
圖解機器學習:神經網路和 TensorFlow 的文字分類
開發人員經常說,如果你想開始機器學習,你應該首先學習演算法。但是我的經驗則不是。
我說你應該首先了解:應用程式如何工作。一旦瞭解了這一點,深入探索演算法的內部工作就會變得更加容易。
那麼,你如何 開發直覺學習,並實現理解機器學習這個目的?一個很好的方法是建立機器學習模型。
假設您仍然不知道如何從頭開始建立所有這些演算法,您可以使用一個已經為您實現所有這些演算法的庫。那個庫是 TensorFlow。
在本文中,我們將建立一個機器學習模型來將文字分類到類別中。我們將介紹以下主題:
- TensorFlow 的工作原理
- 什麼是機器學習模型
- 什麼是神經網路
- 神經網路如何學習
- 如何操作資料並將其傳遞給神經網路
- 如何執行模型並獲得預測結果
你可能會學到很多新東西,所以讓我們開始吧!
TensorFlow
TensorFlow 是一個機器學習的開源庫,由 Google 首創。庫的名稱幫助我們理解我們怎樣使用它:tensors 是通過圖的節點流轉的多維陣列。
tf.Graph
在 TensorFlow 中的每一個計算都表示為資料流圖,這個圖有兩類元素:
- 一類 tf.Operation,表示計算單元
- 一類 tf.Tensor,表示資料單元
要檢視這些是怎麼工作的,你需要建立這個資料流圖:
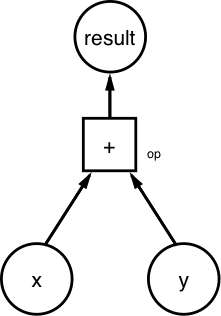
(計算x+y的圖)
你需要定義 x = [1,3,6] 和 y = [1,1,1]。由於圖用 tf.Tensor 表示資料單元,你需要建立常量 Tensors:
| 123 | importtensorflow astfx=tf.constant([1,3,6])y=tf.constant([1,1,1]) |
現在你將定義操作單元:
Python| 1234 | importtensorflow astfx=tf.constant([1,3,6])y=tf.constant([1,1,1])op=tf.add(x,y) |
你有了所有的圖元素。現在你需要構建圖:
Python| 123456 | importtensorflow astfmy_graph=tf.Graph()withmy_graph.as_default():x=tf.constant([1,3,6])y=tf.constant([1,1,1])op=tf.add(x,y) |
這是 TensorFlow 工作流的工作原理:你首先要建立一個圖,然後你才能計算(實際上是用操作‘執行’圖節點)。你需要建立一個 tf.Session 執行圖。
tf.Session
tf.Session 物件封裝了 Operation 物件的執行環境。Tensor 物件是被計算過的(從文件中)。為了做到這些,我們需要在 Session 中定義哪個圖將被使用到:
Python| 123456 | importtensorflow astfmy_graph=tf.Graph()withtf.Session(graph=my_graph)assess:x=tf.constant([1,3,6])y=tf.constant([1,1,1])op=tf.add(x,y) |
為了執行操作,你需要使用方法 tf.Session.run()。這個方法通過執行必要的圖段去執行每個 Operation 物件並通過引數 fetches 計算每一個 Tensor 的值的方式執行 TensorFlow 計算的一’步’:
Python| 123456789 | importtensorflow astfmy_graph=tf.Graph()withtf.Session(graph=my_graph)assess:x=tf.constant([1,3,6])y=tf.constant([1,1,1])op=tf.add(x,y)result=sess.run(fetches=op)print(result)>>>[247] |
預測模型
現在你知道了 TensorFlow 的工作原理,那麼你得知道怎樣建立預測模型。簡而言之
機器學習演算法+資料=預測模型
構建模型的過程就是這樣:
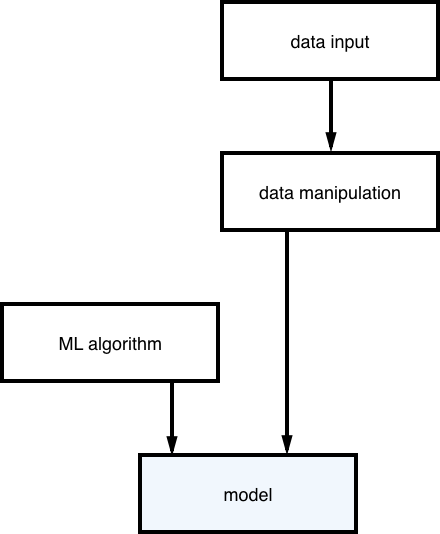
(構建預測模型的過程)
正如你能看到的,模型由資料“訓練過的”機器學習演算法組成。當你有了模型,你就會得到這樣的結果:

(預測工作流)
你建立的模型的目的是對文字分類,我們定義了:
input: text, result: category
我們有一個使用已經標記過的文字(每個文字都有了它屬於哪個分類的標記)訓練的資料集。在機器學習中,這種任務的型別是被稱為監督學習。
“我們知道正確的答案。該演算法迭代的預測訓練資料,並由老師糾正
” — Jason Brownlee
你會把資料分成類,因此它也是一個分類任務。
為了建立這個模型,我們將會用到神經網路。
神經網路
神經網路是一個計算模型(一種描述使用機器語言和數學概念的系統的方式)。這些系統是自主學習和被訓練的,而不是明確程式設計的。
神經網路是也從我們的中樞神經系統受到的啟發。他們有與我們神經相似的連線節點。
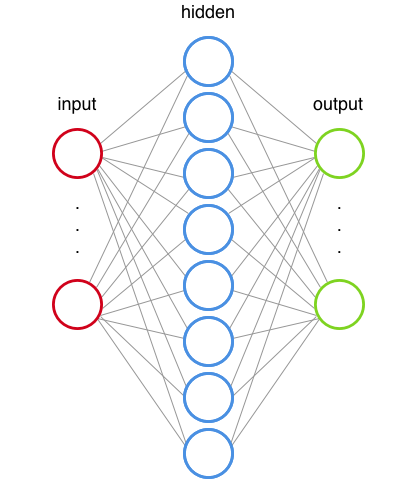
(一個神經網路)
感知器是第一個神經網路演算法。這篇文章 很好地解釋了感知器的內部工作原理(“人工神經元內部” 的動畫非常棒)。
為了理解神經網路的工作原理,我們將會使用 TensorFlow 建立一個神經網路架構。在這個例子中,這個架構被 Aymeric Damien 使用過。
神經網路架構
神經網路有兩個隱藏層(你得選擇 網路會有多少隱藏層,這是結構設計的一部分)。每一個隱藏層的任務是 把輸入的東西轉換成輸出層可以使用的東西。
隱藏層 1
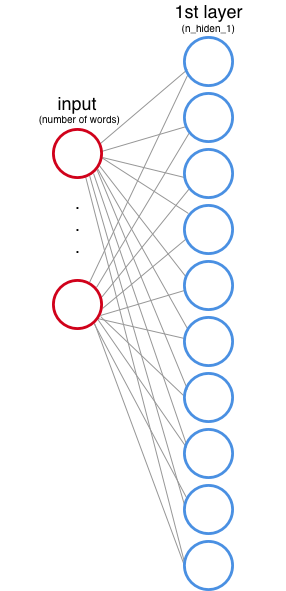
(輸入層和第一個隱藏層)
你也需要定義第一個隱藏層會有多少節點。這些節點也被稱為特徵或神經元,在上面的例子中我們用每一個圓圈表示一個節點。
輸入層的每個節點都對應著資料集中的一個詞(之後我們會看到這是怎麼執行的)
如 這裡 所述,每個節點(神經元)乘以一個權重。每個節點都有一個權重值,在訓練階段,神經網路會調整這些值以產生正確的輸出(過會,我們將會學習更多關於這個的資訊)
除了乘以沒有輸入的權重,網路也會增加一個誤差 (在神經網路中誤差的角色)。
在你的架構中,將輸入乘以權重並將值與偏差相加,這些資料也要通過啟用函式傳遞。這個啟用函式定義了每個節點的最終輸出。比如說:想象一下,每一個節點是一盞燈,啟用函式決定燈是否會亮。
有很多型別的啟用函式。你將會使用 Rectified Linear Unit (ReLu)。這個函式是這樣定義的:
f(x) = max(0,x) [輸出 x 或者 0(零)中最大的數]
例如:如果 x = -1, f(x) = 0(zero); 如果 x = 0.7, f(x) = 0.7.
隱藏層 2
第二個隱藏層做的完全是第一個隱藏層做的事情,但現在第二層的輸入是第一層的輸出。
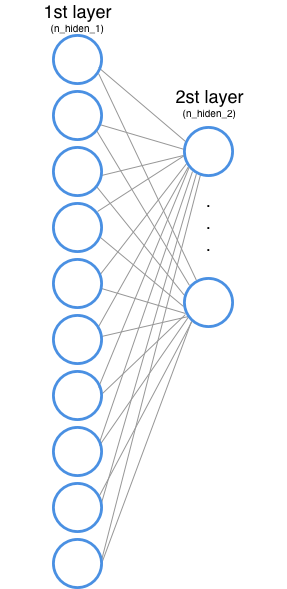
(第一和第二隱藏層)
輸出層
現在終於到了最後一層,輸出層。你將會使用 One-Hot 編碼 得到這個層的結果。在這個編碼中,只有一個位元的值是 1,其他位元的值都是 0。例如,如果我們想對三個分類編碼(sports, space 和computer graphics)編碼:
Python| 1234567 | +-------------------+-----------+|category|value|+-------------------|-----------+|sports|001||space|010||computer graphics|100||-------------------|-----------| |
因此輸出節點的編號是輸入的資料集的分類的編號。
輸出層的值也要乘以權重,並我們也要加上誤差,但是現在啟用函式不一樣。
你想用分類對每一個文字進行標記,並且這些分類相互獨立(一個文字不能同時屬於兩個分類)。考慮到這點,你將使用 Softmax 函式而不是 ReLu 啟用函式。這個函式把每一個完整的輸出轉換成 0 和 1 之間的值,並且確保所有單元的和等於一。這樣,輸出將告訴我們每個分類中每個文字的概率。
Python| 123 | |1.20.46||0.9->[softmax]->0.34||0.40.20| |
現在有了神經網路的資料流圖。把我們所看到的都轉換為程式碼,結果是:
Python| 12345678910111213141516 | # Network Parametersn_hidden_1=10# 1st layer number of featuresn_hidden_2=5# 2nd layer number of featuresn_input=total_words# Words in vocabn_classes=3# Categories: graphics, space and baseballdefmultilayer_perceptron(input_tensor,weights,biases):layer_1_multiplication=tf.matmul(input_tensor,weights['h1'])layer_1_addition=tf.add(layer_1_multiplication,biases['b1'])layer_1_activation=tf.nn.relu(layer_1_addition)# Hidden layer with RELU activationlayer_2_multiplication=tf.matmul(layer_1_activation,weights['h2'])layer_2_addition=tf.add(layer_2_multiplication,biases['b2'])layer_2_activation=tf.nn.relu(layer_2_addition)# Output layer with linear activationout_layer_multiplication=tf.matmul(layer_2_activation,weights['out'])out_layer_addition=out_layer_multiplication+biases['out']returnout_layer_addition |
(我們將會在後面討論輸出層的啟用函式)
神經網路怎麼學習
就像我們前面看到的那樣,神經網路訓練時會更新權重值。現在我們將看到在 TensorFlow 環境下這是怎麼發生的。
tf.Variable
權重和誤差儲存在變數(tf.Variable)中。這些變數通過呼叫 run() 保持在圖中的狀態。在機器學習中我們一般通過 正太分佈 來啟動權重和偏差值。
Python| 12345678910 | weights={'h1':tf.Variable(tf.random_normal([n_input,n_hidden_1])),'h2':tf.Variable(tf.random_normal([n_hidden_1,n_hidden_2])),'out':tf.Variable(tf.random_normal([n_hidden_2,n_classes]))}biases={'b1':tf.Variable(tf.random_normal([n_hidden_1])),'b2':tf.Variable(tf.random_normal([n_hidden_2])),'out':tf.Variable(tf.random_normal([n_classes]))} |
當我們第一次執行神經網路的時候(也就是說,權重值是由正態分佈定義的):
Python| 12345 | inputvalues:xweights:wbias:boutput values:zexpected values:expected |
為了知道網路是否正在學習,你需要比較一下輸出值(Z)和期望值(expected)。我們要怎麼計算這個的不同(損耗)呢?有很多方法去解決這個問題。因為我們正在進行分類任務,測量損耗的最好的方式是 交叉熵誤差。
James D. McCaffrey 寫了一個精彩的解釋,說明為什麼這是這種型別任務的最佳方法。
通過 TensorFlow 你將使用 tf.nn.softmax_cross_entropy_with_logits() 方法計算交叉熵誤差(這個是 softmax 啟用函式)並計算平均誤差 (tf.reduced_mean())。
Python| 12345 | # Construct modelprediction=multilayer_perceptron(input_tensor,weights,biases)# Define lossentropy_loss=tf.nn.softmax_cross_entropy_with_logits(logits=prediction,labels=output_tensor)loss=tf.reduce_mean(entropy_loss) |
你希望通過權重和誤差的最佳值,以便最小化輸出誤差(實際得到的值和正確的值之間的區別)。要做到這一點,將需使用 梯度下降法。更具體些是,需要使用 隨機梯度下降。
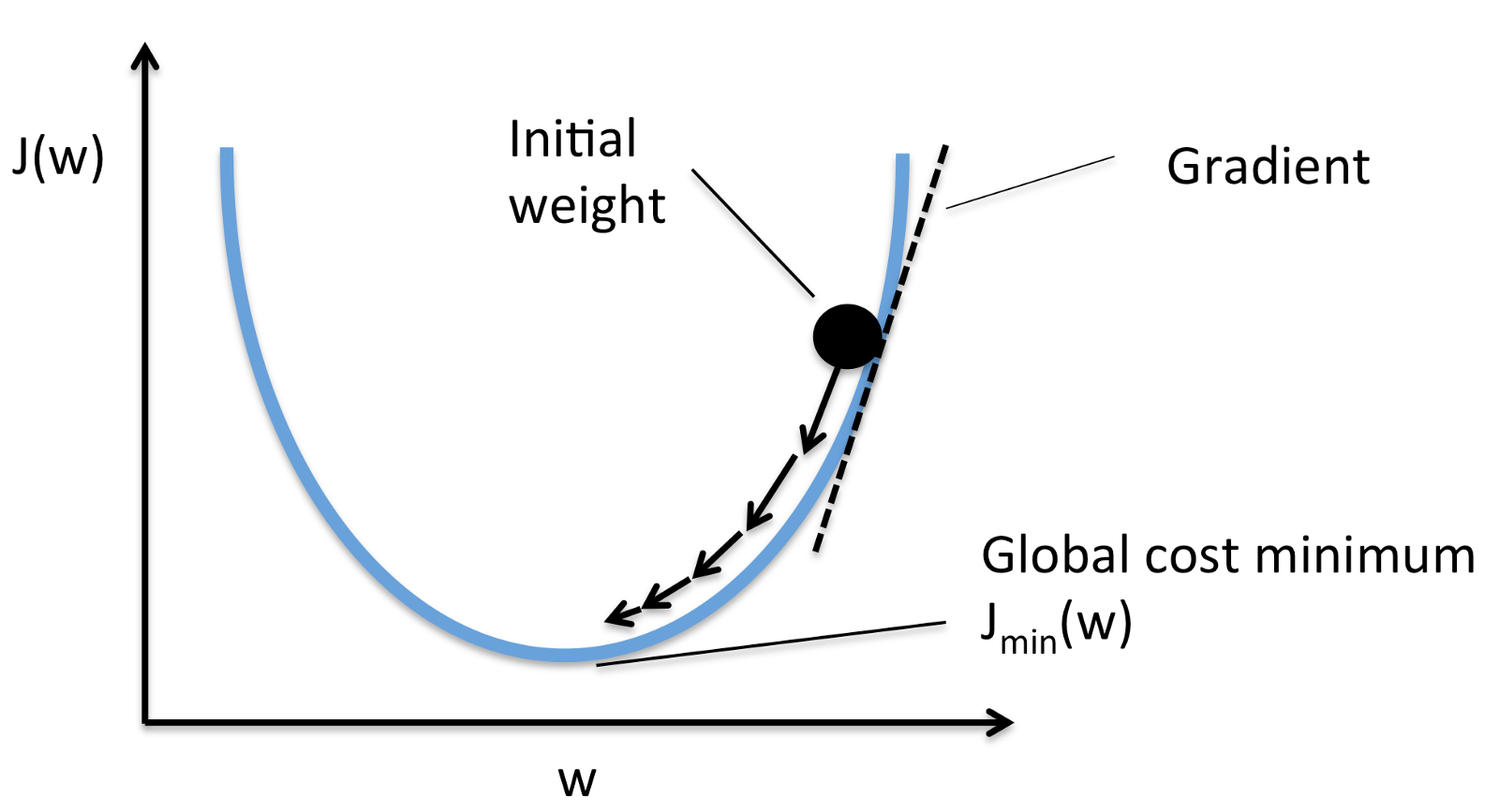
為了計算梯度下降,將要使用 Adaptive Moment Estimation (Adam)。要在 TensorFlow 中使用此演算法,需要傳遞 learning_rate 值,該值可確定值的增量步長以找到最佳權重值。
方法 tf.train.AdamOptimizer(learning_rate).minimize(loss) 是一個 語法糖,它做了兩件事情:
- compute_gradients(loss, <list of variables>)
- apply_gradients(<list of variables>)
這個方法用新的值更新了所有的 tf.Variables ,因此我們不需要傳遞變數列表。現在你有了訓練網路的程式碼: