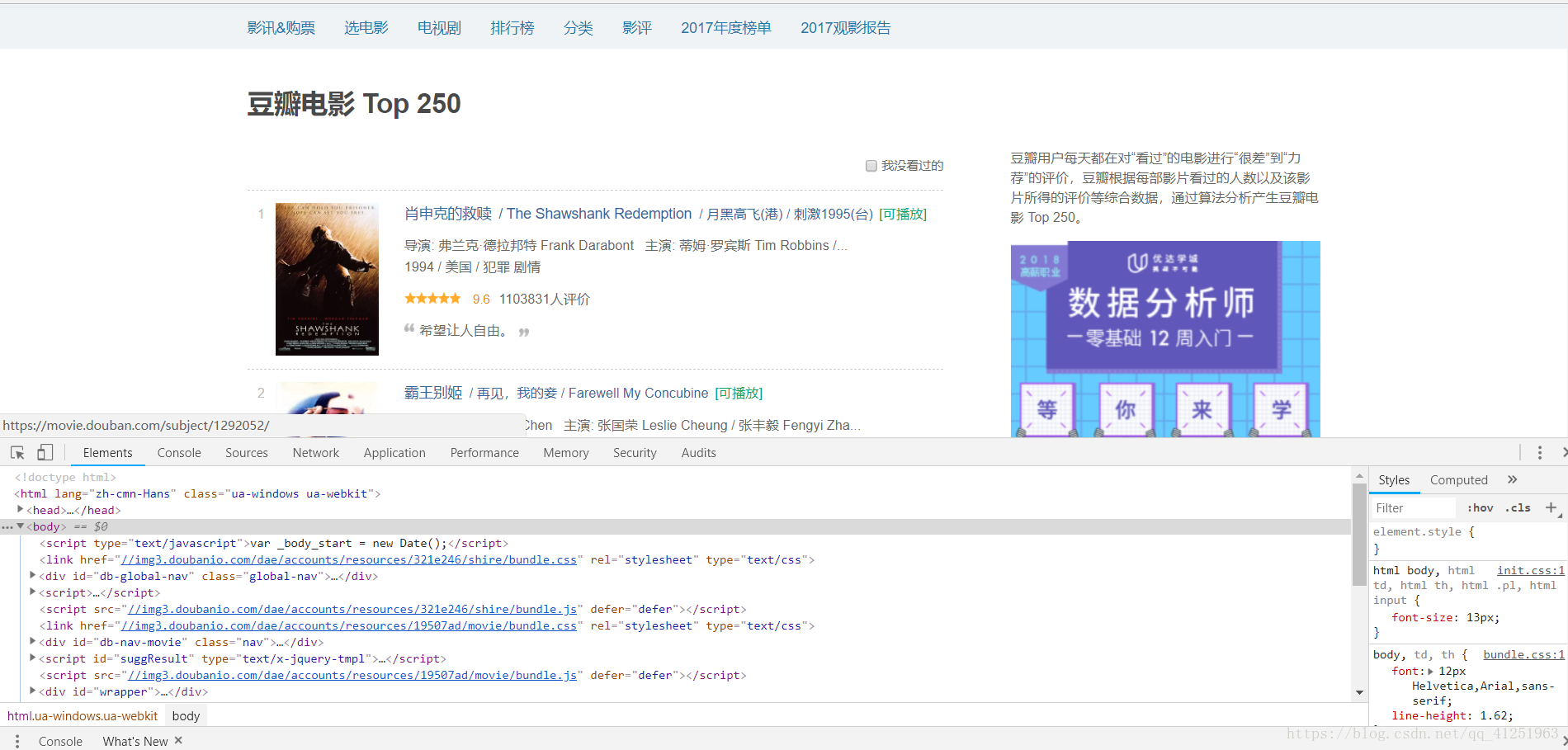
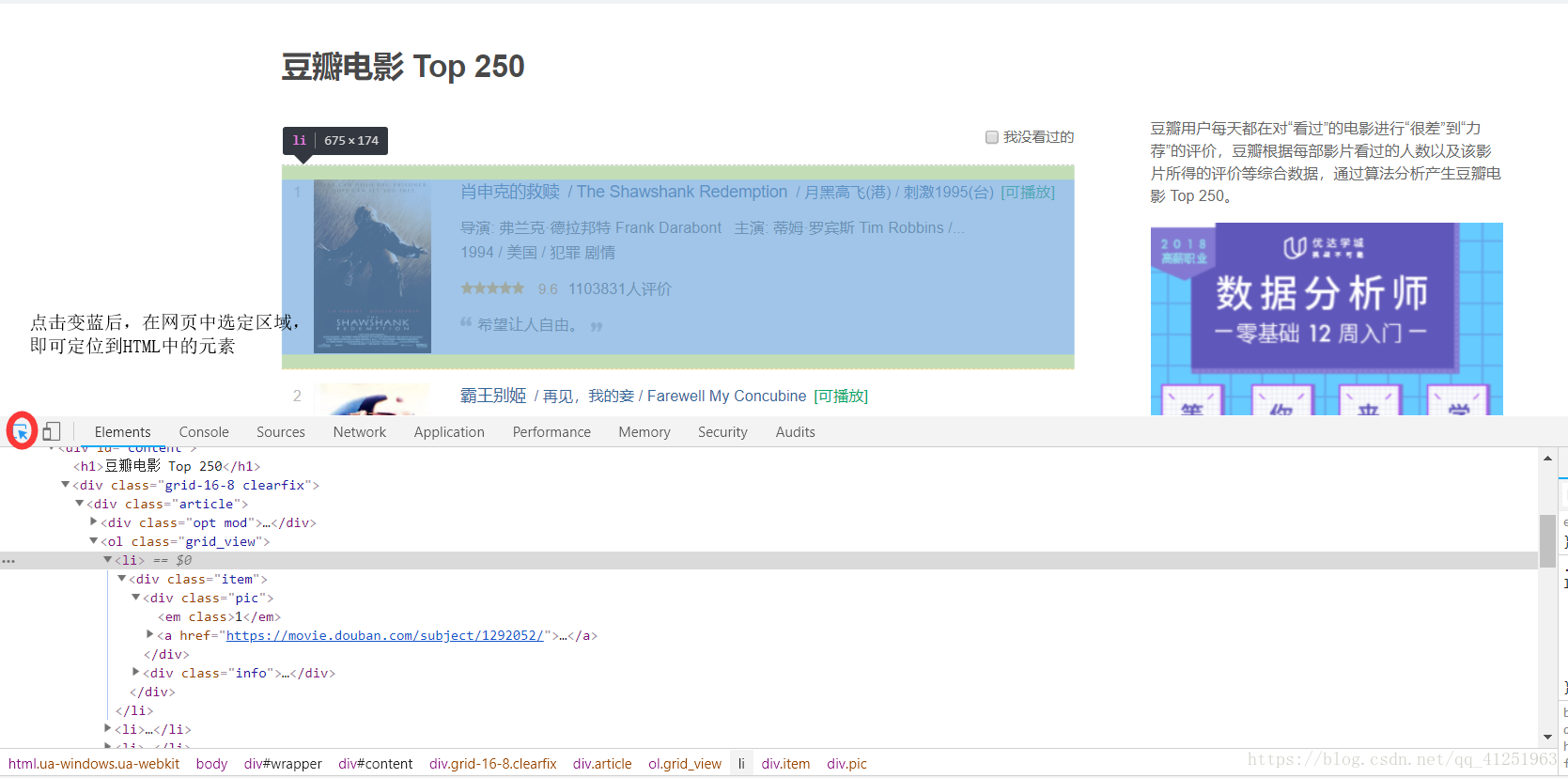
3.我們發現,網頁裡面有很多<li>...</li>標籤,而且每一個標籤裡面都有一個電影的資訊。我們想要的就是標籤裡面的文字資訊。
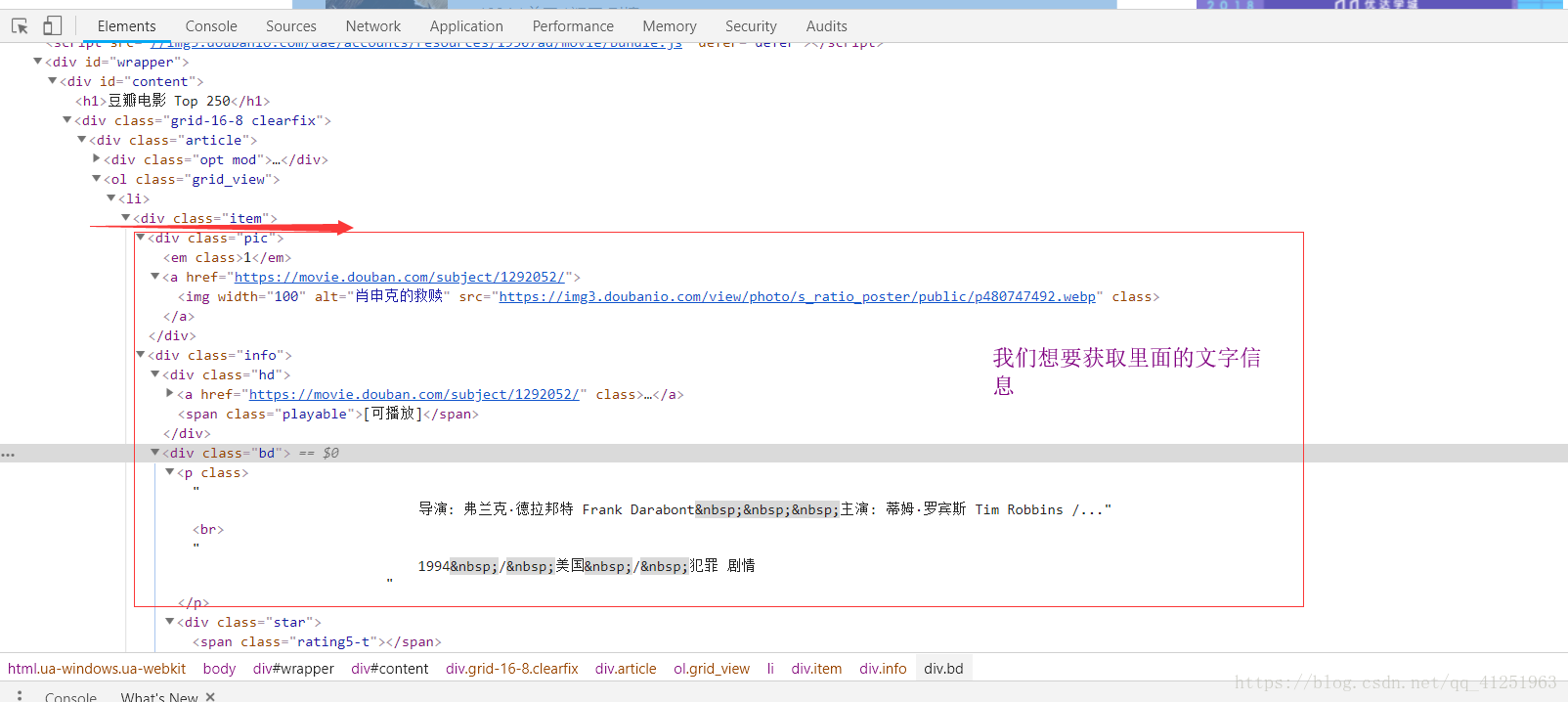
4.所有的資訊都在class屬性為info的div標籤裡,可以先把這個節點取出來 //*[@id=”content”]/div/div[1]/ol
這裡我們介紹一下xpath的語法格式:
XPath 使用路徑表示式在 XML 文件中選取節點。節點是通過沿著路徑或者 step 來選取的。
下面列出了最有用的路徑表示式:
| 表示式 | 描述 |
|---|---|
| nodename | 選取此節點的所有子節點。 |
| / | 從根節點選取。 |
| // | 從匹配選擇的當前節點選擇文件中的節點,而不考慮它們的位置。 |
| . | 選取當前節點。 |
| .. | 選取當前節點的父節點。 |
| @ | 選取屬性。 |
使用例項
| 路徑表示式 | 結果 |
|---|---|
| /bookstore/book[1] | 選取屬於 bookstore 子元素的第一個 book 元素。 |
| /bookstore/book[last()] | 選取屬於 bookstore 子元素的最後一個 book 元素。 |
| /bookstore/book[last()-1] | 選取屬於 bookstore 子元素的倒數第二個 book 元素。 |
| /bookstore/book[position()<3] | 選取最前面的兩個屬於 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 選取所有擁有名為 lang 的屬性的 title 元素。 |
| //title[@lang=’eng’] | 選取所有 title 元素,且這些元素擁有值為 eng 的 lang 屬性。 |
| /bookstore/book[price>35.00] | 選取 bookstore 元素的所有 book 元素,且其中的 price 元素的值須大於 35.00。 |
| /bookstore/book[price>35.00]/title | 選取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值須大於 35.00。 |
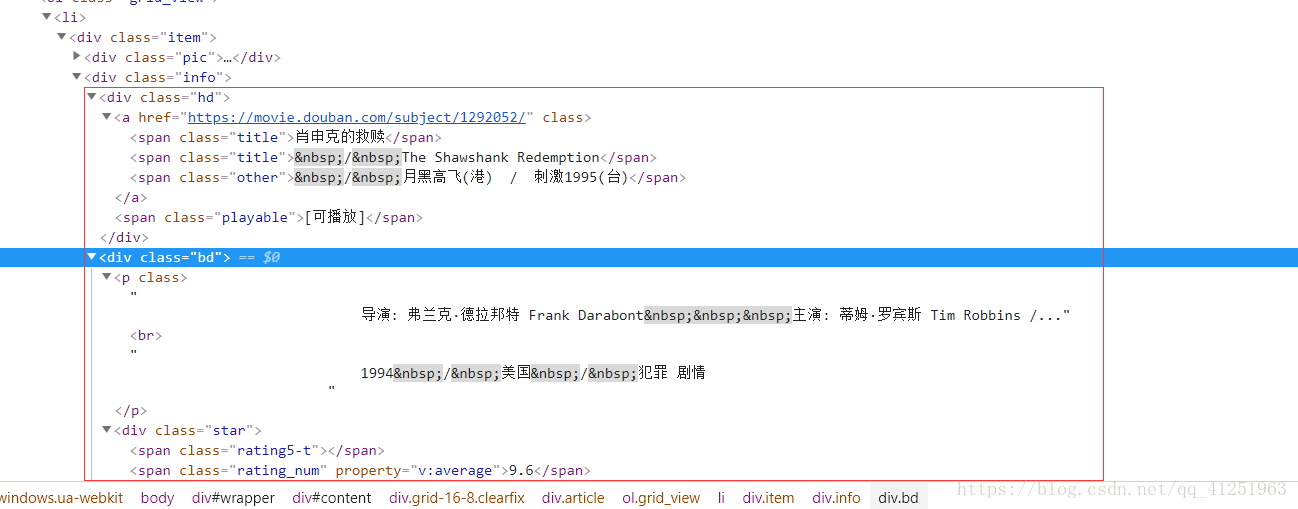
5.知道xpath的用法後,我們就可以輕鬆的拿到我們想要的資訊了!!!
影片名稱 :title = i.xpath('div[@class="hd"]/a/span[@class="title"]/text()')[0]
導演演員資訊:info = i.xpath('div[@class="bd"]/p[1]/text()')
評分:rate = i.xpath('//span[@class="rating_num"]/text()')[0]
評論人數:comCount = i.xpath('//div[@class="star"]/span[4]/text()')[0]
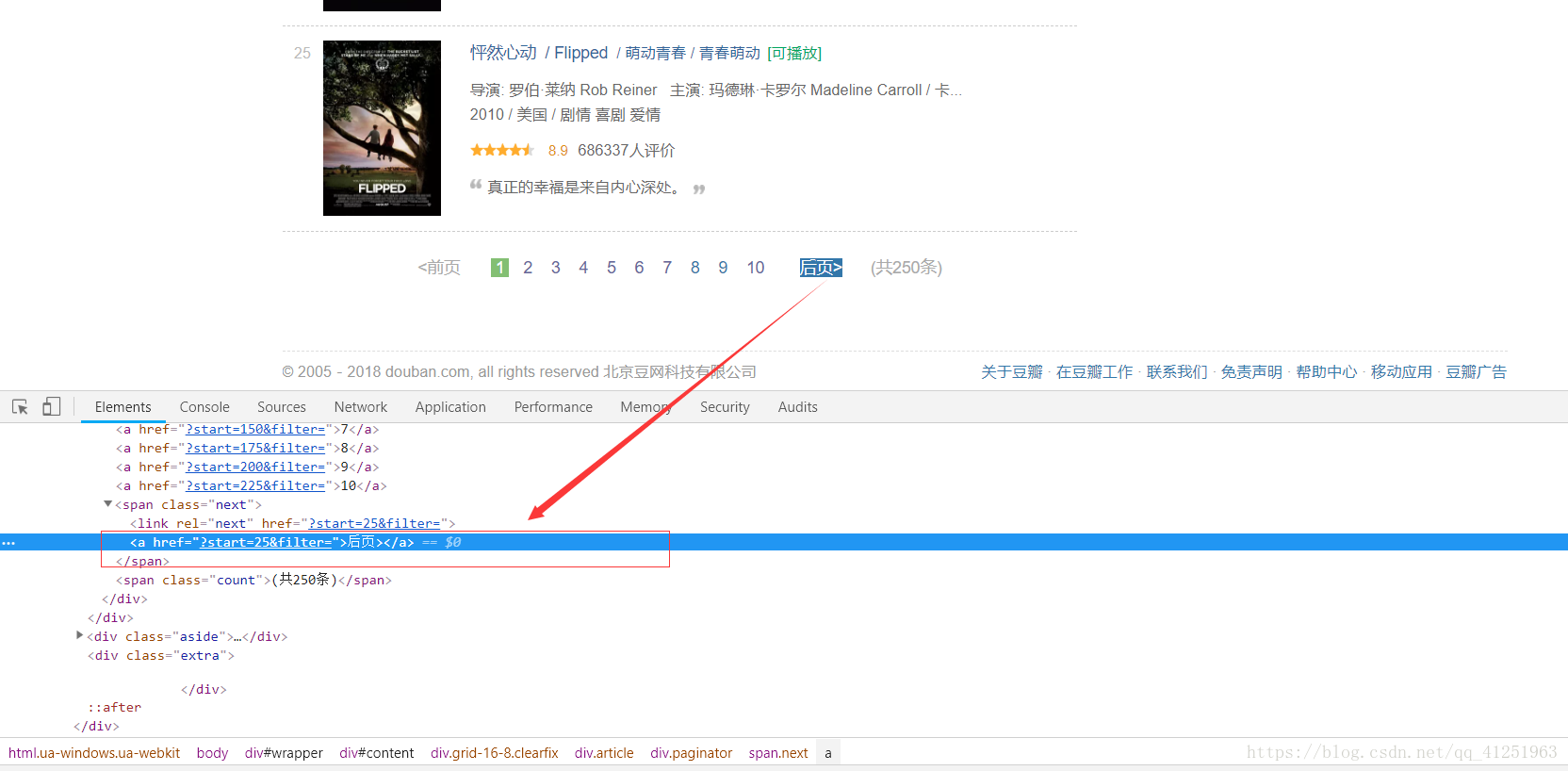
6.已經知道如何獲取電影資訊了,現在的任務是找到請求網址,我們可以翻頁尋找網址的規律,看看第二頁,第三頁……網址是什麼樣的。
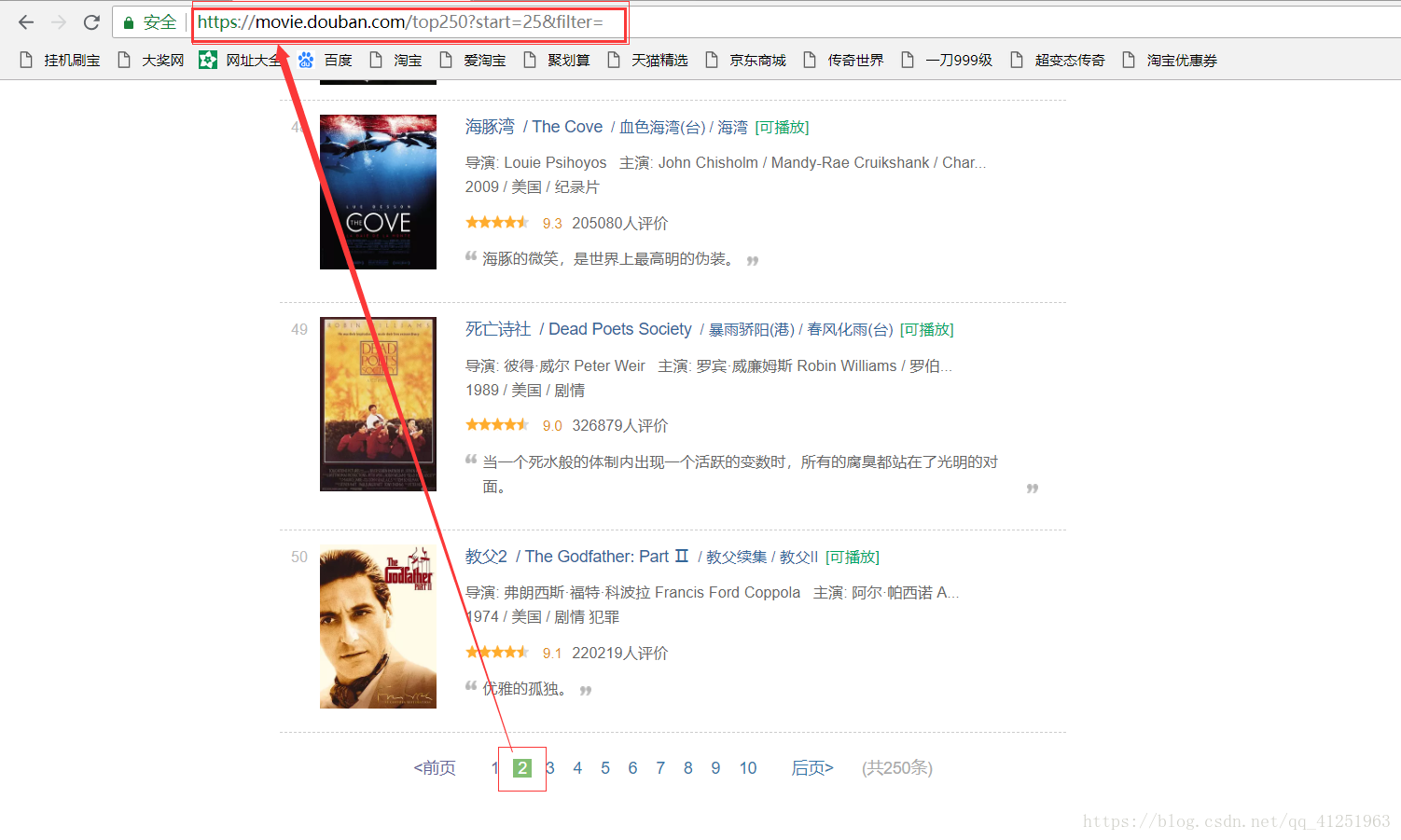
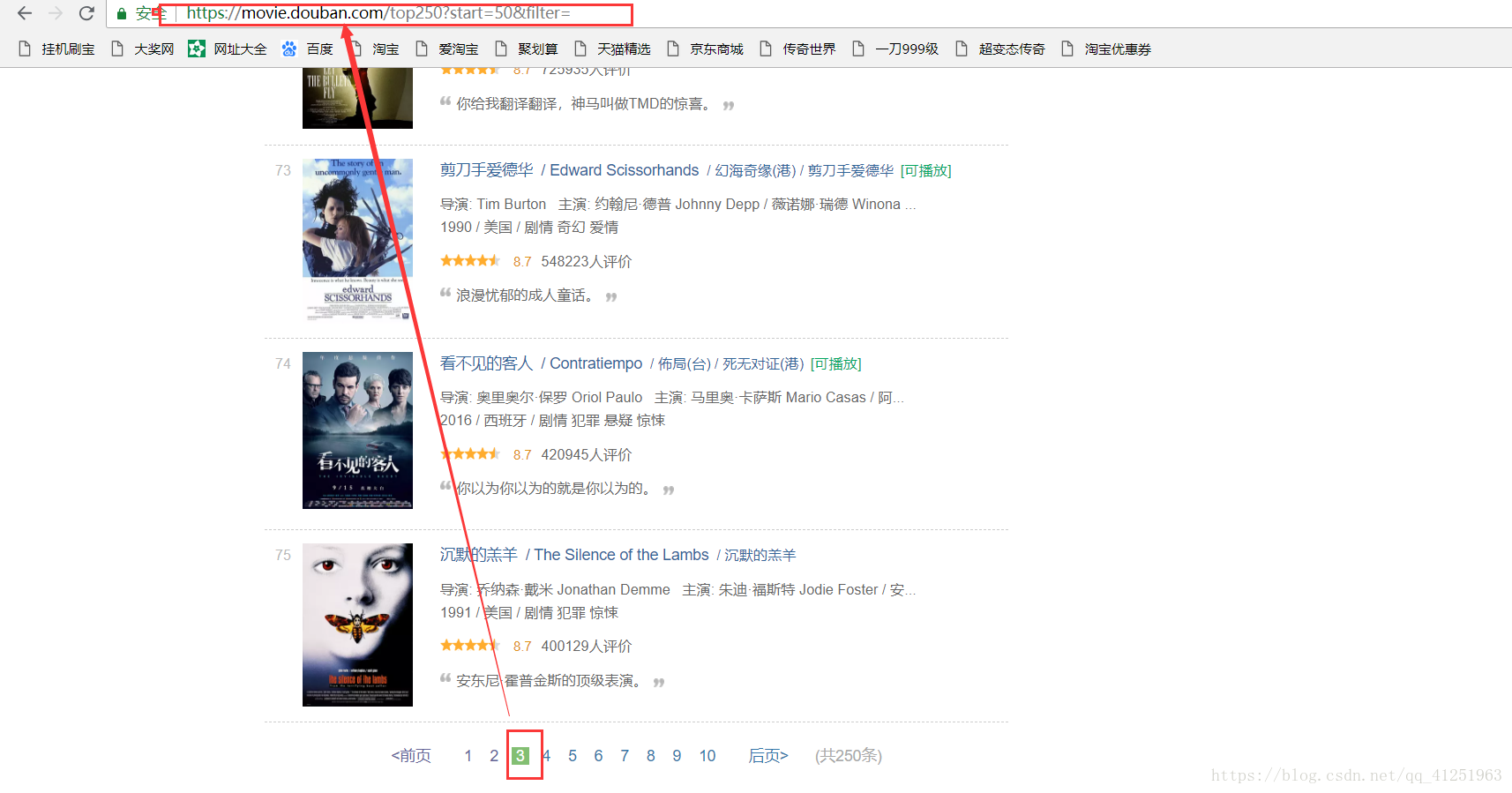
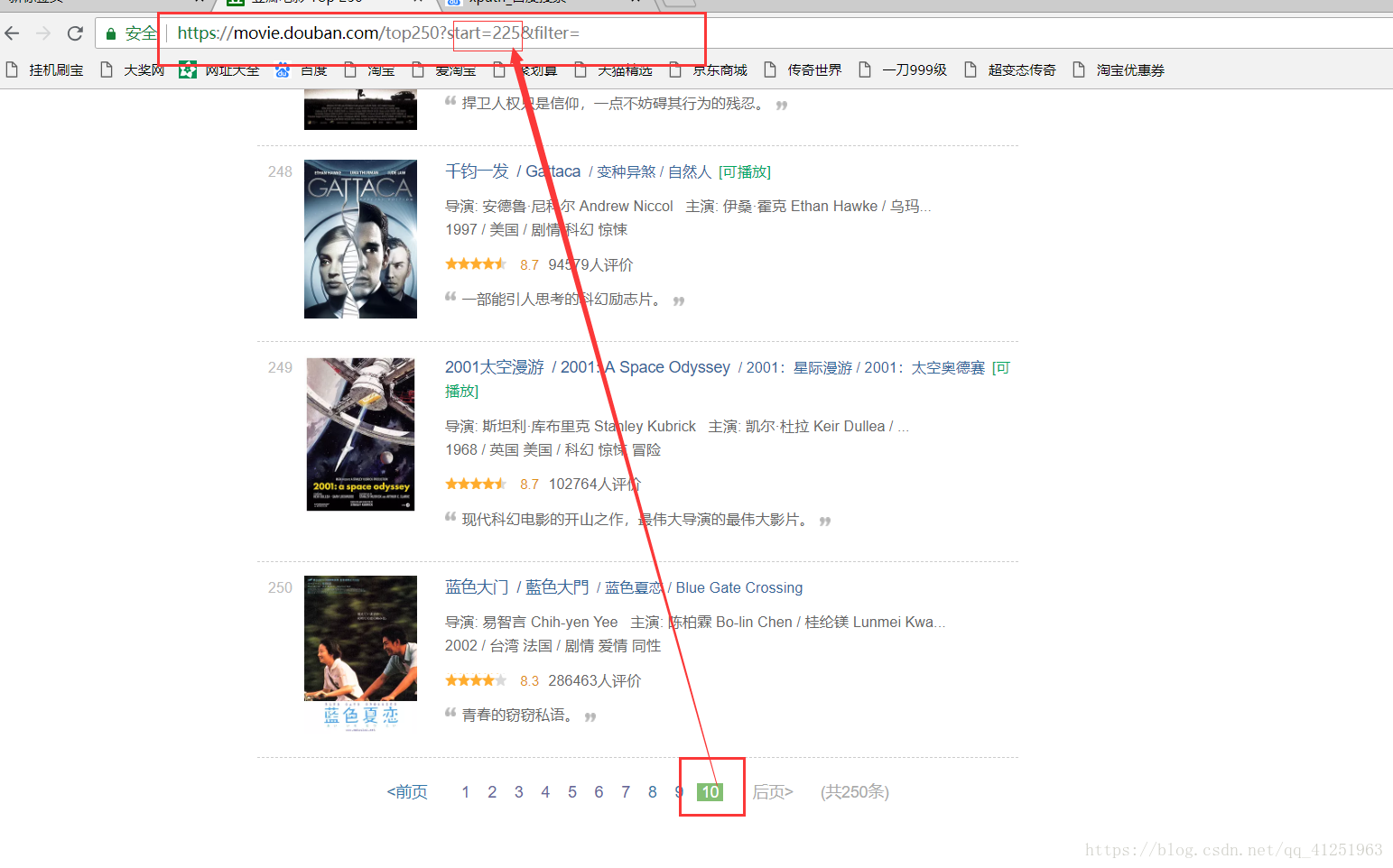
不難發現規律,只是每頁網址的start=發生變化。我們可以使用for迴圈來請求每頁網址,
for i in range(10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(i*25)除此之外,我們也可利用xpath獲取後頁的連結(//div[@class=”paginator”]/span[@class=”next”]/a/@href),與‘https://movie.douban.com/top250’拼接,同樣可以獲取下一頁地址。
完整程式碼
# coding:utf-8
import requests
from lxml import html
k = 1
for i in range(10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(i*25)
con = requests.get(url).content
sel = html.fromstring(con)
# 所有的資訊都在class屬性為info的div標籤裡,可以先把這個節點取出來 //*[@id="content"]/div/div[1]/ol
for i in sel.xpath('//div[@class="info"]'):
# 影片名稱
title = i.xpath('div[@class="hd"]/a/span[@class="title"]/text()')[0]
#print(title)
info = i.xpath('div[@class="bd"]/p[1]/text()')
# 導演演員資訊
info_1 = info[0].replace(" ", "").replace("\n", "")
# 上映日期
date = info[1].replace(" ", "").replace("\n", "").split("/")[0]
# 製片國家
country = info[1].replace(" ", "").replace("\n", "").split("/")[1]
# 影片型別
geners = info[1].replace(" ", "").replace("\n", "").split("/")[2]
# 評分
rate = i.xpath('//span[@class="rating_num"]/text()')[0]
# 評論人數
comCount = i.xpath('//div[@class="star"]/span[4]/text()')[0]
# 列印結果看看
print ("TOP%s" % str(k))
print( title, info_1, rate, date, country, geners, comCount )
# 寫入檔案
with open("top250.txt", "a",encoding='utf-8') as f:
f.write("TOP%s\n影片名稱:%s\n評分:%s %s\n上映日期:%s\n上映國家:%s\n%s\n" % (k, title, rate, comCount, date, country, info_1))
f.write("==========================\n")
k += 1擴充套件
將爬取的資料存入Mysql資料庫
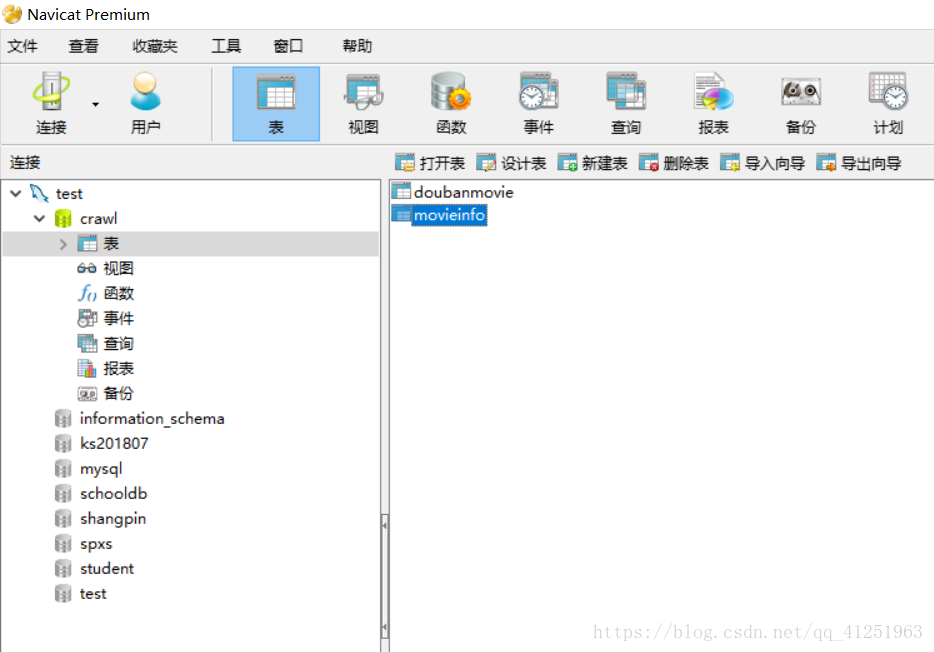
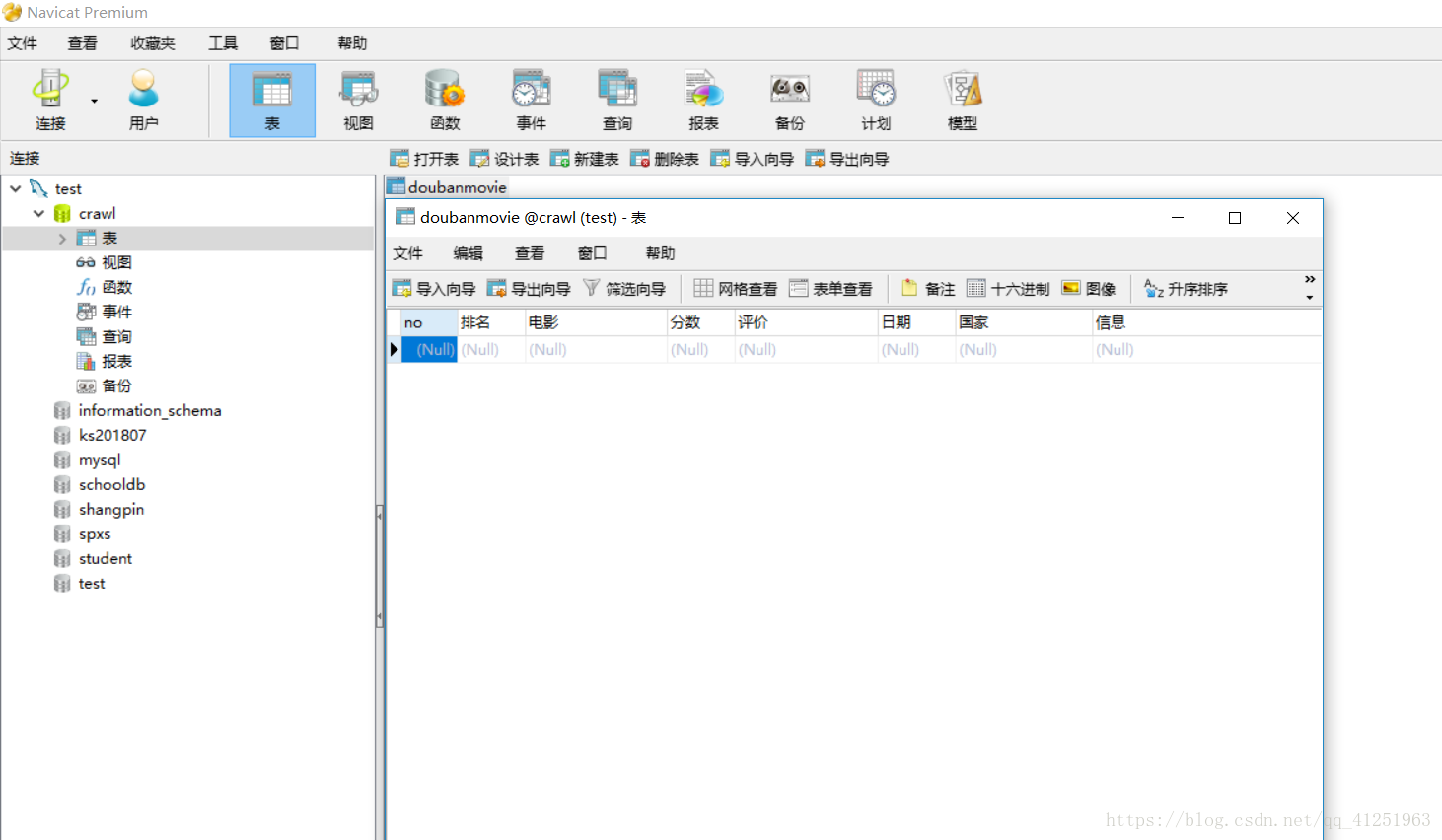
1.新建資料庫crawl,並在資料庫crawl中新建表doubanmovie,所建表如圖所示。
2.對上面的程式碼稍作修改,將存取到TXT文件改為資料庫,完整程式碼如下:
# coding:utf-8
import requests
import pymysql
from lxml import html
k = 1
for i in range(10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(i*25)
con = requests.get(url).content
sel = html.fromstring(con)
# 所有的資訊都在class屬性為info的div標籤裡,可以先把這個節點取出來 //*[@id="content"]/div/div[1]/ol
for i in sel.xpath('//div[@class="info"]'):
# 影片名稱
title = i.xpath('div[@class="hd"]/a/span[@class="title"]/text()')[0]
#print(title)
info = i.xpath('div[@class="bd"]/p[1]/text()')
# 導演演員資訊
info_1 = info[0].replace(" ", "").replace("\n", "")
# 上映日期
date = info[1].replace(" ", "").replace("\n", "").split("/")[0]
# 製片國家
country = info[1].replace(" ", "").replace("\n", "").split("/")[1]
# 影片型別
geners = info[1].replace(" ", "").replace("\n", "").split("/")[2]
# 評分
rate = i.xpath('//span[@class="rating_num"]/text()')[0]
# 評論人數
comCount = i.xpath('//div[@class="star"]/span[4]/text()')[0]
# 列印結果看看
print ("TOP%s" % str(k))
print( title, info_1, rate, date, country, geners, comCount )
connection=''
try:
# 獲取一個有效的資料庫連線物件,此處填寫你的資料庫資訊,特別注意charset一定要寫成'utf8',不能寫成'utf-8'。
connection = pymysql.connect(host='localhost', port=3306,
user='root', password='mysql',
db='crawl', charset='utf8')
if connection:
print("[mysql]>>正確獲取資料庫的連線物件")
# 建立一個遊標物件
curosr = connection.cursor()
print('[mysql]正確獲取遊標物件')
# 設定插入資料的sql語句模板
sql = "insert into doubanmovie VALUES (null,'%d','%s','%s,','%s','%s','%s','%s')" % (k, title, rate, comCount, date, country, info_1)
print('[mysql]>>%s' % sql)
# 使用遊標物件傳送sql語句並將伺服器結果返回
affectedRows = curosr.execute(sql)
msg = '[mysql]>>寫入操作成功' if affectedRows > 0 else '[mysql]>>寫入失敗'
print(msg)
# 事務提交
connection.commit()
print("[mysql]>>事務提交")
except:
connection.rollback()
print('[mysql]事務回滾')
finally:
# 關閉資料庫連線
connection.close()
print("[mysql]>>關閉資料庫連線")
k += 1注意事項及功能均在程式碼註釋中。
執行結果如圖:
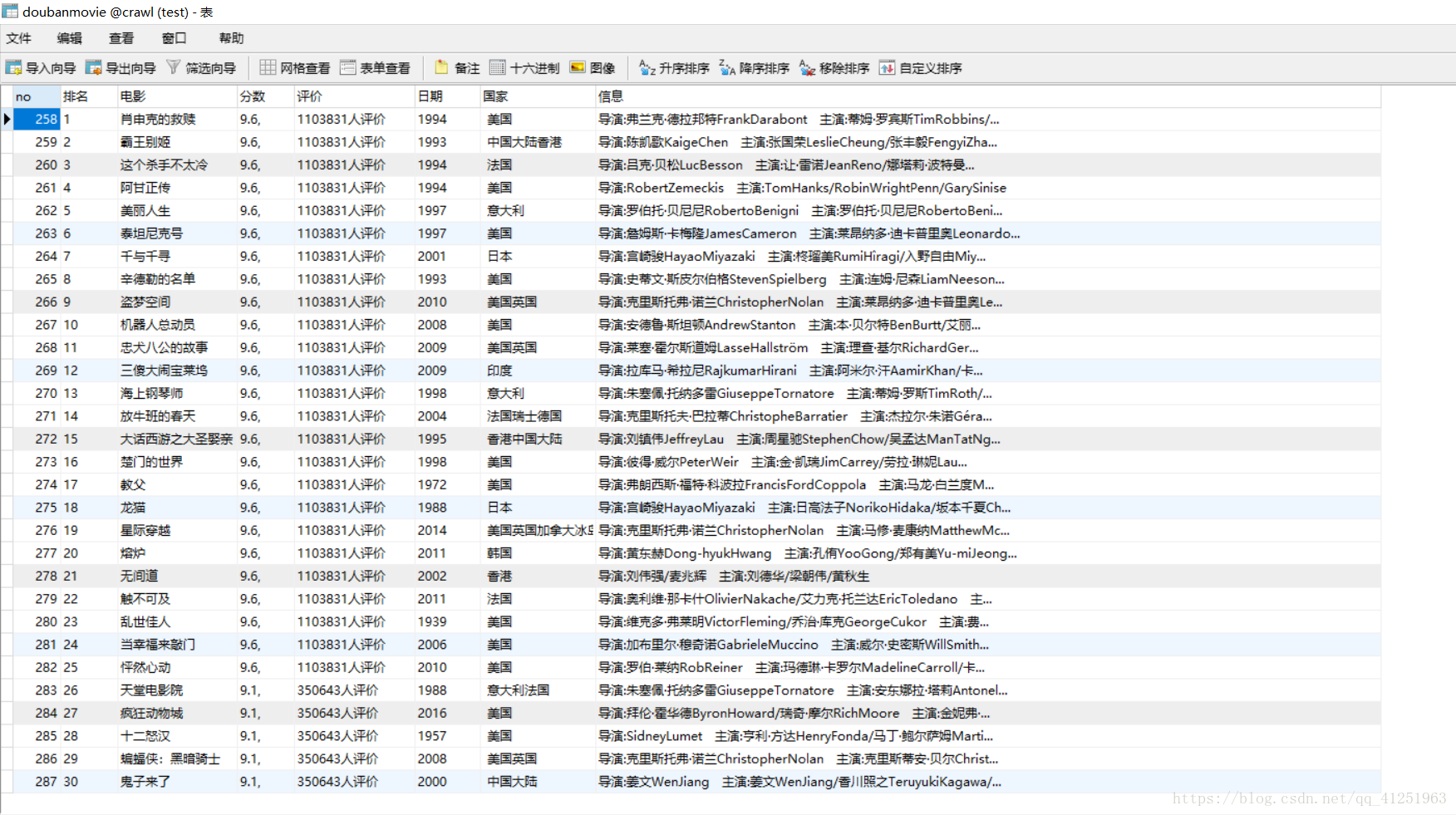
如圖已將所有資訊存入到資料庫中!
相關推薦
python爬蟲——豆瓣電影Top250
主要功能 1.利用lxml爬取豆瓣電影top250https://movie.douban.com/top250 2.用xpath確定所爬取資料的位置 3.獲取資料,將資料寫到txt文件中儲存 實現步驟 1.網頁分析,進入網站(本文使用的是谷歌瀏覽器)
Python爬蟲-豆瓣電影 Top 250
EDA esc std app data raise 打開網頁 正則表達 sta 爬取的網頁地址為:https://movie.douban.com/top250 打開網頁後,可觀察到:TOP250的電影被分成了10個頁面來展示,每個頁面有25個電影。 那麽要爬取所有電影
Python3爬蟲豆瓣電影TOP250將電影名寫入到EXCEL
大家好,我是你們的老朋友澤哥,最近在學習Python3.6,於是興起寫了個小小的爬蟲 附上截圖! 我們要獲得TOP250對應的電影名,開啟F12對HTML報文進行解讀 電影名對應的HTML程式碼如下: <span class="title">肖申克的
用Python分析豆瓣電影Top250
開場白:本文中使用的語言為 Python 3 ,其中主要用了 BeautifulSoup、Numpy、Pandas、Matplotlib和WordCloud 等幾個資料分析常用庫,過程儘量寫的詳(luo)細(suo)些,希望能給和我一樣的資料分析初學者一些思路,
python爬蟲練習1:豆瓣電影TOP250
import ria fff python top font beautiful code pen 項目1:實現豆瓣電影TOP250標題爬取: 1 from urllib.request import urlopen 2 from bs4 import Beaut
案例學python——案例三:豆瓣電影資訊入庫 一起學爬蟲——通過爬取豆瓣電影top250學習requests庫的使用
閒扯皮 昨晚給高中的妹妹微信講題,函式題,小姑娘都十二點了還迷迷糊糊。今天凌晨三點多,被連續的警報聲給驚醒了,以為上海拉了防空警報,難不成地震,空襲?難道是樓下那個車主車子被堵了,長按喇叭?開窗看看,好像都不是。好鬼畜的警報聲,家裡也沒裝報警器啊,莫不成家裡煤氣漏了?起床循聲而查,報警
零基礎Python爬蟲實戰:豆瓣電影TOP250
我們曾經抓取過貓眼電影TOP100,並進行了簡單的分析。但是眾所周知,豆瓣的使用者比較小眾、比較獨特,那麼豆瓣的TOP250又會是哪些電影呢? 我在整理程式碼的時候突然發現一年多以前的爬蟲程式碼竟然還能使用……那今天就用它來演示下,如何通過urllib+BeautifulSoup來快
python實踐2——利用爬蟲抓取豆瓣電影TOP250資料及存入資料到MySQL資料庫
這次以豆瓣電影TOP250網為例編寫一個爬蟲程式,並將爬取到的資料(排名、電影名和電影海報網址)存入MySQL資料庫中。下面是完整程式碼:Ps:在執行程式前,先在MySQL中建立一個數據庫"pachong"。import pymysql import requests imp
(7)Python爬蟲——爬取豆瓣電影Top250
利用python爬取豆瓣電影Top250的相關資訊,包括電影詳情連結,圖片連結,影片中文名,影片外國名,評分,評價數,概況,導演,主演,年份,地區,類別這12項內容,然後將爬取的資訊寫入Excel表中。基本上爬取結果還是挺好的。具體程式碼如下: #!/us
[Python/爬蟲]利用xpath爬取豆瓣電影top250
今天學習了一下xpath 感覺功能非常的強大,但是如果不太懂前端的小夥伴們可能比較吃力,建議看一下html的一些語法結構,程式碼如下: #!/usr/bin/env python import r
python爬蟲——爬取豆瓣電影top250資訊並載入到MongoDB資料庫中
最近在學習關於爬蟲方面的知識,因為剛開始接觸,還是萌新,所以有什麼錯誤的地方,歡迎大家指出 from multiprocessing import Pool from urllib.request import Request, urlopen import re, pymongo index
Python爬蟲小案例:豆瓣電影TOP250
原始碼: #!/usr/bin/python3 # -*-coding: UTF-8-*- from urllib import request import re class MovieTop250(object): def __init
python爬蟲(一)爬取豆瓣電影Top250
提示:完整程式碼附在文末 一、需要的庫 requests:獲得網頁請求 BeautifulSoup:處理資料,獲得所需要的資料 二、爬取豆瓣電影Top250 爬取內容為:豆瓣評分前二百五位電影的名字、主演、
【Python爬蟲】Scrapy框架運用1—爬取豆瓣電影top250的電影資訊(1)
一、Step step1: 建立工程專案 1.1建立Scrapy工程專案 E:\>scrapy startproject 工程專案 1.2使用Dos指令檢視工程資料夾結構 E:\>tree /f step2: 建立spid
初學python:用簡單的爬蟲爬取豆瓣電影TOP250的排名
一開始接觸到python語言,對它沒什麼瞭解。唯一知道的就是它可以用來寫爬蟲,去爬取網路上的資源。爬蟲是一種按照一定的規則,自動地抓取網路上的資訊的程式或者指令碼。所以當我對python有一定的瞭解後,我就想個寫個爬蟲來試試手。於是就有了這篇文章,用簡單的爬蟲爬取豆瓣電影TO
Python網路爬蟲:利用正則表示式爬取豆瓣電影top250排行前10頁電影資訊
在學習了幾個常用的爬取包方法後,轉入爬取實戰。 爬取豆瓣電影早已是練習爬取的常用方式了,網上各種程式碼也已經很多了,我可能現在還在做這個都太土了,不過沒事,畢竟我也才剛入門…… 這次我還是利用正則表示式進行爬取,怎麼說呢,有人說寫正則表示式很麻煩,很多人都不
【Python】從0開始寫爬蟲——豆瓣電影
for tag pes wing 信息 kit headers 自動 動畫 1. 最近略忙。。java在搞soap,之前是用工具自動生成代碼的。最近可能會寫一個soap的java調用 2. 這個豆瓣電影的爬蟲。扒信息的部分暫時先做到這了。扒到的信息如下 from s
python抓取豆瓣電影top250資訊
1、本博文中程式碼是轉載內容,原文章地址如下: https://blog.csdn.net/submit66/article/details/78631342?utm_source=blogxgwz1 2、只是在原文程式碼的基礎上稍作修改,添加了一些註釋及無關緊要的程式碼 3、本
python爬取豆瓣電影Top250的資訊
python爬取豆瓣電影Top250的資訊 2018年07月25日 20:03:14 呢喃無音 閱讀數:50 python爬取豆瓣電影Top250的資訊。 初學,所以程式碼的不夠美觀和精煉。 如果程式碼有錯,請各位讀者在評論區評論,以免誤導其他同學。 (
一起學爬蟲——通過爬取豆瓣電影top250學習requests庫的使用
學習一門技術最快的方式是做專案,在做專案的過程中對相關的技術查漏補缺。 本文通過爬取豆瓣top250電影學習python requests的使用。 1、準備工作 在pycharm中安裝request庫 請看上圖,在pycharm中依次點選:File->Settings。然後會彈出下圖的介面: 點選2