
MySQL和Lucene索引對比分析
MySQL和Lucene都可以對資料構建索引並通過索引查詢資料,一個是關係型資料庫,一個是構建搜尋引擎(Solr、ElasticSearch)的核心類庫。兩者的索引(index)有什麼區別呢?以前寫過一篇《Solr與MySQL查詢效能對比》,只是簡單的對比了下查詢效能,對於內部原理卻沒有解釋,本文簡單分析下兩者的索引區別。
MySQL索引實現
在MySQL中,索引屬於儲存引擎級別的概念,不同儲存引擎對索引的實現方式是不同的,本文主要討論MyISAM和InnoDB兩個儲存引擎的索引實現方式。
MyISAM索引實現
MyISAM引擎使用B+Tree作為索引結構,葉節點的data域存放的是資料記錄的地址。下圖是MyISAM索引的原理圖:

圖1是一個MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引檔案僅僅儲存資料記錄的地址。在MyISAM中,主索引和輔助索引(Secondary key)在結構上沒有任何區別,只是主索引要求key是唯一的,而輔助索引的key可以重複。B+Tree的所有葉子節點包含所有關鍵字且是按照升序排列的。
MyISAM表的索引和資料是分離的,索引儲存在”表名.MYI”檔案內,而資料儲存在“表名.MYD”檔案內。
MyISAM的索引方式也叫做“非聚集”的,之所以這麼稱呼是為了與InnoDB的聚集索引區分。
InnoDB索引實現
雖然InnoDB也使用B+Tree作為索引結構,但具體實現方式卻與MyISAM截然不同。
第一個重大區別是InnoDB的資料檔案本身就是索引檔案。從上文知道,MyISAM索引檔案和資料檔案是分離的,索引檔案僅儲存資料記錄的地址。而在InnoDB中,表資料檔案本身就是按B+Tree組織的一個索引結構,這棵樹的葉節點data域儲存了完整的資料記錄。這個索引的key是資料表的主鍵,因此InnoDB表資料檔案本身就是主索引。
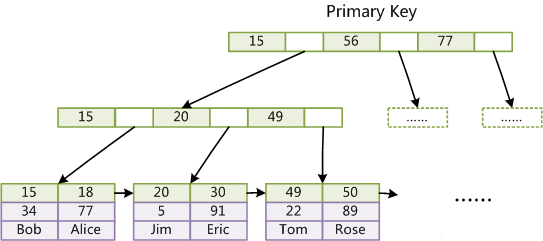
圖2是InnoDB主索引(同時也是資料檔案)的示意圖,可以看到葉節點包含了完整的資料記錄。這種索引叫做聚集索引。因為InnoDB的資料檔案本身要按主鍵聚集,所以InnoDB要求表必須有主鍵(MyISAM可以沒有),如果沒有顯式指定,則MySQL系統會自動選擇一個可以唯一標識資料記錄的列作為主鍵,如果不存在這種列,則MySQL自動為InnoDB表生成一個隱含欄位作為主鍵,這個欄位長度為6個位元組,型別為長整形。
第二個與MyISAM索引的不同是InnoDB的輔助索引data域儲存相應記錄主鍵的值而不是地址。換句話說,InnoDB的所有輔助索引都引用主鍵作為data域。例如,圖3為定義在Col3上的一個輔助索引:
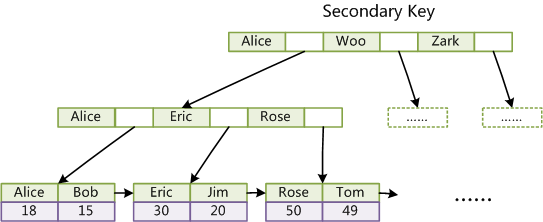
這裡以英文字元的ASCII碼作為比較準則。聚集索引這種實現方式使得按主鍵的搜尋十分高效,但是輔助索引搜尋需要檢索兩遍索引:首先檢索輔助索引獲得主鍵,然後用主鍵到主索引中檢索獲得記錄。
瞭解不同儲存引擎的索引實現方式對於正確使用和優化索引都非常有幫助,例如知道了InnoDB的索引實現後,就很容易明白為什麼不建議使用過長的欄位作為主鍵,因為所有輔助索引都引用主索引,過長的主索引會令輔助索引變得過大。再例如,用非單調的欄位作為主鍵在InnoDB中不是個好主意,因為InnoDB資料檔案本身是一顆B+Tree,非單調的主鍵會造成在插入新記錄時資料檔案為了維持B+Tree的特性而頻繁的分裂調整,十分低效,而使用自增欄位作為主鍵則是一個很好的選擇。
講MySQL索引的實現的文章很多,以上也是參考了《MySQL索引背後的資料結構及演算法原理》,現在來看看Lucene的索引原理。
Lucene索引實現
Lucene的索引不是B+Tree組織的,而是倒排索引,Lucene的倒排索引由Term index,Team Dictionary和Posting List組成。

有倒排索引(invertedindex)就有正排索引(forwardindex),正排索引就是文件(Document)和它的欄位Fields正向對應的關係:
|
DocID |
name |
sex |
age |
|
1 |
jack |
男 |
18 |
|
2 |
lucy |
女 |
17 |
|
3 |
peter |
男 |
17 |
倒排索引是欄位Field和擁有這個Field的文件對應的關係:
Sex欄位:
|
男 |
[1,3] |
|
女 |
[2] |
Age欄位:
|
18 |
[1] |
|
17 |
[2,3] |
Jack,lucy或者17,18這些叫做term,而[1,3]就是posting list。Posting list就是一個int型的陣列,儲存了所有符合某個term的文件id。那麼什麼是Term index和Term dictionary?
如上,假設name欄位有很多個term,比如:Carla,Sara,Elin,Ada,Patty,Kate,Selena
如果按照這樣的順序排列,找出某個特定的term一定很慢,因為term沒有排序,需要全部過濾一遍才能找出特定的term。排序之後就變成了:Ada,Carla,Elin,Kate,Patty,Sara,Selena
這樣就可以用二分查詢的方式,比全遍歷更快地找出目標的term。如何組織這些term的方式就是 Term dictionary,意思就是term的字典。有了Term dictionary之後,就可以用比較少的比較次數和磁碟讀次數查詢目標。但是磁碟的隨機讀操作仍然是非常昂貴的,所以儘量少的讀磁碟,有必要把一些資料快取到記憶體裡。但是整個Term dictionary本身又太大了,無法完整地放到記憶體裡。於是就有了Term index。Term index有點像一本字典的大的章節表。比如:
A開頭的term ……………. Xxx頁
C開頭的term ……………. Xxx頁
E開頭的term ……………. Xxx頁
如果所有的term都是英文字元的話,可能這個term index就真的是26個英文字元表構成的了。但是實際的情況是,term未必都是英文字元,term可以是任意的byte陣列。而且26個英文字元也未必是每一個字元都有均等的term,比如x字元開頭的term可能一個都沒有,而s開頭的term又特別多。實際的term index是一棵trie 樹:

上圖例子是一個包含 "A", "to", "tea", "ted", "ten", "i", "in", 和 "inn" 的trie樹。這棵樹不會包含所有的term,它包含的是term的一些字首。通過term index可以快速地定位到term dictionary的某個offset,然後從這個位置再往後順序查詢。再加上一些壓縮技術(想了解更多,搜尋 Lucene Finite State Transducers),Term index的尺寸可以只有所有term的尺寸的幾十分之一,使得用記憶體快取整個term index變成可能。整體上來說就是這樣的效果:

由Term index到Term Dictionary,再到Posting List,通過某個欄位的關鍵字去查詢結果的過程就比較清楚了,通過多個關鍵字的Posting List進行AND或者OR進行交集或者並集的查詢也簡單了。
對比MySQL的B+Tree索引原理,可以發現:
1)Lucene的Term index和Term Dictionary其實對應的就是MySQL的B+Tree的功能,為關鍵字key提供索引。Lucene的inverted index可以比MySQL的b-tree檢索更快。
2)Term index在記憶體中是以FST(finite state transducers)的形式儲存的,其特點是非常節省記憶體。所以Lucene搜尋一個關鍵字key的速度是非常快的,而MySQL的B+Tree需要讀磁碟比較。
3)Term dictionary在磁碟上是以分block的方式儲存的,一個block內部利用公共字首壓縮,比如都是Ab開頭的單詞就可以把Ab省去。這樣Term dictionary可以比B-tree更節約磁碟空間。
4)Lucene對不同的資料型別採用了不同的索引方式,上面分析是針對field為字串的,比如針對int,有TrieIntField型別,針對經緯度,就可以用GeoHash編碼。
5)在 Mysql中給兩個欄位獨立建立的索引無法聯合起來使用,必須對聯合查詢的場景建立複合索引,而Lucene可以任何AND或者OR組合使用索引進行檢索。
參考:
http://stackoverflow.com/questions/4628571/solr-date-field-tdate-vs-date
http://lucene.apache.org/core/
相關推薦
MySQL和Lucene索引對比分析
MySQL和Lucene都可以對資料構建索引並通過索引查詢資料,一個是關係型資料庫,一個是構建搜尋引擎(Solr、ElasticSearch)的核心類庫。兩者的索引(index)有什麼區別呢?以前寫過一篇《Solr與MySQL查詢效能對比》,只是簡單的對比了下查詢效能,對於內部原理卻沒有解釋,本文簡單分析下兩
Mysql和MongoDB效能對比及應用場景分析
一、前言 為什麼調研MongoDB? 下圖是DB-Engines2017年8月資料庫的排名統計,可以看到MongoDB總排名在第5,在Nosql資料庫中排名第1。 優點: 1)社群活躍,使用者較多,應用廣泛。 2)MongoDB在記憶體充足
java中的類鎖和物件鎖對比分析
說到鎖機制,不得不提到Thread執行緒,而又不得不提到synchronized關鍵字,這個單詞的意思是表示“同步”的意思。用它去修飾方法函式的時候,如果有多個執行緒同時呼叫這個方法函式的時候,那麼當一個執行緒獲得鎖的時候,其他的執行緒只
Java中抽象類和介面的對比分析
abstract class在Java語言中表示的是一種繼承關係,一個類只能使用一次繼承關係。但是,一個類卻可以實現多個interface。 在abstract class中可以有自己的資料成員,也可以有非abstarct的成員方法,而在interface中,只能夠有靜態的
更適合物聯網的邊緣計算,可能只是投機者的一塊雞肋 (雲端計算和邊緣計算對比分析)
摘要: 物聯網又迎來了新風口,但這個風口咬下去可能沒多少肉。 圖片來源 © 視覺中國 前沿科技產業的一個特點,就是總會給大家制造出各種各樣的風口。這些風口往往有著特別酷炫的名字,有強大的學術論證和巨頭背書,但真正落實到應用性和商業行為當中,結果怎麼樣又不好說了。 比
Mysql學習-04 索引優化分析--查詢優化
索引的規則: 1.索引失效情況 <1>全值匹配我最愛 建立索引提高效率 CREATE INDEX 索引名字 ON 表名(表字段,表字段,表字段,......) 建立索引前:
【mpeg2】mpeg1、mpeg2和mpeg4標準對比分析和總結
Date: 2018.11.2 mpeg1、mpeg2和mpeg4標準對比 0、參考 1、編解碼流程 MPEG-1標準主要採用基於插值的運動補償預測+DCT+量化+VLC熵編碼的技術;MPEG-2標準在MPEG-1的基礎上增加了Scan過程並且碼
Mysql學習-03 索引優化分析--效能分析
效能分析 -->Explain工具: 執行計劃 使用EXPLAIN關鍵字可以模擬優化器執行SQL查詢語句,從而知道MySQL是如何處理你的SQL語句的。分析你的查詢語句或是表結構的效能瓶頸。 2.用途 表的讀取順
從MySQL和MongoDB的對比,看SQL與NoSQL的較量
作者介紹 張家江,網易樂得高階工程師。 貴金屬(注:貴金屬為筆者部門業務)的行情繫統提供的介面通過Redis獲取資料,目前使用Redis最多隻儲存了大概8000條左右的分鐘k的行情資料,考慮到將來可能會有更大資料量的查詢需求,需要查詢幾月甚至幾年的行情資料,要求資料庫在提供功能的同時又能保證效能和穩
RecyclerView 和 ListView 使用對比分析(佈局、API、巢狀滾動機制)
空資料處理 ListView 提供了 setEmptyView 這個 API 來讓我們處理 Adapter 中資料為空的情況,只需輕輕一 set 就能搞定一切。程式碼設定和效果如下 mListView = (ListView) findViewById(R.id.listview);
Dijkstra演算法和Floyd演算法對比分析
首先,Dijkstra演算法與Floyd演算法都是廣度優先搜尋的演算法。都可以用來求單源點到其他所有點的最短路徑。那麼這兩者的原理分別是怎樣?彼此又有什麼區別呢?求此有向圖中起點1到其他所有點的最短距離在本文中,我們以一個小小的包含3個節點的有向圖和鄰接矩陣Graph來進行說
Cookie和Session的對比分析
巨集觀概括 1.Cookie和Session都是常用的會話跟蹤技術。 2.Session是在服務端儲存的一個數據結構,用來跟蹤使用者的狀態,這個資料可以儲存在叢集、資料庫、檔案中。 3.Cooki
Mysql 和 Postgresql(PGSQL) 對比
PostgreSQL由於是類似Oracle的多程序框架,所以能支援高併發的應用場景,這點與Oracle資料庫很像,所以把Oracle DBA轉到PostgreSQL資料庫 上是比較容易的,畢竟PostgreSQL資料庫與Oracle資料庫很相似。 同時,PostgreSQL資料庫的原始碼要比MySQL資
Lucene學習總結之四:Lucene索引過程分析
3、將文件加入IndexWriter 程式碼: writer.addDocument(doc); -->IndexWriter.addDocument(Document doc, Analyzer analyzer) -->doFlush = docWrite
Lucene學習總結之四:Lucene索引過程分析(1)
浪費了“黃金五年”的Java程式設計師,還有救嗎? >>>
MySQL查詢語句中的IN 和Exists 對比分析
In exists nested loop sql優化 查詢效率 背景介紹 最近在寫SQL語句時,對選擇IN 還是Exists 猶豫不決,於是把兩種方法的SQL都寫出來對比一下執行效率,發現IN的查詢效率比Exists高了很多,於是想當然的認為IN的效率比Exists好,但本著尋根究底的原
MySQL聚簇索引和非聚簇索引的對比
mage 自增 很多 拆分 .frm 性能 lock 兩個文件 inf 首先要清楚:聚簇索引並不是一種單獨的索引類型,而是一種存儲數據的方式。 聚簇索引在實際中用的很多,Innodb就是聚簇索引,Myisam 是非聚簇索引。 在之前我想插入一段關於innodb和myis
Mysql保持連線和每次重連--以及--迴圈提交和事務形式提交在插入時的耗時對比分析
前言: 在程式碼中考慮到不同的情況: 有時候希望資料庫保持連線,有時候希望在每次使用後斷開; 有時候希望以單條形式提交,有時候希望以事務提交; 有時候兩者皆可,糾結於此。 這裡給大家提供個人測試資料,以供參考: 測試條件: python pymsql 阿里
MySQL索引的原理,B+樹、聚集索引和二級索引的結構分析
索引是一種用於快速查詢行的資料結構,就像一本書的目錄就是一個索引,如果想在一本書中找到某個主題,一般會先找到對應頁碼。在mysql中,儲存引擎用類似的方法使用索引,先在索引中找到對應值,然後根據匹配的索引記錄找到對應的行。 我們首先了解一下索引的幾種型別和索引的結構。 索引型別 B樹 大多
MySQL單列索引和組合索引的選擇效率與explain分析
一、先闡述下單列索引和組合索引的概念: 單列索引:即一個索引只包含單個列,一個表可以有多個單列索引,但這不是組合索引。 組合索引:即一個索包含多個列。 如果我們的查詢where條件只有一個,我們完全可以用單列索引,這樣的查詢速度較快,索引也比較瘦身。如果我們的業務