
【HDFS基礎】HDFS檔案目錄詳解
HDFS的檔案目錄圖

分析:從上圖可以看出,HDFS的檔案目錄主要由NameNode、SecondaryNameNode和DataNode組成,而NameNode和DataNode之間由心跳機制通訊。
注:
- HDFS(Hadoop Distributed File System)預設的儲存單位是128M的資料塊。
可以執行命令vim /home/qingaolei/hadoop/hadoop-2.8.0/share/doc/hadoop/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml檢視

- 當然也可以通過修改配置檔案進行修改,通過命令vim /home/qingaolei/hadoop/hadoop-2.8.0/etc/hadoop/hdfs-site.xml進入到配置檔案進行修改。

NameNode
1.NameNode的檔案結構

//中間省略很多行
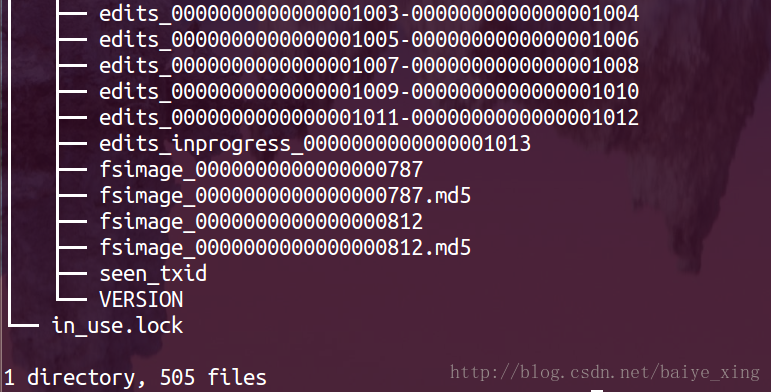
分析:從上圖可以看出,NameNode的檔案結構包含edits、fsimage、seen_txid、VERSION
2.edits
編輯日誌(edit log):當客戶端執行寫操作時,首先NameNode會在編輯日誌中寫下記錄,並在記憶體中儲存一個檔案系統元資料,這個描述符會在編輯日誌改動之後更新。
edits_start transaction ID-end transaction ID
finalized edit log segments,在HA(高可用)環境中,Standby Namenode只能讀取finalized log segments,edits_inprogress__start transaction ID
當前正在被追加的edit log,HDFS預設會為該檔案提前申請1MB空間以提升效能
3.fsimage
檔案系統映象(fsimage):檔案系統元資料的持久檢查點,包含以序列化格式(從Hadoop-2.4.0起,FSImage開始採用Google Protobuf編碼格式)儲存的檔案系統目錄和檔案inodes,每個inodes表徵一個檔案或目錄的元資料資訊以及檔案的副本數、修改和訪問時間等資訊。
fsimage_end transaction ID
每次checkpoing(合併所有edits到一個fsimage的過程)產生的最終的fsimage,同時會生成一個.md5的檔案用來對檔案做完整性校驗(詳細過程見下文)。
4.seen_txid
seen_txid是存放transactionId的檔案,format之後是0,它代表的是namenode裡面的edits_*檔案的尾數,namenode重啟的時候,會按照seen_txid的數字,循序從頭跑edits_0000001~到seen_txid的數字。
當hdfs發生異常重啟的時候,一定要比對seen_txid內的數字是不是你edits最後的尾數,不然會發生建置namenode時metaData的資料有缺少,導致誤刪Datanode上多餘Block的資訊。
5.VERSION
VERSION檔案是java屬性檔案,儲存了HDFS的版本號。

• namespaceID是檔案系統的唯一識別符號,是在檔案系統初次格式化時生成的。
• clusterID是系統生成或手動指定的叢集ID
• cTime表示NameNode儲存時間的建立時間,升級後會更新該值。
• storageType表示此資料夾中儲存的是元資料節點的資料結構。
• blockpoolID:針對每一個Namespace所對應blockpool的ID,該ID包括了其對應的NameNode節點的ip地址。
• layoutVersion是一個負整數,儲存了HDFS的持續化在硬碟上的資料結構的格式版本號。
6.in_use.lock
防止一臺機器同時啟動多個Namenode程序導致目錄資料不一致
SecondaryNameNode
1.SecondaryNameNode的檔案結構

分析:從上圖可以看出,SecondaryNameNode主要包括edits、fsimage、VERSION
2.edits
從NameNode複製的日誌檔案
3.fsimage
從NameNode複製的映象檔案
4.VERSION

注:SecondaryNameNode和NameNode的VERSION系相同,不再贅述。
5.in_use.lock
防止一臺機器同時啟動多個SecondaryNameNode程序導致目錄資料不一致
check point 過程
1.圖例:檢查點處理過程

2.過程分析
1)Secondary NameNode首先請求原NameNode進行edits的滾動,這樣新的編輯操作就能夠進入新的檔案中。
2)Secondary NameNode通過HTTP方式讀取原NameNode中的fsimage及edits。
3)Secondary NameNode讀取fsimage到記憶體中,然後執行edits中的每個操作,並建立一個新的統一的fsimage檔案。
4)Secondary NameNode通過HTTP方式將新的fsimage傳送到原NameNode。
5)原NameNode用新的fsimage替換舊的fsimage,舊的edits檔案用步驟1)中的edits進行替換(將edits.new改名為edits)。同時系統會更新fsimage檔案到記錄檢查點的時間。
這個過程結束後,NameNode就有了最新的fsimage檔案和更小的edits檔案
注:可執行hadoop dfsadmin –saveNamespace命令執行上圖的過程Secondary NameNode(NameNode的冷備份)每隔一小時會插入一個檢查點,如果編輯日誌達到64MB,則間隔時間更短,每隔5分鐘檢查一次。
DataNode
1.DataNode的檔案結構
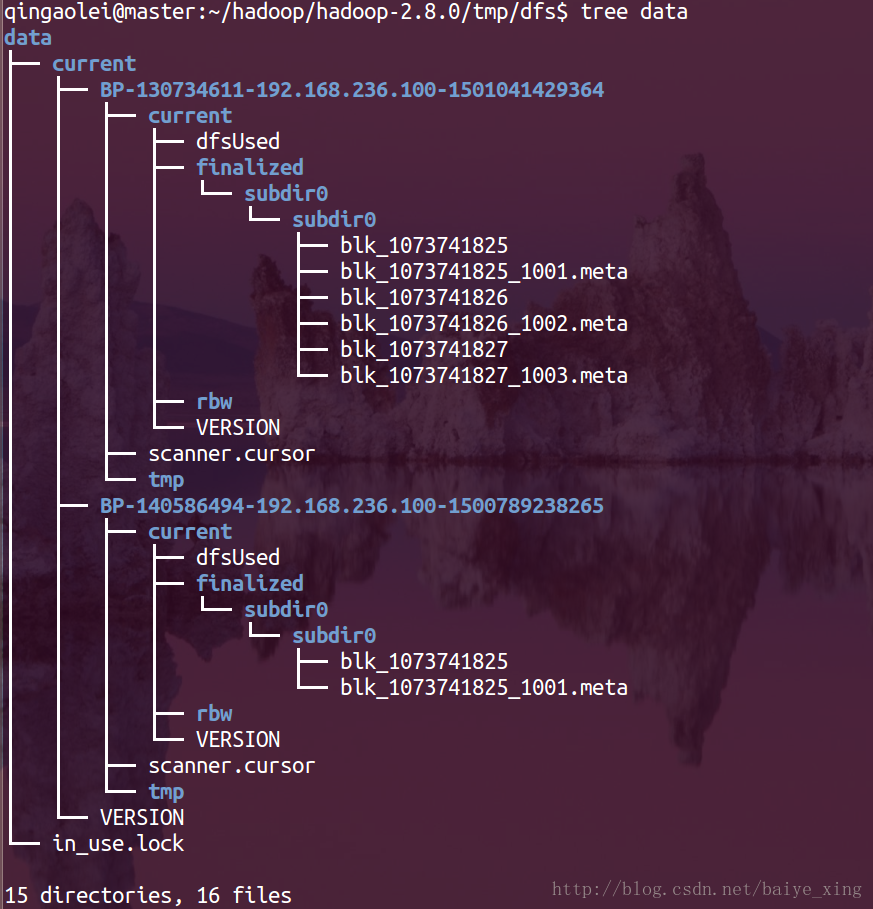
分析:從上圖可以看出,.DataNode的檔案結構主要由blk_字首檔案、BP-random integer-NameNode-IP address-creation time和VERSION構成。
2.BP-random integer-NameNode-IP address-creation time
BP代表BlockPool的,就是Namenode的VERSION中的叢集唯一blockpoolID,
從上圖可以看出我的DataNode是兩個BP,這是因為我的HDFS是Federation HDFS,所以該目錄下有兩個BP開頭的目錄,IP部分和時間戳代表建立該BP的NameNode的IP地址和建立時間戳
3.finalized/rbw
這兩個目錄都是用於實際儲存HDFS BLOCK的資料,裡面包含許多block_xx檔案以及相應的.meta檔案,.meta檔案包含了checksum資訊。
rbw是“replica being written”的意思,該目錄用於儲存使用者當前正在寫入的資料。
4.blk_字首檔案
HDFS中的檔案塊本身,儲存的是原始檔案內容。
塊的元資料資訊(使用.meta字尾標識)。一個檔案塊由儲存的原始檔案位元組組成,元資料檔案由一個包含版本和型別資訊的標頭檔案和一系列塊的區域校驗和組成。
注:當目錄中儲存的塊資料量增加到一定規模時,DataNode會建立一個新的目錄,用於儲存新的塊及元資料。當目錄中的塊資料量達到64(可由dfs.DataNode.numblocks屬性確定)時,便會新建一個子目錄,這樣就會形成一個更寬的檔案樹結構,避免了由於儲存大量資料塊而導致目錄很深,使檢索效能免受影響。通過這樣的措施,資料節點可以確保每個目錄中的檔案塊都可控的,也避免了一個目錄中存在過多檔案。
5.VERSION

• storageID相對於DataNode來說是唯一的,用於在NameNode處標識DataNode
• clusterID是系統生成或手動指定的叢集ID
• cTime表示NameNode儲存時間的建立時間
• datanodeUuid表示DataNode的ID號
• storageType將這個目錄標誌位DataNode資料儲存目錄。
• layoutVersion是一個負整數,儲存了HDFS的持續化在硬碟上的資料結構的格式版本號。
6.in_use.lock
防止一臺機器同時啟動多個Datanode程序導致目錄資料不一致
本人才疏學淺,若有錯,請指出,謝謝!
如果你有更好的建議,可以留言我們一起討論,共同進步!
衷心的感謝您能耐心的讀完本篇博文!
相關推薦
【夯實基礎】java關鍵字synchronized 詳解
尊重版權:http://www.cnblogs.com/GnagWang/archive/2011/02/27/1966606.html Java語言的關鍵字,當它用來修飾一個方法或者一個程式碼塊的時候,能夠保證在同一時刻最多隻有一個執行緒執行該段程式碼。 一、當兩個併發執行緒訪問同一個物件obj
轉:【HDFS基礎】HDFS檔案目錄詳解
版權宣告:本文為博主原創文章,若轉載,請註明出處,謝謝! https://blog.csdn.net/baiye_xing/article/details/76268495 HDFS的檔案目錄圖 分析:從上圖可以看出,HDFS的檔案目錄主要由NameNode
【HDFS基礎】HDFS檔案目錄詳解
HDFS的檔案目錄圖 分析:從上圖可以看出,HDFS的檔案目錄主要由NameNode、SecondaryNameNode和DataNode組成,而NameNode和DataNode之間由心跳機制通訊。 注: HDFS(Hadoop Distribut
【Three.js:3D模型】【轉載】OBJ檔案格式詳解
轉載:3D中的OBJ檔案格式詳解 常見到的*.obj檔案有兩種:第一種是基於COFF(Common Object File Format)格式的OBJ檔案(也稱目標檔案),這種格式用於編譯應用程式;第二種是Alias|Wavefront公司推出的OBJ模型檔案。本文對第二種ob
【PHP系列】PHP組件詳解
命令行 分享 .cn .com function package etc quest 說我 緣起 楓爺之前做過幾年的PHP的研發,大部分都是在開源框架的引導下,編寫代碼。現在依然,本能的會去讓我使用某個PHP框架開發PHP應用,也是因為懶吧,沒有好好的去研究研究除了框架之外
【基本操作】樹上啟發式合併の詳解
樹上啟發式合併是某些神仙題目的常見操作。 這裡有一個講得詳細一點的,不過為了深刻記憶,我還是再給自己講一遍吧! DSU(Disjoint Set Union),別看英文名挺高階,其實它就是並查集…… DSU on tree,也就是樹上的啟發式合併(眾所周知,並查集最重要的優化就是啟發式合
【機器學習】梯度下降法詳解
一、導數 導數 就是曲線的斜率,是曲線變化快慢的一個反應。 二階導數 是斜率變化的反應,表現曲線的 凹凸性 y
【Linux程式設計】守護程序(daemon)詳解與建立
一、概述 Daemon(守護程序)是執行在後臺的一種特殊程序。它獨立於控制終端並且週期性地執行某種任務或等待處理某些發生的事件。它不需要使用者輸入就能執行而且提供某種服務,不是對整個系統就是對某個使用者程式提供服務。Linux系統的大多數伺服器就是通過守護程序實現的。常見的守護
【課程分享】procast砂型鑄造詳解教程(鑄鋼鑄鐵為例)
本課程詳細以鑄鋼鑄鐵為例介紹了砂型鑄造各階段的操作教程。主要有十四個課時。講述了幾何模型的處理、網格劃分、鑄鋼鑄鐵引數設定、後處理結果分析、過濾網引數設定、材料資料庫的建立和一些常用的操作,具體看列表。練習模型已上傳附件。 技術鄰專家介紹 一杯敬明月 工藝工程師 擅
【初等排序】插入排序法詳解
插入排序法 插入排序法是一種很容易想到的演算法,它的思路與打撲克時排列手牌的方法很相似。比如我們現在單手拿牌,然後要將牌從左至右,從小到大進行排序。此時我們需要將牌一張張抽出來,分別插入到前面已排好序的手牌中的適當位置。重複這一操作直到插入最後一張牌,整個排序就完成了。 插入排序的演算法
【目標檢測】Faster RCNN演算法詳解
Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with region proposal networks.” Advances in Neural Information P
AndroidStudio的檔案目錄詳解
AndroidStudio的目錄檔案 ①.gradle和②.idea目錄 ①和②目錄下都是AndroidStudio自動生成的一些檔案,無需手動編輯,我們在此略過 ③app目錄 ③目錄下放置專案的程式碼、資源、清單檔案 (3.1)bui
【目標檢測】Fast RCNN演算法詳解
Girshick, Ross. “Fast r-cnn.” Proceedings of the IEEE International Conference on Computer Vision. 2015. 繼2014年的RCNN之後,Ross Girshick在15年
068:【Django資料庫】ORM查詢條件詳解-date、time、year、week_day等
【Django資料庫】ORM查詢條件詳解-date、time、year、week_day等: year:根據年份進行查詢。示例程式碼如下: articles = Article.objects.filter(create_time__year=2018) articles = Article.obj
【Asp.net】—web.config配置詳解
前言 小編最近這一段時間在學習Asp.net視訊,在視訊中,當每一次通過.NET新建一個Web應用程式後,預設情況下會在根目錄自動建立一個預設的Web.config檔案。那麼這個Web.conf
【機器學習】主成分分析詳解
一、PCA簡介 1. 相關背景 主成分分析(Principal Component Analysis,PCA), 是一種統計方法。通過正交變換將一組可能存在相關性的變數轉換為一組線性不相關的變數,轉換後的這組變數叫主成分。 上完陳恩紅老師的《機器學習與知識發現》和季
071:【Django資料庫】ORM聚合函式詳解-Avg
ORM聚合函式詳解-Avg: Avg:求平均值。比如想要獲取所有圖書的價格平均值。那麼可以使用以下程式碼實現: from django.db.models import Avg result = Book.objects.aggregate(Avg('price')) print(result
073:【Django資料庫】ORM聚合函式詳解-Count
ORM聚合函式詳解-Count: Count :獲取指定的物件的個數。示例程式碼如下: from django.db.models import Count result = Book.objects.aggregate(book_num=Count('id')) 以上的 result 將返回
075: 【Django資料庫】ORM聚合函式詳解-Sum
ORM聚合函式詳解-Sum: Sum :求指定物件的總和。比如要求圖書的銷售總額。那麼可以使用以下程式碼實現: from djang.db.models import Sum result = Book.objects.annotate(total=Sum("bookstore__price")).
【C/C++】自增運算子++詳解
關於 a = 2 * a++ *(3 – ++a)的運算過程分析: 將以上原始碼進行反彙編之後的結果如下: int a = 2; 00C313DE mov dword ptr [a],2 // a = 2; a = 2 * a