
機器學習入門實戰——感知機演算法實戰Iris資料集
感知機演算法實戰Iris資料集
關於感知機的相關理論知識請檢視:感知機
關於Iris資料集
Iris也稱鳶尾花卉資料集,是一類多重變數分析的資料集。資料集包含150個數據集,分為3類,每類50個數據,每個資料包含4個屬性。可通過花萼長度,花萼寬度,花瓣長度,花瓣寬度4個屬性預測鳶尾花卉屬於(Setosa,Versicolour,Virginica)三個種類中的哪一類。
Iris以鳶尾花的特徵作為資料來源,常用在分類操作中。該資料集由3種不同型別的鳶尾花的50個樣本資料構成。其中的一個種類與另外兩個種類是線性可分離的,後兩個種類是非線性可分離的。
該資料集包含了5個屬性:
& Sepal.Length(花萼長度),單位是cm;
& Sepal.Width(花萼寬度),單位是cm;
& Petal.Length(花瓣長度),單位是cm;
& Petal.Width(花瓣寬度),單位是cm;
& 種類:Iris Setosa(山鳶尾)、Iris Versicolour(雜色鳶尾),以及Iris Virginica(維吉尼亞鳶尾)。
程式碼實戰
先介紹一下如何搭建一個感知機,我們需要用到numpy庫
import numpy as np
class Perception 上面我們完成了一個最基本的感知機的搭建,下面我們就要開始處理資料了
首先,我們需要使用pandas庫來讀取資料
import pandas as pd
file = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
df= pd.read_csv(file,header=None)
df.head(10)我們檢視一下前十行資料

通過這些數字我們並不能明顯看出什麼關係,所以接下來,我們用matplotlib庫畫出其中兩種花的兩個變數的關係,我這裡選取的是花瓣長度和花莖的長度
import matplotlib.pyplot as plt
y = df.loc[0:100, 4].values
y = np.where(y == 'Iris-setosa',-1,1)
x = df.loc[0:100,[0,2]].values
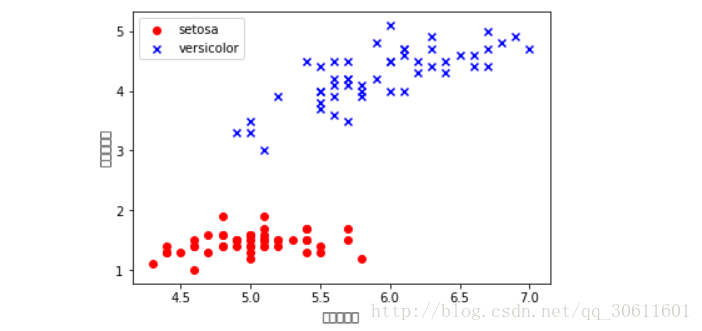
plt.scatter(x[:50,0],x[:50,1],color='red',marker='o',label='setosa')
plt.scatter(x[50:100,0],x[50:100,1],color='blue',marker='x',label='versicolor')
plt.xlabel('花瓣的長度')
plt.ylabel('花莖的長度')
plt.legend(loc = 'upper left')
plt.show()通過影象我們可以很明顯地看出,這兩種花具有的特點
下面我們呼叫之前定義好的感知機模型,讓它學習這些資料,然後我們同樣畫出感知機學習過程中的錯誤次數
ppn = Perception(eta=0.1, n_iter=10)
ppn.fit(x, y)
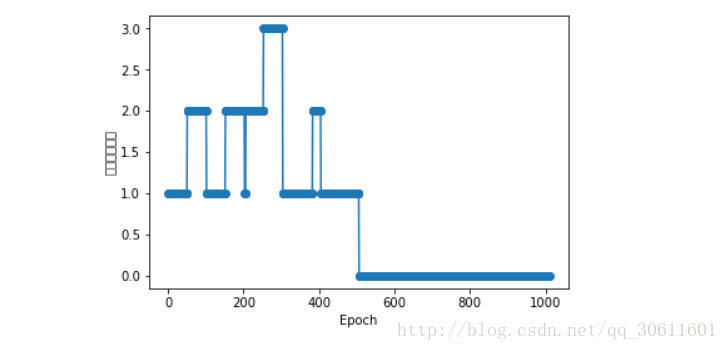
plt.plot(range(1,len(ppn.errors_) + 1),ppn.errors_, marker='o')
plt.xlabel('Epoch')
plt.ylabel('錯誤分類次數')
plt.show()通過圖中可以看出,在剛開始學習時,分類錯誤比較多,到後面就基本沒有錯誤了
如果我們想要檢視一下感知機學習出來的分離超平面可以定義如下一個繪圖函式
from matplotlib.colors import ListedColormap
def plot_decision_regions(x, y, classifier, resolution = 0.02):
marker = ('s', 'x', 'o', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
x1_min, x1_max = x[:,0].min() - 1, x[:,0].max()
x2_min, x2_max = x[:,1].min() - 1, x[:,1].max()
#print(x1_min, x1_max)
#print(x2_min, x2_max)
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
#print(xx1.ravel())
#print(xx2.ravel())
#print(z)
z = z.reshape(xx1.shape)
plt.contourf(xx1, xx2, z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=x[y==cl, 0],y=x[y==cl, 1], alpha=0.8, c=cmap(idx),
marker=marker[idx], label=cl)我們通過呼叫這個函式可以畫出我們學習到的超平面
plot_decision_regions(x, y, ppn, resolution=0.02)
plt.xlabel('花瓣的長度')
plt.ylabel('花莖的長度')
plt.legend(loc = 'upper left')
plt.show()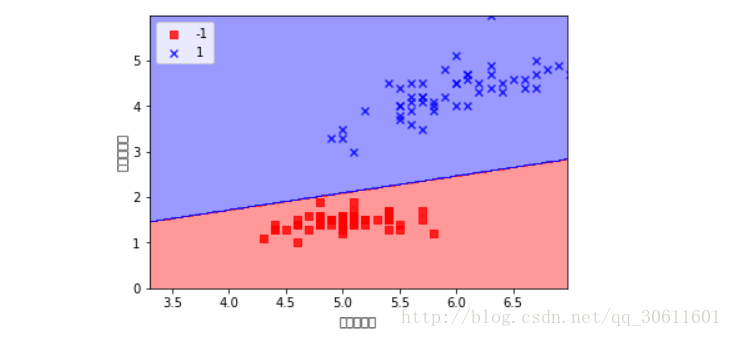
(PS: 在畫圖的時候忘記了中文的問題了。。。)
相關推薦
機器學習入門實戰——感知機演算法實戰Iris資料集
感知機演算法實戰Iris資料集 關於感知機的相關理論知識請檢視:感知機 關於Iris資料集 Iris也稱鳶尾花卉資料集,是一類多重變數分析的資料集。資料集包含150個數據集,分為3類,每類50個數據,每個資料包含4個屬性。可通過花萼長度,花萼寬度,花
機器學習總結2_感知機演算法(PLA)
1.正式開始之前的描述 (1) PLA:Perceptron Learning Algorithm。 在正式開始之前,我想先說一下,PLA到底是幹嘛的。大部分機器學習的書以及視訊都是以感知機演算法作為開頭的。既然放在最前面,它應該就是一個很簡單的機器學
機器學習第一站——感知機
話不多說,先上圖: 看完這個圖相信大家對感知機會有一個比較感性的認識:可以根據不同點的顏色用一條線將整個圖形平面劃分為兩個區域。 這聽起來對我們來說是非常容易的(目測一下就大概知道該怎麼劃線),但對於一個機器或電腦呢,他們是怎麼知道這條線該劃在哪?怎麼保
機器學習筆記 perceptron(感知機) 在ex4Data資料集上的實現
慣例的ML課堂作業,第四個也是最後一個線性分類模型,感知機。 感知機是一個非常簡單的線性分類模型,簡單來說就是一個神經元,其啟用函式是門限函式,有n個輸入和一個輸出,和神經元結構十分相似。 感知機的損失函式是看作是分類錯的所有樣本的輸出值的和 hw的輸出就是
機器學習入門之線性迴歸演算法推導
心血來潮,想將所學到的知識寫篇部落格,筆者所研究的方向為機器學習,剛學習的時候,走了很多彎路,看的書不少,在推導機器學習一些演算法時候遇到了不少困難,查了不少資料,在剛才學的時候,有很多公式推導起來很困難,或者說大多數人都會遇到這樣的問題,本部落格目的就是解決在機器學習公式推導過程中遇到的問
機器學習入門-神經網路&BP演算法的實現
在MP神經元模型之中,神經元接收到來自其它n個神經元傳遞過來的輸入訊號,這些輸入訊號通過帶權重的連線2進行傳遞,神經元接收到的總輸入值與神經元的閾值進行比較,然後通過啟用函式處理以產生神經元的輸出。一般而言選取sigmoid函式作為啟用函式來使用,因為其相對啟用
記一下機器學習筆記 Rosenblatt感知機
一入ML深似海啊… 這裡主要是《神經網路與機器學習》(Neural Networks and Learning Machines,以下簡稱《神機》)的筆記,以及一些周志華的《機器學習》的內容,可能夾雜有自己的吐槽,以及自己用R語言隨便擼的實現。 話說這個《神
《李航:統計學習方法》--- 感知機演算法原理與實現
感知機模型 感知機是一個二類分類的線性分類模型。所謂二類分類就是它只能將例項分為正類和負類兩個類別。那麼為什麼是線性分類模型呢,我的理解是感知機學習旨在求出可以將資料進行劃分的分離超平面,而分離超平面的方程 w⋅x+b=0 為線性方程,所以感知機為線性分類模型
機器學習之支援向量機演算法例項
此例項是利用svm演算法預測乳腺癌腫瘤是良性還是惡性,資料格式如下圖所示:第一列表示編號,2到10列表示資料屬性,第11列表示腫瘤標籤2表示良性4表示惡性。 程式碼如下 from sklearn import svm # x = [[2, 0], [1, 1], [
機器學習之支援向量機演算法(一)
一、問題引入 支援向量機(SVM,Support Vector Machine)在2012年前還是很牛逼的,但是在12年之後神經網路更牛逼些,但是由於應用場景以及應用演算法的不同,我們還是很有必要了解SVM的,而且在面試的過程中SVM一般都會問到。支援向量機是一個非常經典且高效的分類模型。我們的目標:基
機器學習之支援向量機演算法(二)
五、SVM求解例項 上面其實已經得出最終的表示式了,下面我們會根據一些具體的點來求解α的值。資料:3個點,其中正例 X1(3,3) ,X2(4,3) ,負例X3(1,1) 如下圖所示 我們需要求解下式的極小值 注意約束條件(在這裡不要忘記了yi代表的是資料
[Java][機器學習]用決策樹分類演算法對Iris花資料集進行處理
Iris Data Set是很經典的一個數據集,在很多地方都能看到,一般用於教學分類演算法。這個資料集在UCI Machine Learning Repository裡可以找到(還是下載量排第一的資料喲)。這個資料集裡面,每個資料都包含4個值(sepal len
機器視覺、影象處理、機器學習領域相關程式碼和工程專案和資料集 集合
SIFT [1] [Demo program][SIFT Library] [VLFeat] PCA-SIFT [2] [Project] Affine-SIFT [3] [Project] SURF [4] [OpenSURF] [Matlab Wrapper] Af
《機器學習(周志華)》 西瓜資料集3.0
書上的一個常用資料集 編號,色澤,根蒂,敲聲,紋理,臍部,觸感,密度,含糖率,好瓜 1,青綠,蜷縮,濁響,清晰,凹陷,硬滑,0.697,0.46,是 2,烏黑,蜷縮,沉悶,清晰,凹陷,硬滑,0.774
【深度學習】BP演算法分類iris資料集
Network: package test2; import java.util.Random; public class Network { private double input[]; // 輸入層 private doub
Python 3實現k-鄰近演算法以及 iris 資料集分類應用
前言 這個周基本在琢磨這個演算法以及自己利用Python3 實現自主程式設計實現該演算法。持續時間比較長,主要是Pyhton可能還不是很熟練,走了很多路,基本是一邊寫一邊學。不過,總算是基本搞出來了。不多說,進入正題。 1. K-鄰近演算法 1.1
機器學習筆記(1) 感知機演算法 之 實戰篇
我們在上篇筆記中介紹了感知機的理論知識,討論了感知機的由來、工作原理、求解策略、收斂性。這篇筆記中,我們親自動手寫程式碼,使用感知機演算法解決實際問題。 先從一個最簡單的問題開始,用感知機演算法解決OR邏輯的分類。 import numpy as np import matplotlib.pyplot as
恰到好處的機器學習入門課,一站搞定基礎+演算法+實戰
每天能留給學習的時間不多,當入門一個新技術的時候,多麼希望學到的每一個字都能立馬爬上用場,所以我
教你6步從頭寫機器學習演算法——以感知機演算法為例
自己從頭寫一個演算法,不僅能給你帶來成就感,也能幫你真正理解演算法的原理。可能你之前用 Scikit-learn 實現過演算法,但是從零開始寫個演算法簡單嗎?絕對不簡單。 有些演算法要比其它演算法複雜的多,所以在寫演算法時可以先從簡單的開始,比如單層的感知機。 下面就介紹機器學家 John S
python機器學習入門到精通--實戰分析(三)
利用sklearn分析鳶尾花 前面兩篇文章提到了機器學習的入門的幾個基礎庫及拓展練習,現在我們就對前面知識點進行彙總進行一個簡單的機器學習應用,並構建模型。 練習即假定一名植物專家收集了每一朵鳶尾花的測量資料:花瓣的長度和寬度以及花萼的長度和寬度,所有測量結