
資料結構基礎溫故-5.圖(上):圖的基本概念
前面幾篇已經介紹了線性表和樹兩類資料結構,線性表中的元素是“一對一”的關係,樹中的元素是“一對多”的關係,本章所述的圖結構中的元素則是“多對多”的關係。圖(Graph)是一種複雜的非線性結構,在圖結構中,每個元素都可以有零個或多個前驅,也可以有零個或多個後繼,也就是說,元素之間的關係是任意的。現實生活中的很多事物都可以抽象為圖,例如世界各地接入Internet的計算機通過網線連線在一起,各個城市和城市之間的鐵軌等等。
一、圖的基本概念
1.1 多對多的複雜關係

現實中人與人之間關係非常複雜,比如我認識的朋友,可能他們之間也互相認識,這不是簡單的一對一、一對多,研究人際關係很自然會考慮多對多的情況。圖是一種較線性表和樹更加複雜的資料結構。在圖形結構中,結點之間的關係可以是任意的,圖中任意兩個資料元素之間都可能相關。
定義:圖(Graph)是由頂點的有窮非空集合和頂點之間邊的集合組成,通常表示為:G(V,E),其中,G表示一個圖,V是圖G中頂點的集合,E是圖G中邊的集合。
在圖中需要注意的是:
(1)線性表中我們把資料元素叫元素,樹中將資料元素叫結點,在圖中資料元素,我們則稱之為頂點(Vertex)。
(2)線性表可以沒有元素,稱為空表;樹中可以沒有節點,稱為空樹;但是,在圖中不允許沒有頂點(有窮非空性)。
(3)線性表中的各元素是線性關係,樹中的各元素是層次關係,而圖中各頂點的關係是用邊來表示(邊集可以為空)。
1.2 紛繁冗多的術語
圖的基本術語有很多,本文只挑選幾個特別重要的來說明,其餘的請閱讀相關教材。
(1)無向圖
 如果圖中任意兩個頂點之間的邊都是無向邊(簡而言之就是沒有方向的邊),則稱該圖為無向圖(Undirected graphs)。
如果圖中任意兩個頂點之間的邊都是無向邊(簡而言之就是沒有方向的邊),則稱該圖為無向圖(Undirected graphs)。
(2)有向圖
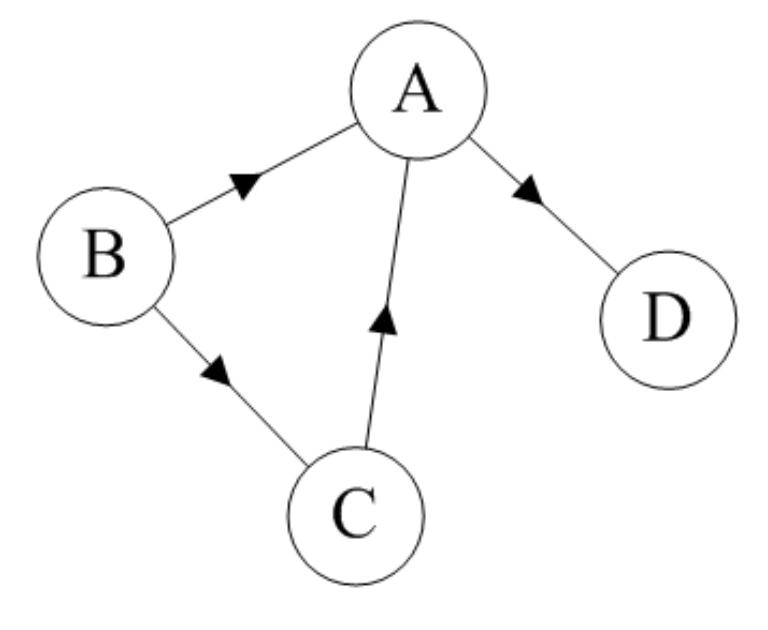
如果圖中任意兩個頂點之間的邊都是有向邊(簡而言之就是有方向的邊),則稱該圖為有向圖(Directed graphs)。
(3)完全圖
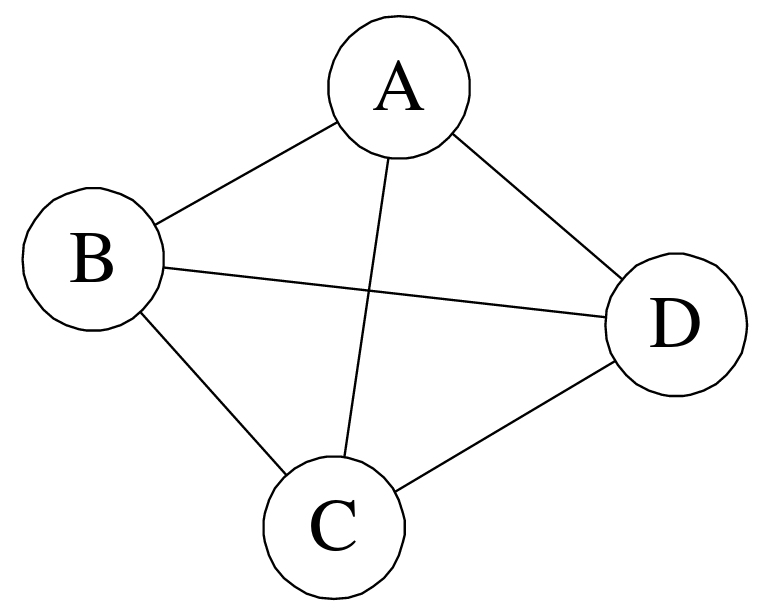
①無向完全圖:在無向圖中,如果任意兩個頂點之間都存在邊,則稱該圖為無向完全圖。(含有n個頂點的無向完全圖有(n×(n-1))/2條邊)如下圖所示:
②有向完全圖:在有向圖中,如果任意兩個頂點之間都存在方向互為相反的兩條弧,則稱該圖為有向完全圖。(含有n個頂點的有向完全圖有n×(n-1)條邊)如下圖所示:
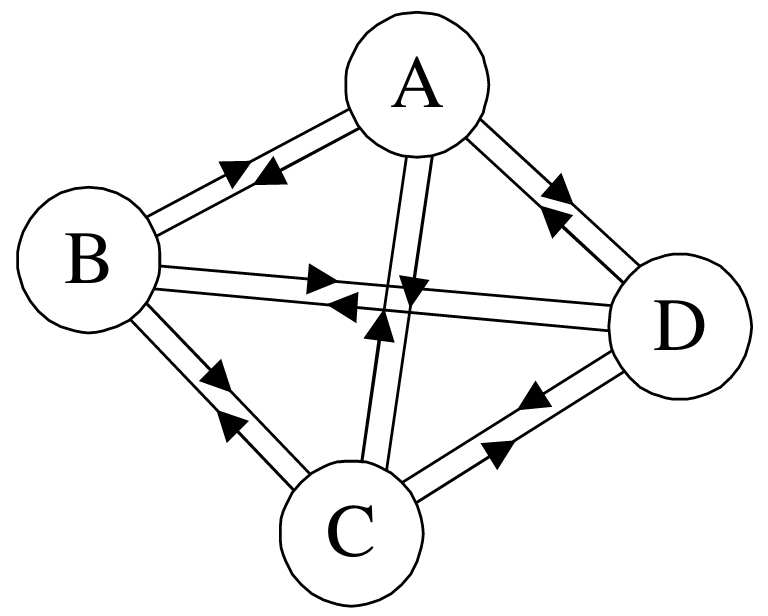
PS:當一個圖接近完全圖時,則稱它為稠密圖(Dense Graph),而當一個圖含有較少的邊時,則稱它為稀疏圖(Spare Graph)。
(4)頂點的度
頂點Vi的度(Degree)是指在圖中與Vi相關聯的邊的條數。對於有向圖來說,有入度(In-degree)和出度(Out-degree)之分,有向圖頂點的度等於該頂點的入度和出度之和。
(5)鄰接
①若無向圖中的兩個頂點V1和V2存在一條邊(V1,V2),則稱頂點V1和V2鄰接(Adjacent);
②若有向圖中存在一條邊<V3,V2>,則稱頂點V3與頂點V2鄰接,且是V3鄰接到V2或V2鄰接直V3;
PS:無向圖中的邊使用小括號“()”表示,而有向圖中的邊使用尖括號“<>”表示。
(6)路徑
在無向圖中,若從頂點Vi出發有一組邊可到達頂點Vj,則稱頂點Vi到頂點Vj的頂點序列為從頂點Vi到頂點Vj的路徑(Path)。
(7)連通
若從Vi到Vj有路徑可通,則稱頂點Vi和頂點Vj是連通(Connected)的。
(8)權
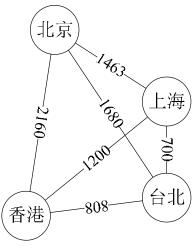
有些圖的邊或弧具有與它相關的數字,這種與圖的邊或弧相關的數叫做權(Weight)。
二、圖的儲存結構
圖的儲存結構除了要儲存圖中的各個頂點本身的資訊之外,還要儲存頂點與頂點之間的關係,因此,圖的結構也比較複雜。常用的圖的儲存結構有鄰接矩陣和鄰接表等。
2.1 鄰接矩陣表示法
圖的鄰接矩陣(Adjacency Matrix)儲存方式是用兩個陣列來表示圖。一個一維陣列儲存圖中頂點資訊,一個二維陣列(稱為鄰接矩陣)儲存圖中的邊或弧的資訊。
(1)無向圖:

我們可以設定兩個陣列,頂點陣列為vertex[4]={v0,v1,v2,v3},邊陣列arc[4][4]為上圖右邊這樣的一個矩陣。對於矩陣的主對角線的值,即arc[0][0]、arc[1][1]、arc[2][2]、arc[3][3],全為0是因為不存在頂點的邊。
(2)有向圖:
我們再來看一個有向圖樣例,如下圖所示的左邊。頂點陣列為vertex[4]={v0,v1,v2,v3},弧陣列arc[4][4]為下圖右邊這樣的一個矩陣。主對角線上數值依然為0。但因為是有向圖,所以此矩陣並不對稱,比如由v1到v0有弧,得到arc[1][0]=1,而v到v沒有弧,因此arc[0][1]=0。

不足:由於存在n個頂點的圖需要n*n個數組元素進行儲存,當圖為稀疏圖時,使用鄰接矩陣儲存方法將會出現大量0元素,這會造成極大的空間浪費。這時,可以考慮使用鄰接表表示法來儲存圖中的資料。
2.2 鄰接表表示法
首先,回憶我們線上性表時談到,順序儲存結構就存在預先分配記憶體可能造成儲存空間浪費的問題,於是引出了鏈式儲存的結構。同樣的,我們也可以考慮對邊或弧使用鏈式儲存的方式來避免空間浪費的問題。
鄰接表由表頭節點和表節點兩部分組成,圖中每個頂點均對應一個儲存在陣列中的表頭節點。如果這個表頭節點所對應的頂點存在鄰接節點,則把鄰接節點依次存放於表頭節點所指向的單向連結串列中。
(1)無向圖:下圖所示的就是一個無向圖的鄰接表結構。

從上圖中我們知道,頂點表的各個結點由data和firstedge兩個域表示,data是資料域,儲存頂點的資訊,firstedge是指標域,指向邊表的第一個結點,即此頂點的第一個鄰接點。邊表結點由adjvex和next兩個域組成。adjvex是鄰接點域,儲存某頂點的鄰接點在頂點表中的下標,next則儲存指向邊表中下一個結點的指標。例如:v1頂點與v0、v2互為鄰接點,則在v1的邊表中,adjvex分別為v0的0和v2的2。
PS:對於無向圖來說,使用鄰接表進行儲存也會出現資料冗餘的現象。例如上圖中,頂點V0所指向的連結串列中存在一個指向頂點V3的同事,頂點V3所指向的連結串列中也會存在一個指向V0的頂點。
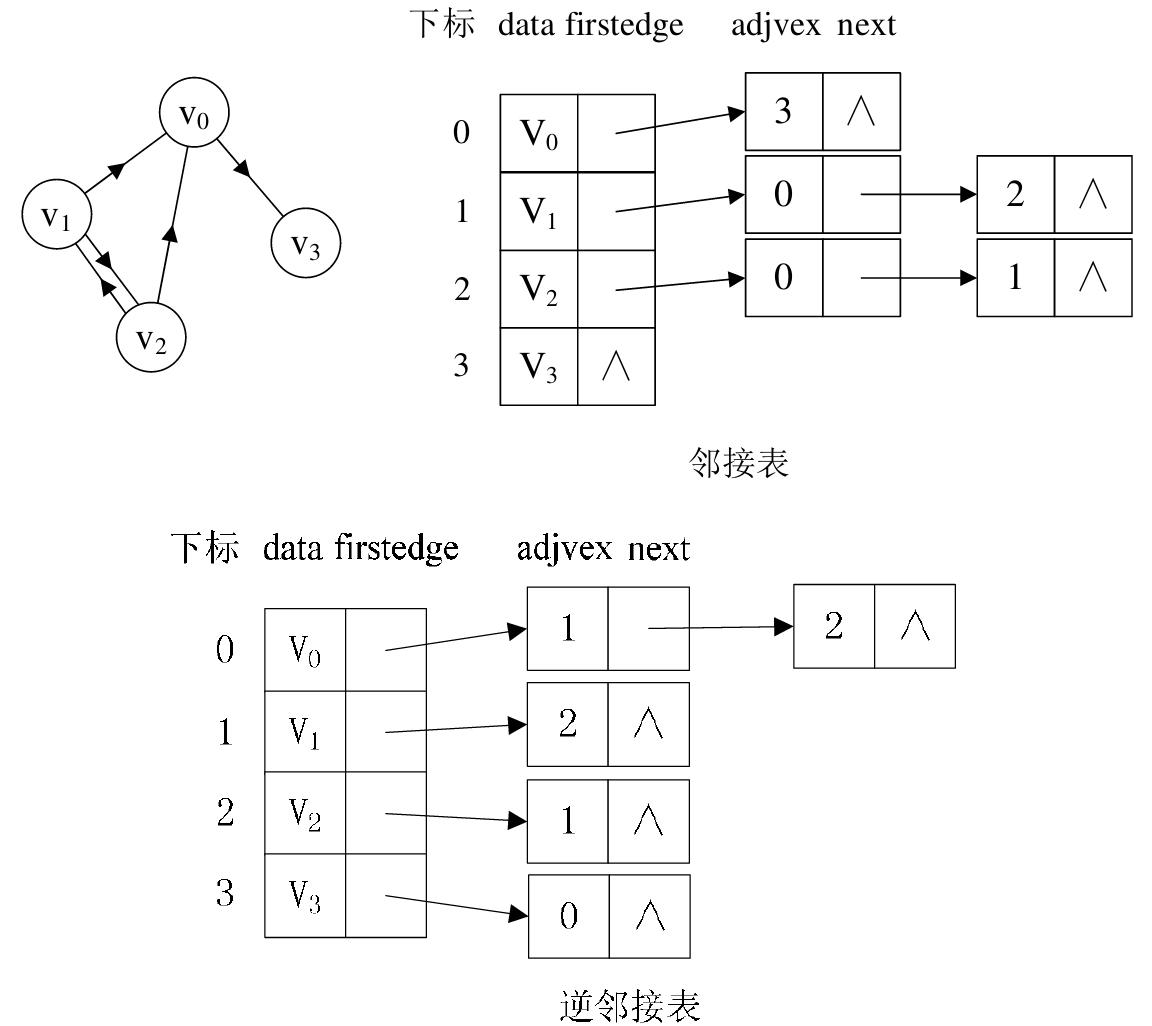
(2)有向圖:若是有向圖,鄰接表結構是類似的,但要注意的是有向圖由於有方向的。因此,有向圖的鄰接表分為出邊表和入邊表(又稱逆鄰接表),出邊表的表節點存放的是從表頭節點出發的有向邊所指的尾節點;入邊表的表節點存放的則是指向表頭節點的某個頂點,如下圖所示。
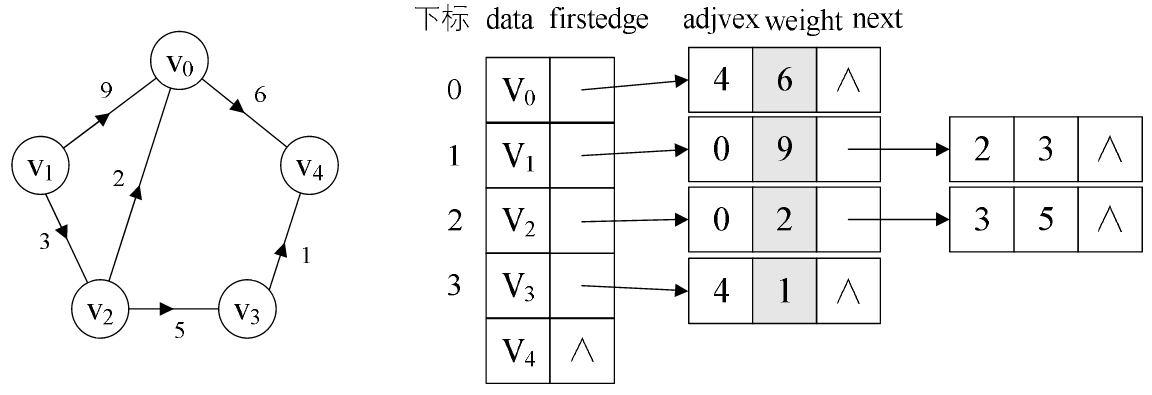
(3)帶權圖:對於帶權值的網圖,可以在邊表結點定義中再增加一個weight的資料域,儲存權值資訊即可,如下圖所示。
三、圖的模擬實現
PS:由於鄰接矩陣容易造成空間資源的浪費,因此這裡只考慮使用鄰接表來實現。
3.1 總體設計結構
(1)連結串列節點定義
①表頭節點Vertex


/// <summary> /// 巢狀類:存放於陣列中的表頭節點 /// </summary> /// <typeparam name="TValue"></typeparam> protected class Vertex<TValue> { public TValue data; // 資料 public Node firstEdge; // 鄰接點連結串列頭指標 public bool isVisited; // 訪問標誌:遍歷時使用 public Vertex() { this.data = default(TValue); } public Vertex(TValue value) { this.data = value; } }View Code
②表節點Node
/// <summary> /// 巢狀類:連結串列中的表節點 /// </summary> protected class Node { public Vertex<T> adjvex; // 鄰接點域 public Node next; // 下一個鄰接點指標域 public Node() { this.adjvex = null; } public Node(Vertex<T> value) { this.adjvex = value; } }View Code
(2)鄰接表總體定義
public class MyAdjacencyList<T> where T : class { private List<Vertex<T>> items; // 圖的頂點集合 public MyAdjacencyList() : this(10) { } public MyAdjacencyList(int capacity) { this.items = new List<Vertex<T>>(capacity); } #region 基本方法:為圖中新增頂點、新增有向與無向邊 #endregion #region 輔助方法:圖中是否包含某個元素、查詢指定頂點、初始化visited標誌 #endregion #region 巢狀類:表頭節點與表節點定義 #endregion }
首先,我們使用了一個動態集合List來代替陣列儲存Vertex的集合,預設容量為10,且不需要陣列儲存空間不夠的情況,簡化了操作。其次,我們要定義一些基本方法,如新增頂點、新增邊。還要定義一些輔助方法,如判斷是否包含某個元素等(詳見完整程式碼檔案)。最後,我們再實現圖的一些遍歷演算法,如深度優先遍歷與廣度優先遍歷(本篇不作介紹,下一篇再介紹)。
3.2 基本方法實現
(1)新增一個頂點
/// <summary> /// 新增一個頂點 /// </summary> /// <param name="item">頂點元素data</param> public void AddVertex(T item) { if (Contains(item)) { throw new ArgumentException("添加了重複的頂點!"); } Vertex<T> newVertex = new Vertex<T>(item); items.Add(newVertex); }View Code
就是往集合裡邊加入新元素;
(2)新增一條邊
這裡需要分為兩種情況,一種是新增無向圖的邊,這時無向圖的兩個頂點都需要記錄邊的資訊。另一種則是新增有向圖的邊,這時只需要一條記錄;
①無向圖
/// <summary> /// 新增一條無向邊 /// </summary> /// <param name="from">頭頂點data</param> /// <param name="to">尾頂點data</param> /// <param name="weight">權值</param> public void AddEdge(T from, T to) { Vertex<T> fromVertex = Find(from); if (fromVertex == null) { throw new ArgumentException("頭頂點不存在!"); } Vertex<T> toVertex = Find(to); if (toVertex == null) { throw new ArgumentException("尾頂點不存在!"); } // 無向圖的兩個頂點都需要記錄邊的資訊 AddDirectedEdge(fromVertex, toVertex); AddDirectedEdge(toVertex, fromVertex); }View Code
這裡可以看到這兩句程式碼,對應的兩個頂點都記錄了邊的資訊。
// 無向圖的兩個頂點都需要記錄邊的資訊 AddDirectedEdge(fromVertex, toVertex); AddDirectedEdge(toVertex, fromVertex);
②有向圖
/// <summary> /// 新增一條有向邊 /// </summary> /// <param name="from">頭結點data</param> /// <param name="to">尾節點data</param> public void AddDirectedEdge(T from, T to) { Vertex<T> fromVertex = Find(from); if (fromVertex == null) { throw new ArgumentException("頭頂點不存在!"); } Vertex<T> toVertex = Find(to); if (toVertex == null) { throw new ArgumentException("尾頂點不存在!"); } AddDirectedEdge(fromVertex, toVertex); }View Code
③如何新增邊
在實現中,無論是無線圖還是有向圖都是新增的有向邊,只不過無向圖是添加了兩條有向邊:
/// <summary> /// 新增一條有向邊 /// </summary> /// <param name="fromVertex">頭頂點</param> /// <param name="toVertex">尾頂點</param> private void AddDirectedEdge(Vertex<T> fromVertex, Vertex<T> toVertex) { if (fromVertex.firstEdge == null) { fromVertex.firstEdge = new Node(toVertex); } else { Node temp = null; Node node = fromVertex.firstEdge; do { // 檢查是否添加了重複邊 if (node.adjvex.data.Equals(toVertex.data)) { throw new ArgumentException("添加了重複的邊!"); } temp = node; node = node.next; } while (node != null); Node newNode = new Node(toVertex); temp.next = newNode; } }View Code
(3)列印每個頂點及其鄰接點的資訊
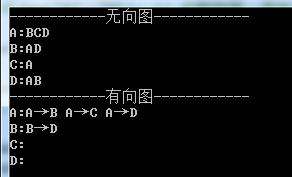
/// <summary> /// 列印列印每個頂點和它的鄰接點 /// </summary> /// <param name="isDirectedGraph">是否是有向圖</param> public string GetGraphInfo(bool isDirectedGraph = false) { StringBuilder sb = new StringBuilder(); foreach (Vertex<T> v in items) { sb.Append(v.data.ToString() + ":"); if (v.firstEdge != null) { Node temp = v.firstEdge; while (temp != null) { if (isDirectedGraph) { sb.Append(v.data.ToString() + "→" + temp.adjvex.data.ToString() + " "); } else { sb.Append(temp.adjvex.data.ToString()); } temp = temp.next; } } sb.Append("\r\n"); } return sb.ToString(); }View Code
這裡判斷了是否是有向圖,如果是有向圖則顯示A→B的形式,如果是無向圖則顯示A:B的形式。
3.3 基本功能測試
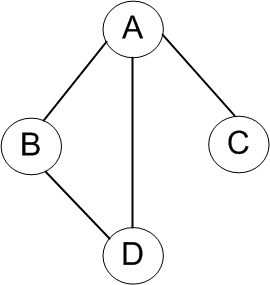

這裡我們對基本功能做一下測試,分為無向圖和有向圖,首先插入頂點及對應邊,然後列印頂點及其鄰接表的資訊,要構造的無向圖與有向圖如上面兩張圖所示,測試程式碼如下所示:
static void MyAdjacencyListTest() { Console.WriteLine("------------無向圖------------"); MyAdjacencyList<string> adjList = new MyAdjacencyList<string>(); // 新增頂點 adjList.AddVertex("A"); adjList.AddVertex("B"); adjList.AddVertex("C"); adjList.AddVertex("D"); //adjList.AddVertex("D"); // 會報異常:添加了重複的節點 // 新增無向邊 adjList.AddEdge("A", "B"); adjList.AddEdge("A", "C"); adjList.AddEdge("A", "D"); adjList.AddEdge("B", "D"); //adjList.AddEdge("B", "D"); // 會報異常:添加了重複的邊 Console.Write(adjList.GetGraphInfo()); Console.WriteLine("------------有向圖------------"); MyAdjacencyList<string> dirAdjList = new MyAdjacencyList<string>(); // 新增頂點 dirAdjList.AddVertex("A"); dirAdjList.AddVertex("B"); dirAdjList.AddVertex("C"); dirAdjList.AddVertex("D"); // 新增有向邊 dirAdjList.AddDirectedEdge("A", "B"); dirAdjList.AddDirectedEdge("A", "C"); dirAdjList.AddDirectedEdge("A", "D"); dirAdjList.AddDirectedEdge("B", "D"); Console.Write(dirAdjList.GetGraphInfo(true)); }
執行結果如下圖所示:
附件下載
參考資料
(1)程傑,《大話資料結構》
(2)陳廣,《資料結構(C#語言描述)》
(3)段恩澤,《資料結構(C#語言版)》
作者:周旭龍
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連結。
相關推薦
資料結構基礎溫故-6.查詢(上):基本查詢與樹表查詢
只要你開啟電腦,就會涉及到查詢技術。如炒股軟體中查股票資訊、硬碟檔案中找照片、在光碟中搜DVD,甚至玩遊戲時在記憶體中查詢攻擊力、魅力值等資料修改用來作弊等,都要涉及到查詢。當然,在網際網路上查詢資訊就更加是家常便飯。查詢是計算機應用中最常用的操作之一,也是許多程式中最耗時的一部分,查詢方法的優劣對於系統的執
資料結構基礎溫故-6.查詢(下):雜湊表
雜湊(雜湊)技術既是一種儲存方法,也是一種查詢方法。然而它與線性表、樹、圖等結構不同的是,前面幾種結構,資料元素之間都存在某種邏輯關係,可以用連線圖示表示出來,而雜湊技術的記錄之間不存在什麼邏輯關係,它只與關鍵字有關聯。因此,雜湊主要是面向查詢的儲存結構。雜湊技術最適合的求解問題是查詢與給定值相等的記錄。
資料結構基礎溫故-5.圖(中):圖的遍歷演算法
上一篇我們瞭解了圖的基本概念、術語以及儲存結構,還對鄰接表結構進行了模擬實現。本篇我們來了解一下圖的遍歷,和樹的遍歷類似,從圖的某一頂點出發訪問圖中其餘頂點,並且使每一個頂點僅被訪問一次,這一過程就叫做圖的遍歷(Traversing Graph)。如果只訪問圖的頂點而不關注邊的資訊,那麼圖的遍歷十分簡單,使用
資料結構基礎溫故-5.圖(中):最小生成樹演算法
圖的“多對多”特性使得圖在結構設計和演算法實現上較為困難,這時就需要根據具體應用將圖轉換為不同的樹來簡化問題的求解。 一、生成樹與最小生成樹 1.1 生成樹 對於一個無向圖,含有連通圖全部頂點的一個極小連通子圖成為生成樹(Spanning Tree)。其本質就是從連通圖任一頂點出發進行遍歷操作所經過
資料結構基礎溫故-5.圖(上):圖的基本概念
前面幾篇已經介紹了線性表和樹兩類資料結構,線性表中的元素是“一對一”的關係,樹中的元素是“一對多”的關係,本章所述的圖結構中的元素則是“多對多”的關係。圖(Graph)是一種複雜的非線性結構,在圖結構中,每個元素都可以有零個或多個前驅,也可以有零個或多個後繼,也就是說,元素之間的關係是任意的。現實生活中的很多
資料結構基礎溫故-5.圖(下):最短路徑
圖的最重要的應用之一就是在交通運輸和通訊網路中尋找最短路徑。例如在交通網路中經常會遇到這樣的問題:兩地之間是否有公路可通;在有多條公路可通的情況下,哪一條路徑是最短的等等。這就是帶權圖中求最短路徑的問題,此時路徑的長度不再是路徑上邊的數目總和,而是路徑上的邊所帶權值的和。帶權圖分為無向帶權圖和有向帶權圖,但如
資料結構基礎之圖(上):圖的基本概念
轉自:http://www.cnblogs.com/edisonchou/p/4672188.html 圖(上):圖的基本概念 前面幾篇已經介紹了線性表和樹兩類資料結構,線性表中的元素是“一對一”的關係,樹中的元素是“一對多”的關係,本章所述的圖結構中的元素則是“多對多”的
資料結構基礎溫故-1.線性表(中)
在上一篇中,我們學習了線性表最基礎的表現形式-順序表,但是其存在一定缺點:必須佔用一整塊事先分配好的儲存空間,在插入和刪除操作上需要移動大量元素(即操作不方便),於是不受固定儲存空間限制並且可以進行比較快捷地插入和刪除操作的連結串列橫空出世,所以我們就來複習一下連結串列。 一、單鏈表基礎 1.1 單鏈表的
資料結構基礎溫故-4.樹與二叉樹(下)
上面兩篇我們瞭解了樹的基本概念以及二叉樹的遍歷演算法,還對二叉查詢樹進行了模擬實現。數學表示式求值是程式設計語言編譯中的一個基本問題,表示式求值是棧應用的一個典型案例,表示式分為字首、中綴和字尾三種形式。這裡,我們通過一個四則運算的應用場景,藉助二叉樹來幫助求解表示式的值。首先,將表示式轉換為二叉樹,然後通過
資料結構基礎溫故-4.樹與二叉樹(中)
在上一篇中,我們瞭解了樹的基本概念以及二叉樹的基本特點和程式碼實現,還用遞迴的方式對二叉樹的三種遍歷演算法進行了程式碼實現。但是,由於遞迴需要系統堆疊,所以空間消耗要比非遞迴程式碼要大很多。而且,如果遞迴深度太大,可能系統撐不住。因此,我們使用非遞迴(這裡主要是迴圈,迴圈方法比遞迴方法快, 因為迴圈避免了一系
資料結構基礎溫故-4.樹與二叉樹(上)
前面所討論的線性表元素之間都是一對一的關係,今天我們所看到的結構各元素之間卻是一對多的關係。樹在計算機中有著廣泛的應用,甚至在計算機的日常使用中,也可以看到樹形結構的身影,如下圖所示的Windows資源管理器和應用程式的選單都屬於樹形結構。樹形結構是一種典型的非線性結構,除了用於表示相鄰關係外,還可以表示層次
資料結構基礎溫故-1.線性表(下)
在上一篇中,我們瞭解了單鏈表與雙鏈表,本次將單鏈表中終端結點的指標端由空指標改為指向頭結點,就使整個單鏈表形成一個環,這種頭尾相接的單鏈表稱為單迴圈連結串列,簡稱迴圈連結串列(circular linked list)。 一、迴圈連結串列基礎 1.1 迴圈連結串列節點結構 迴圈連結串列和單鏈表的
資料結構基礎之圖(中):圖的遍歷演算法
轉自:http://www.cnblogs.com/edisonchou/p/4676876.html 圖(中):圖的遍歷演算法 上一篇我們瞭解了圖的基本概念、術語以及儲存結構,還對鄰接表結構進行了模擬實現。本篇我們來了解一下圖的遍歷,和樹的遍歷類似,從圖的某一頂點出發訪問
資料結構基礎溫故-2.棧
現實生活中的事情往往都能總結歸納成一定的資料結構,例如餐館中餐盤的堆疊和使用,羽毛球筒裡裝的羽毛球等都是典型的棧結構。而在.NET中,值型別線上程棧上進行分配,引用型別在託管堆上進行分配,本文所說的“棧”正是這種資料結構。棧和佇列都是常用的資料結構,它們的邏輯結構與線性表相通,不同之處則在於操作受某種特殊限制
資料結構基礎溫故-3.佇列
在日常生活中,佇列的例子比比皆是,例如在車展排隊買票,排在隊頭的處理完離開,後來的必須在隊尾排隊等候。在程式設計中,佇列也有著廣泛的應用,例如計算機的任務排程系統、為了削減高峰時期訂單請求的訊息佇列等等。與棧類似,佇列也是屬於操作受限的線性表,不過佇列是隻允許在一端進行插入,在另一端進行刪除。在其他資料結構如
資料結構基礎溫故-7.排序
排序(Sorting)是計算機內經常進行的一種操作,其目的是將一組“無序”的記錄序列調整為按關鍵字“有序”的記錄序列。如何進行排序,特別是高效率地進行排序時計算機工作者學習和研究的重要課題之一。排序有內部排序和外部排序之分,若整個排序過程不需要訪問外存便能完成,則稱此類排序為內部排序,反之則為外部排序。本篇主
15-二分查詢(上):圖和用最省記憶體的方式實現快速查詢功能?
今天我們講一種針對有序資料集合的查詢演算法:二分查詢(Binary Search)演算法,也叫折半查詢演算法。二分查詢的思想非常簡單,很多非計算機專業的同學很容易就能理解,但是看似越簡單的東西往往越難掌握好,想要靈活應用就更加困難。 老規矩,我們還是來看一道思考
iptables(1):iptables 基本概念
blank target 什麽 com http href 概念 www. lan 1. 什麽是iptables? iptables(1):iptables 基本概念
目標定位和檢測系列(1):一些基本概念
最近開始學習深度學習中的定位和檢測任務。本來打算直接看論文,卻發現文章中的的很多基本概念都搞不清楚,於是就自己先梳理了一些定位和檢測任務的基本概念。(內容主要來自斯坦福大學的CS231課程、吳恩達的deeplearning.ai卷積部分,這兩門課程都可以在網易雲
ElasticStack學習(三):ElasticSearch基本概念
1、文件 1)ElasticSearch是面向文件的,文件是所有可搜尋資料的最小單位。例如: a)日誌檔案中的日誌項; b)一張唱片的詳細資訊; c)一篇文章中的具體內容; 2)在ElasticSearch中,文件會被序列化成Json格式: a)Json物