
[機器學習實驗4]正則化(引入懲罰因子)
阿新 • • 發佈:2019-02-16
線性迴歸中引入正則化引數。
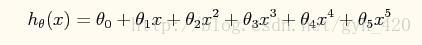
x再線性迴歸的實踐中是一維的,如果是更高維度的還要做一個特徵的轉化,後面的logic迴歸裡面會提到
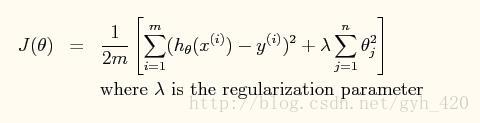
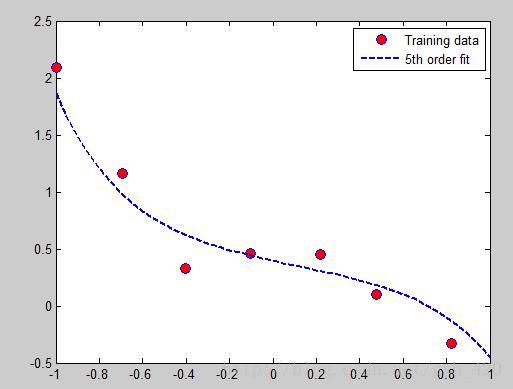
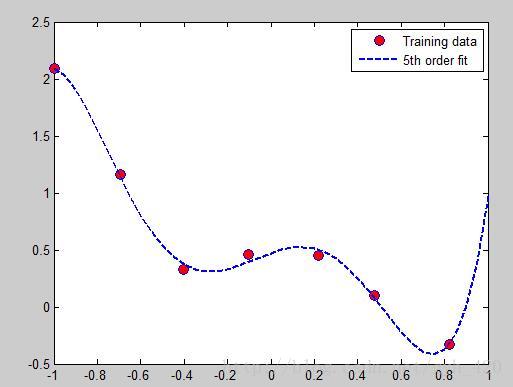
引入正則化引數之後公式如上,當最小化J(θ)時,λ 越大,θ越小,所以通過調節λ的值可以調節擬合的h函式中中θ的大小從而調節擬合的程度,λ過大會導致欠擬合,過小會導致過擬合。
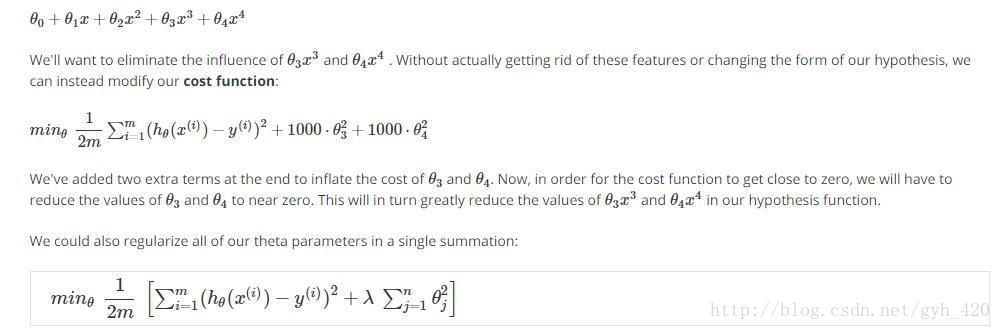
為了展示出引入正則化後公式上的不同,就不實用梯度下降,實用梯度下降和之前的實驗是一樣的,本實驗使用的是最小二乘法,公式變為:

得到的θ即為我們要求的引數,通過調節λ來看擬合效果
程式碼如下:
%%線性迴歸的正則化
clear all; close all; clc
x = load('ex5Linx.dat' λ = 10時:
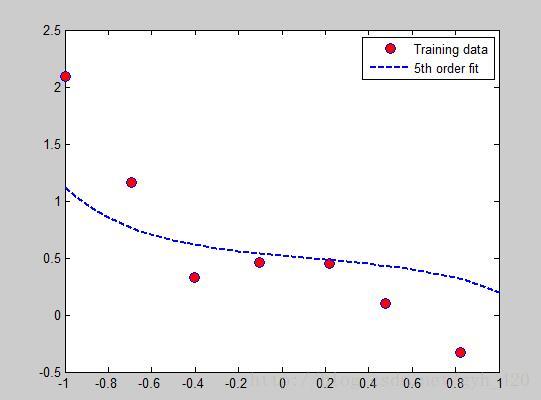
λ = 1時:
λ = 0時:
logic迴歸中引入正則化引數
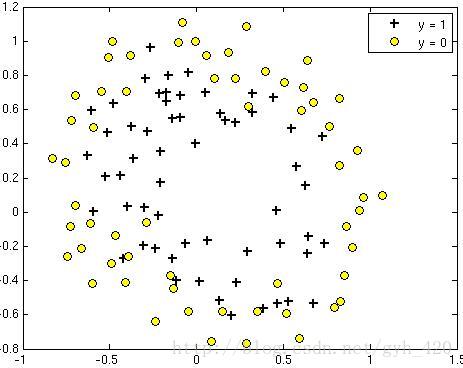
之前下載的資料集中ex5Logx,ex5Logy標記了x資料中的哪些是正(1)哪些是負(0)樣本,我們擬用這個資料來訓練出一個二分類器。
讀取的資料如下圖
我們使用的分類函式:
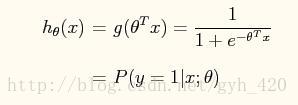
因為x的維度是二維的,就是有兩個特徵引數,而我們又要進行多項式擬合,那麼就要擴充套件特徵引數到高次,比如說擴充套件到6次方,首先還是要加入截距項(x=1的項)

程式碼如下:
function out = map_feature(feat1, feat2)
% MAP_FEATURE Feature mapping function for Exercise 5
%
% map_feature(feat1, feat2) maps the two input features
% to higher-order features as defined in Exercise 5.
%
% Returns a new feature array with more features
%
% Inputs feat1, feat2 must be the same size
%
% Note: this function is only valid for Ex 5, since the degree is
% hard-coded in.
degree = 6;
out = ones(size(feat1(:,1)));
for i = 1:degree
for j = 0:i
out(:, end+1) = (feat1.^(i-j)).*(feat2.^j);
end
end
更高維度的特徵引數的擴充套件和這個方法類似,可以類推,這個部分的推導我還不是很清楚是怎麼推出來的,知道的朋友可以在評論裡分享出來,謝謝。
代價函式J(θ)也是類似引入懲罰項:
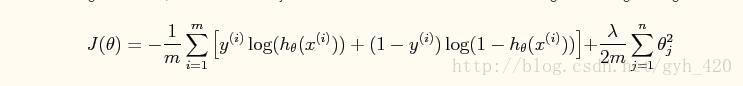
使用牛頓方法來求θ值

程式碼如下:
x = load('ex5Logx.dat');
y = load('ex5Logy.dat');
Plot the training data
Use different markers for positives and negatives
figure
pos = find(y); neg = find(y == 0);
% 正樣本pos個,負樣本neg個
plot(x(pos, 1), x(pos, 2), 'k+','LineWidth', 2, 'MarkerSize', 7)
hold on
plot(x(neg, 1), x(neg, 2), 'ko', 'MarkerFaceColor', 'y', 'MarkerSize', 7)
%注意這個地方的feature,x原來是一個二維的變數,一方面要插入截距(就是全為1的那列),另一方面在做非線性的擬合平面時
%它的2次方、3次方。。。n次方擴充套件是x1^i * x2^j這樣進行的
x = map_feature(x(:,1), x(:,2));
[m, n] = size(x);
% Initialize fitting parameters
theta = zeros(n, 1);
% Define the sigmoid function
%邏輯迴歸的hypotheise
g = inline('1.0 ./ (1.0 + exp(-z))');
% setup for Newton's method
%迭代次數
MAX_ITR = 15;
J = zeros(MAX_ITR, 1);
% Lambda is the regularization parameter
lambda = 0.5;
for i = 1:MAX_ITR
% Calculate the hypothesis function
z = x * theta;
h = g(z) ;%h函式
% Calculate J (for testing convergence)
J(i) =(1/m)*sum(-y.*log(h) - (1-y).*log(1-h))+ ...
(lambda/(2*m))*norm(theta([2:end]))^2; %不包括theta(0)
%norm求的是向量theta的2範數,公式中不是平方根,所以要平方一下
% Calculate gradient and hessian.
G = (lambda/m).*theta; G(1) = 0; % extra term for gradient
L = (lambda/m).*eye(n); L(1) = 0;% extra term for Hessian
%這裡的兩個計算和前面的logic regression實驗裡是一樣的方法
grad = ((1/m).*x' * (h-y)) + G;
H = ((1/m).*x' * diag(h) * diag(1-h) * x) + L;
% Here is the actual update
theta = theta - H\grad;
end
% Define the ranges of the grid
u = linspace(-1, 1.5, 200);
v = linspace(-1, 1.5, 200);
% Initialize space for the values to be plotted
z = zeros(length(u), length(v));
% Evaluate z = theta*x over the grid
for i = 1:length(u)
for j = 1:length(v)
% Notice the order of j, i here!
z(j,i) = map_feature(u(i), v(j))*theta;
end
end
% Because of the way that contour plotting works
% in Matlab, we need to transpose z, or
% else the axis orientation will be flipped!
z = z'
% Plot z = 0 by specifying the range [0, 0]
contour(u,v,z, 'LineWidth', 2)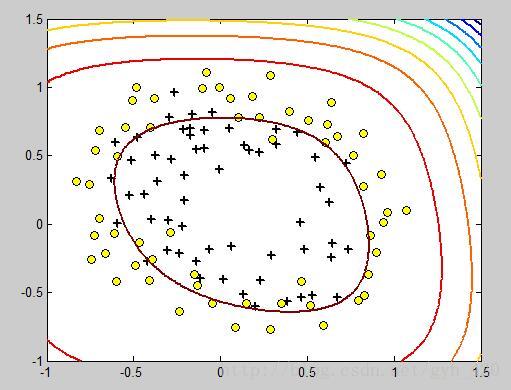
這是繪製的θ*X的方程,而我們要θ*X=0的輪廓,將
contour(u,v,z, ‘LineWidth’, 2)改成contour(u,v,z, [0,0],’LineWidth’, 2)即可
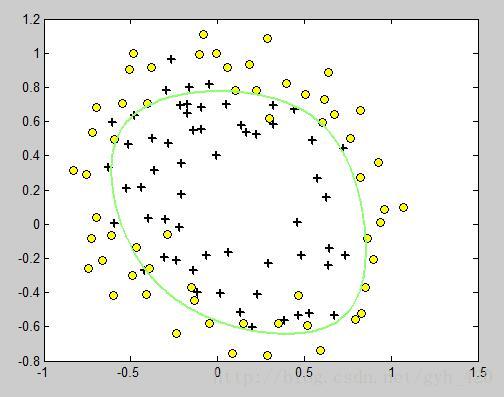
調整λ的值可以得到強弱不同的邊界。