
SSD詳解
論文題目:SSD: Single Shot MultiBox Detector
論文連結:論文連結
論文程式碼:Caffe程式碼點選此處
This results in a significant improvement in speed for high-accuracy detection(59 FPS with mAP 74.3% on VOC2007 test, vs Faster-rcnn 7 FPS with mAP 73.2% or YOLO 45 FPS with mAP 63.4%)

圖1 SSD和其它演算法的效能比較
一、SSD網路總體架構

圖2 SSD網路架構(精簡版)
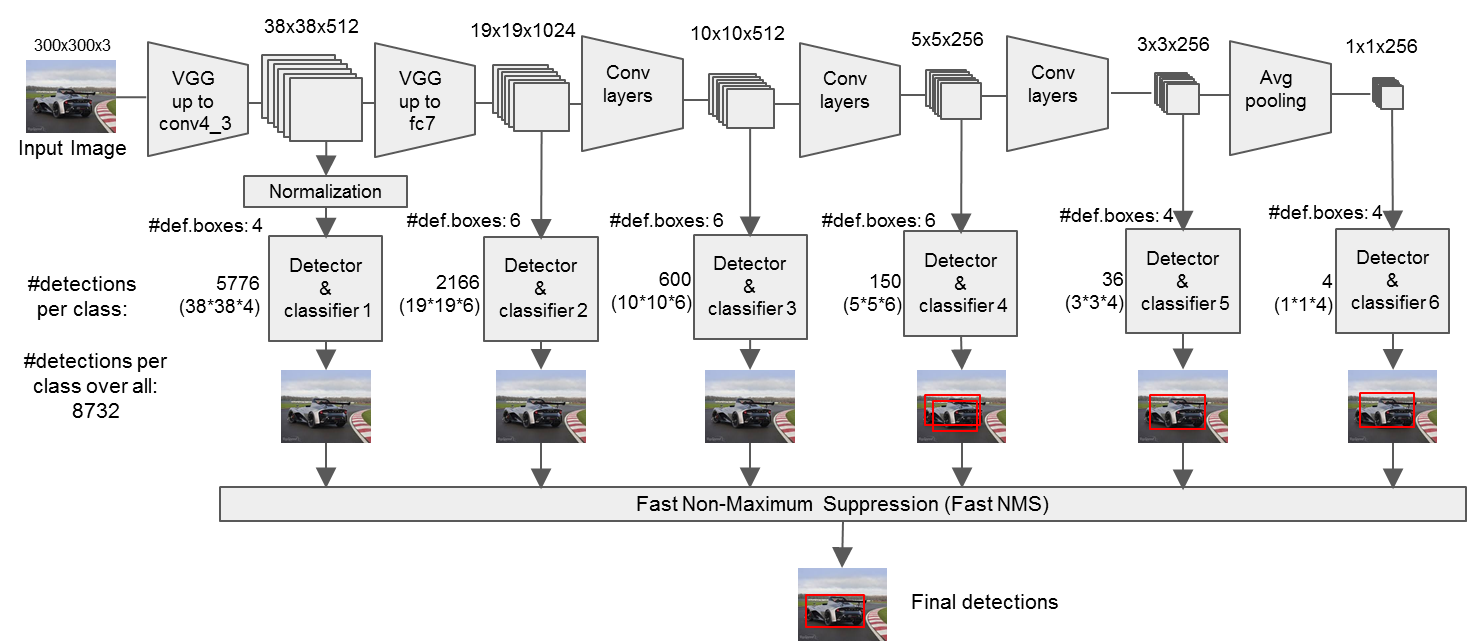
圖3 SSD網路架構(細節版)
SSD演算法步驟:
1. 輸入一幅圖片(200x200),將其輸入到預訓練好的分類網路中來獲得不同大小的特徵對映,修改了傳統的VGG16網路;
- 將VGG16的FC6和FC7層轉化為卷積層,如圖1上的Conv6和Conv7;
- 去掉所有的Dropout層和FC8層;
- 添加了Atrous演算法(hole演算法),參考該連結;
- 將Pool5從2x2-S2變換到3x3-S1;
2. 抽取Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2層的feature map,然後分別在這些feature map層上面的每一個點構造6個不同尺度大小的BB,然後分別進行檢測和分類,生成多個BB,如圖1下面的圖所示;
3. 將不同feature map獲得的BB結合起來,經過NMS(非極大值抑制)方法來抑制掉一部分重疊或者不正確的BB,生成最終的BB集合(即檢測結果);
SSD論文貢獻:
1. 引入了一種單階段的檢測器,比以前的演算法YOLO更準更快,並沒有使用RPN和Pooling操作;
2. 使用一個小的卷積濾波器應用在不同的feature map層從而預測BB的類別的BB偏差;
3. 可以在更小的輸入圖片中得到更好的檢測效果(相比Faster-rcnn);
4. 在多個數據集(PASCAL、VOC、COCO、ILSVRC)上面的測試結果表明,它可以獲得更高的mAp值;
二、 SSD演算法細節
1. 多尺度特徵對映
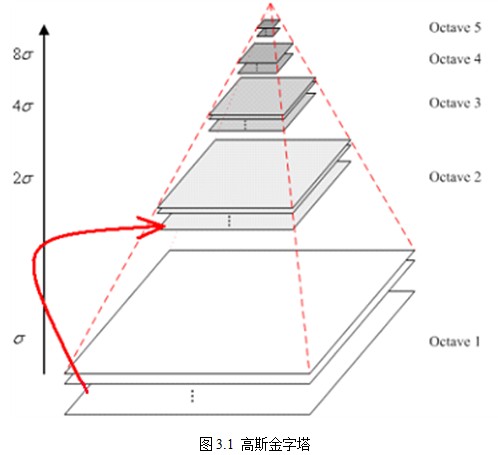
圖4 高斯金字塔
做CV的你應該對上圖很熟悉吧,對,沒錯,這就是SIFT演算法中的高斯金字塔,對任意的一幅圖片做一個高斯金字塔,你可以獲得不同解析度的圖片,模擬了人眼看東西時近大遠小的過程。這是針對整幅影象而言,那麼,對於patch而言,同樣也可以做這個操作。我們不僅可以在影象域做,當然我們也可以在特徵域做。
傳統演算法與SSD演算法的思路比較:
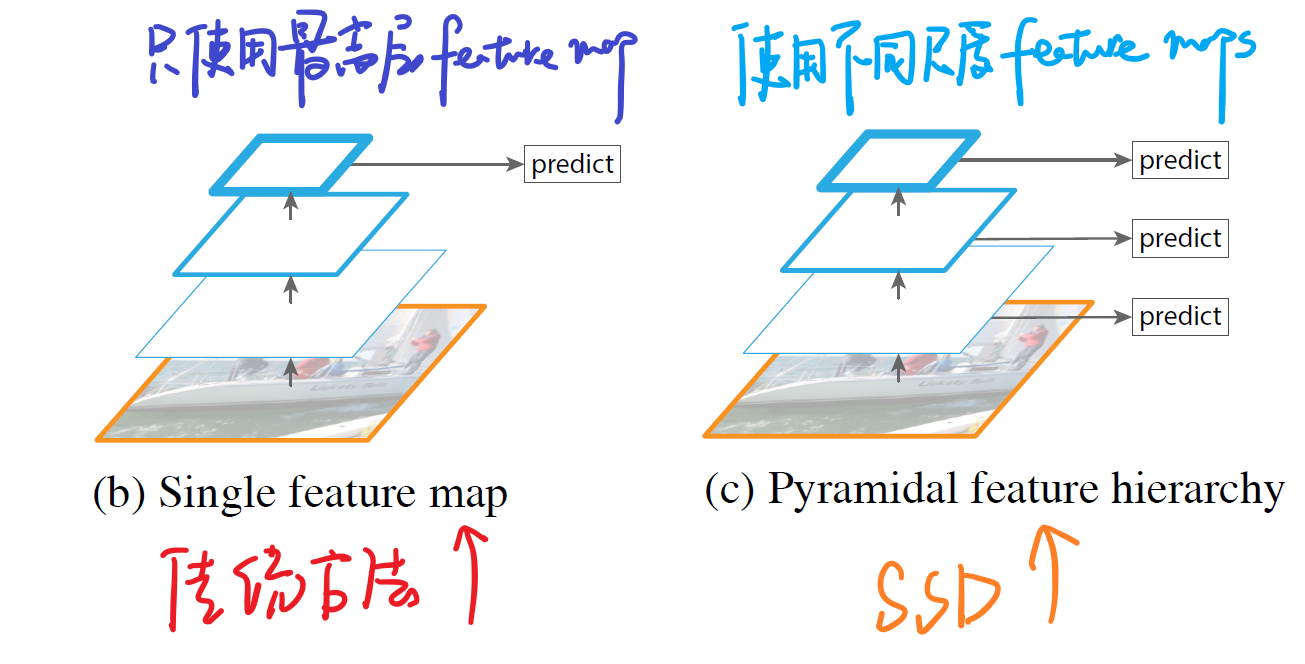
圖5 傳統做法和SSD做法的比較
如上圖所示,我們可以看到左邊的方法針對輸入的圖片獲取不同尺度的特徵對映,但是在預測階段僅僅使用了最後一層的特徵對映;而SSD不僅獲得不同尺度的特徵對映,同時在不同的特徵對映上面進行預測,它在增加運算量的同時可能會提高檢測的精度,因為它具有更多的可能性。
Faster-rcnn與SSD比較:
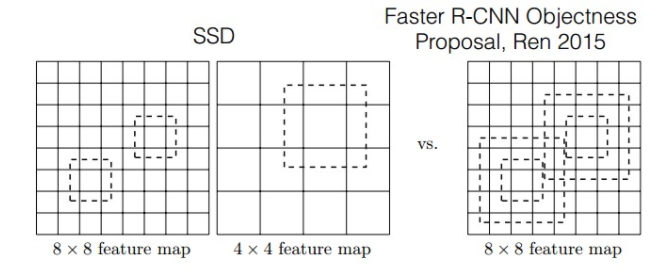
圖6 Faster-rcnn與SSD比較
如圖所示,對於BB的生成,Faster-rcnn和SSD有不同的策略,但是都是為了同一個目的,產生不同尺度,不同形狀的BB,用來檢測物體。對於Faster-rcnn而言,其在特定層的Feature map上面的每一點生成9個預定義好的BB,然後進行迴歸和分類操作進行初步檢測,然後進行ROI Pooling和檢測獲得相應的BB;而SSD則在不同的特徵層的feature map上的每個點同時獲取6個不同的BB,然後將這些BB結合起來,最後經過NMS處理獲得最後的BB。
原因剖析:

圖7 不同卷積層的feature map
如上圖所示,輸入一幅汽車的圖片,我們將其輸入到一個卷積神經網路中,在這期間,經歷了多個卷積層和池化層,我們可以看到在不同的卷積層會輸出不同大小的feature map(這是由於pooling層的存在,它會將圖片的尺寸變小),而且不同的feature map中含有不同的特徵,而不同的特徵可能對我們的檢測有不同的作用。總的來說,淺層卷積層對邊緣更加感興趣,可以獲得一些細節資訊,而深層網路對由淺層特徵構成的複雜特徵更感興趣,可以獲得一些語義資訊,對於檢測任務而言,一幅影象中的目標有複雜的有簡單的,對於簡單的patch我們利用淺層網路的特徵就可以將其檢測出來,對於複雜的patch我們利用深層網路的特徵就可以將其檢測出來,因此,如果我們同時在不同的feature map上面進行目標檢測,理論上面應該會獲得更好的檢測效果。
SSD多尺度特徵對映細節:
SSD演算法中使用到了conv4_3,conv_7,conv8_2,conv7_2,conv8_2,conv9_2,conv10_2,conv11_2這些大小不同的feature maps,其目的是為了能夠準確的檢測到不同尺度的物體,因為在低層的feature map,感受野比較小,高層的感受野比較大,在不同的feature map進行卷積,可以達到多尺度的目的。
2. Defalut box
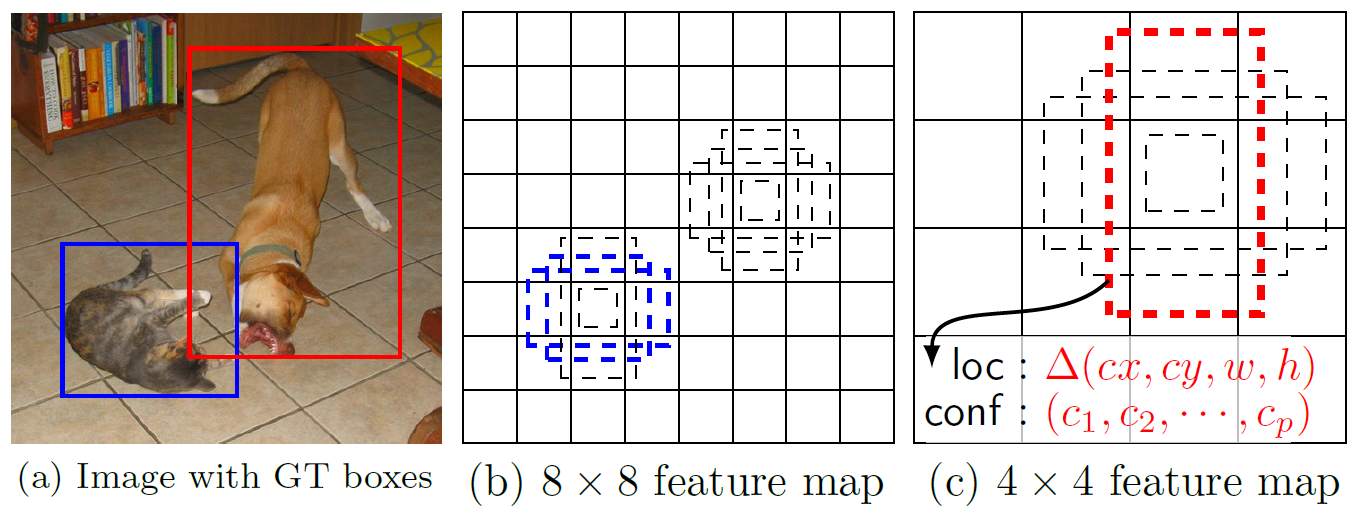
圖8 default bounding box
如上圖所示,在特徵圖的每個位置預測K個BB,對於每一個BB,預測C個類別得分,以及相對於Default box的4個偏移量值,這樣總共需要(C+4)* K個預測器,則在m*n的特徵圖上面將會產生(C+4)* K * m * n個預測值。
Defalut box分析:
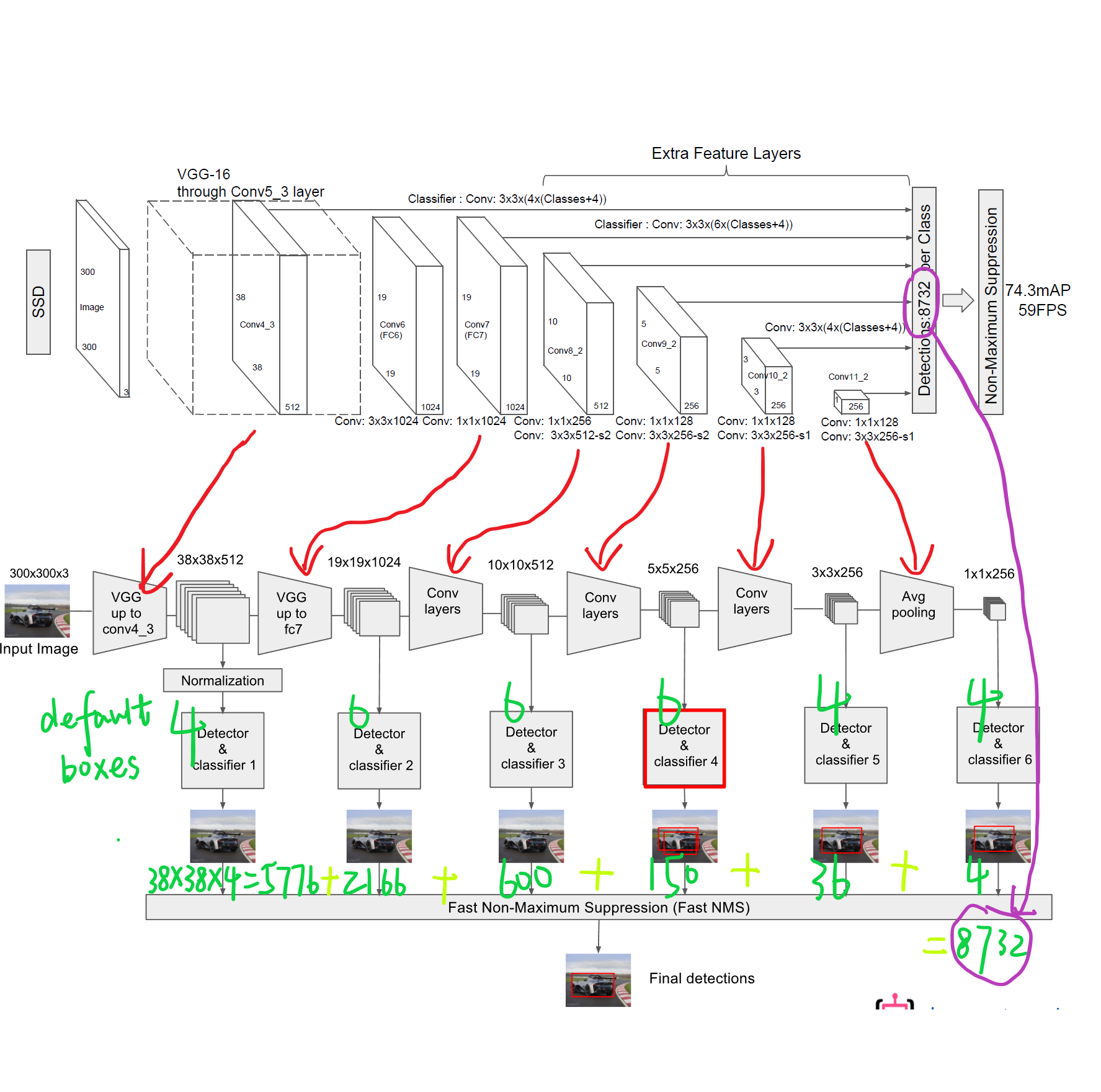
圖9 Defalut box分析
SSD中的Defalut box和Faster-rcnn中的anchor機制很相似。就是預設一些目標預選框,後續通過softmax分類+bounding box regression獲得真實目標的位置。對於不同尺度的feature map 上使用不同的Default boxes。如上圖所示,我們選取的feature map包括38x38x512、19x19x1024、10x10x512、5x5x256、3x3x256、1x1x256,Conv4_3之後的feature map預設的box是4個,我們在38x38的這個平面上的每一點上面獲得4個box,那麼我們總共可以獲得38x38x4=5776個;同理,我們依次將FC7、Conv8_2、Conv9_2、Conv10_2和Conv11_2的box數量設定為6、6、6、4、4,那麼我們可以獲得的box分別為2166、600、150、36、4,即我們總共可以獲得8732個box,然後我們將這些box送入NMS模組中,獲得最終的檢測結果。
以上的操作都是在特徵圖上面的操作,即我們在不同尺度的特徵圖上面產生很多的BB,如果將對映到原始影象中,我們會獲得一個密密麻麻的BB集合,如下圖所示:
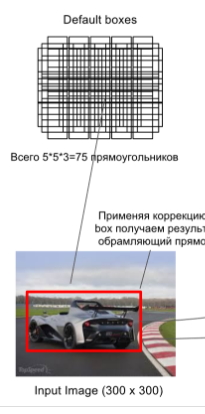
圖10 原始影象中生成的BB
Defalut box生成規則
- 以feature map上每個點的中點為中心(offset=0.5),生成一系列同心的Defalut box(然後中心點的座標會乘以step,相當於從feature map位置映射回原圖位置)
- 使用m(SSD300中m=6)個不同大小的feature map 來做預測,最底層的 feature map 的 scale 值為 Smin=0.2,最高層的為Smax=0.95,其他層通過下面的公式計算得到:
- 使用不同的ratio值,[1, 2, 3, 1/2, 1/3],通過下面的公式計算 default box 的寬度w和高度h
- 而對於ratio=0的情況,指定的scale如下所示,即總共有 6 中不同的 default box。
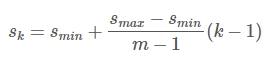
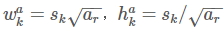
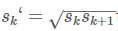
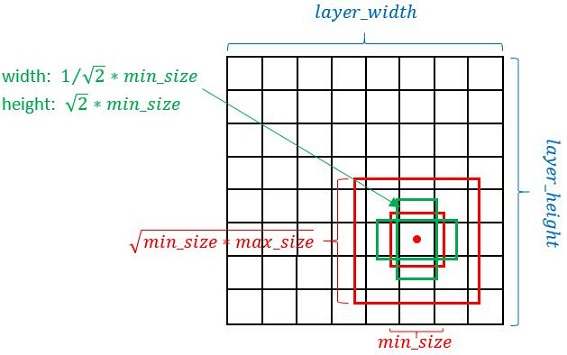
圖11 default box的計算
3. LOSS計算
與常見的 Object Detection模型的目標函式相同,SSD演算法的目標函式分為兩部分:計算相應的default box與目標類別的confidence loss以及相應的位置迴歸。
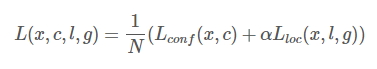
其中N是match到Ground Truth的default box數量;而alpha引數用於調整confidence loss和location loss之間的比例,默認alpha=1。
位置迴歸則是採用 Smooth L1 loss,目標函式為:
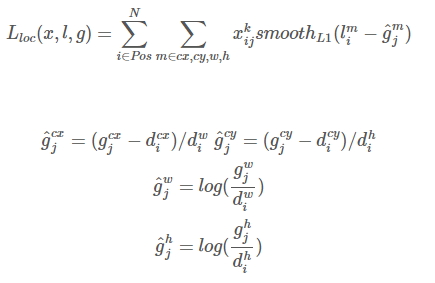
confidence loss是典型的softmax loss:
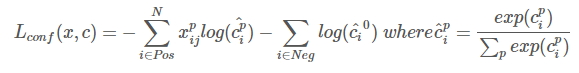
三、SSD提高精度的方法
1. 資料增強

圖12 資料增強效果
如上圖所示,不同於Faster-rcnn,SSD演算法使用了多種資料增強的方法,包括水平翻轉、裁剪、放大和縮小等。論文明確指出,資料增強可以明顯的提高演算法的效能。主要的目的是為了使得該演算法對輸入的不同大小和不同形狀的目標具有更好的魯棒性。直觀的理解是通過這個資料增強操作可以增加訓練樣本的個數,同時構造出更多的不同形狀和大小的目標,將其輸入到網路中,可以使得網路學習到更加魯棒的特徵。
2. Hard Negative Mining技術
一般情況下negative default boxes數量是遠大於positive default boxes數量,如果隨機選取樣本訓練會導致網路過於重視負樣本(因為抽取到負樣本的概率值更大一些),這會使得loss不穩定。因此需要平衡正負樣本的個數,我們常用的方法就是Hard Ngative Mining,即依據confidience score對default box進行排序,挑選其中confidience高的box進行訓練,將正負樣本的比例控制在positive:negative=1:3,這樣會取得更好的效果。如果我們不加控制的話,很可能會出現Sample到的所有樣本都是負樣本(即讓網路從這些負樣本中找正確目標,這顯然是不可以的),這樣就會使得網路的效能變差。
3. 匹配策略(即如何重多個default box中找到和ground truth最接近的box)
- 首先,尋找與每一個ground truth有最大的IoU的default box,這樣就能保證ground truth至少有default box匹配;
- SSD之後又將剩餘還沒有配對的default box與任意一個ground truth嘗試配對,只要兩者之間的IoU大於閾值(SSD 300 閾值為0.5),就認為match;
- 配對到ground truth的default box就是positive,沒有配對的default box就是negative。
總之,一個ground truth可能對應多個positive default box,而不再像MultiBox那樣只取一個IoU最大的default box。其他的作為負樣本(每個default box要麼是正樣本box要麼是負樣本box)。
4. Atrous Algothrim(獲得更加密集的得分對映)

圖13 Atrous Algothrim理解1
作用:既想利用已經訓練好的模型進行fine-tuning,又想改變網路結構得到更加dense的score map。
這個解決辦法就是採用Hole演算法。如下圖(a) (b)所示,在以往的卷積或者pooling中,一個filter中相鄰的權重作用在feature map上的位置都是物理上連續的。如上圖(c)所示,為了保證感受野不發生變化,某一層的stride由2變為1以後,後面的層需要採用hole演算法,具體來講就是將連續的連線關係是根據hole size大小變成skip連線的(圖(c)為了顯示方便直接畫在本層上了)。不要被(c)中的padding為2嚇著了,其實2個padding不會同時和一個filter相連。 pool4的stride由2變為1,則緊接著的conv5_1, conv5_2和conv5_3中hole size為2。接著pool5由2變為1, 則後面的fc6中hole size為4。
 圖14 Atrous Algothrim理解2
圖14 Atrous Algothrim理解2如上圖所示,Atrous Algothrim可以在提高feature map大小的同時提高接收場的大小,即可以獲得更加密集的score map。5. NMS(非極大值抑制)
在SSD演算法中,NMS至關重要,因為多個feature map 最後會產生大量的BB,然而在這些BB中存在著大量的錯誤的、重疊的、不準確的BB,這不僅造成了巨大的計算量,如果處理不好會影響演算法的效能。僅僅依賴於IOU(即預測的BB和GT的BB之間的重合率)是不現實的,IOU值設定的太大,可能就會丟失一部分檢測的目標,即會出現大量的漏檢情況;IOU值設定的太小,則會出現大量的重疊檢測,會大大影響檢測器的效能,因此IOU的選取也是一個經驗活,常用的是0.65,建議使用論文中作者使用的IOU值,因為這些值一般都是最優值。即在IOU處理掉大部分的BB之後,仍然會存在大量的錯誤的、重疊的、不準確的BB,這就需要NMS進行迭代優化。NMS的迭代過程可以看我以前的部落格。連結
四、SSD效能評估
1. 模組效能評估

表1 模組效能評估
觀察上圖可以得到如下的結論:
- 資料增強方法在SSD演算法中起到了關鍵性的作用,使得mAP從65.5變化到71.6,主要的原因可能是資料增強增加了樣本的個數,使得模型可以獲得更重更樣的樣本,即提高了樣本的多樣性,使得其具有更好的魯棒性,從而找到更接近GT的BB。
- [1/2,2]和[1/3, 3]box可以在一定程度上提升演算法的效能,主要的原因可能是這兩種box可以在一定程度上增加較大和較小的BB,可以更更加準確的檢測到較大和較小的目標,而且VOC資料集上面的目標一般都比較大。當然,更多的比例可以進一步提升演算法的效能。
- atrous演算法可以輕微提升演算法效能,但是其主要的作用是用來提速,論文中表明它可以提速20%。主要的原因可能是雖然該演算法可以獲得更大的feature map和接收場,但是由於SSD本身利用了多個feature map來獲取BB,BB的多樣性已經足夠,由於feature map擴大而多得到的BB可能是一些重複的,並沒有起到提升檢測效能的作用。
2. SSD加速的原因

表2 SSD的BB個數
如上圖所示,當Faster-rcnn的輸入解析度為1000x600時,產生的BB是6000個;當SSD300的輸入解析度為300x300時,產生的BB是8372個;當SSD512的輸入解析度為512x512時,產生的BB是24564個,大家像一個情況,當SSD的解析度也是1000x600時,會產生多少個BB呢?這個數字可能會很大!但是它卻說自己比Faster-rcnn和YOLO等演算法快很多,我們來分析分析原因。
- 原因1:首先SSD是一個單階段網路,只需要一個階段就可以輸出結果;而Faster-rcnn是一個雙階段網路,儘管Faster-rcnn的BB少很多,但是其需要大量的前向和反向推理(訓練階段),而且需要交替的訓練兩個網路;
- 原因2:Faster-rcnn中不僅需要訓練RPN,而且需要訓練Fast-rcnn,而SSD其實相當於一個優化了的RPN網路,不需要進行後面的檢測,僅僅前向推理就會花費很多時間;
- 原因3:YOLO網路雖然比SSD網路看起來簡單,但是YOLO網路中含有大量的全連線層,和FC層相比,CONV層具有更少的引數;同時YOLO獲得候選BB的操作比較費時;
- 原因4:SSD演算法中,調整了VGG網路的架構,將其中的FC層替換為CONV層,這一點會大大的提升速度,因為VGG中的FC層都需要大量的運算,有大量的引數,需要進行前向推理;
- 原因5:使用了atrous演算法,具體的提速原理還不清楚,不過論文中明確提出該演算法能夠提速20%。
- 原因6:SSD設定了輸入圖片的大小,它會將不同大小的圖片裁剪為300x300,或者512x512,和Faster-rcnn相比,在輸入上就會少很多的計算,不要說後面的啦,不快就怪啦!!!
3. SSD準確率評估
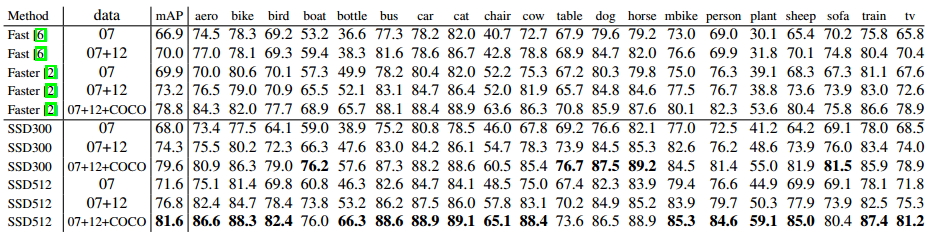
表3 VOC2007評估結果

表4 VOC2012評估結果
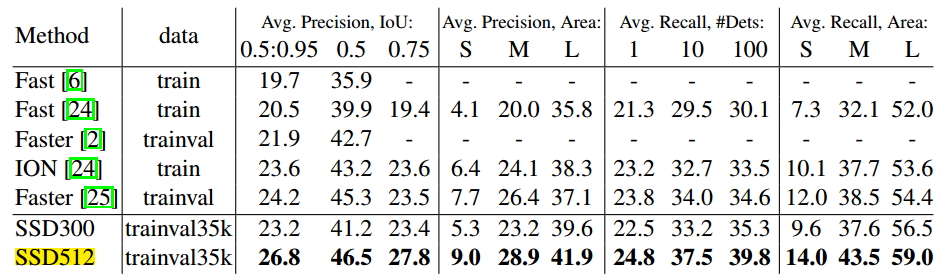
表5 COCO評估結果
分析:如上表所示,我們可以觀察到在不同資料集上面(VOC2007、VOC2012、COCO),SSD512都獲得了最佳的效能,在這裡進行了加粗。可以看出,Faster-rcnn和SSD相比,在IOU上面最少相差3個點。
當然這只是作者的結果,具體的結果你可以去測試。好了,我不喜歡在部落格裡寫這些東西,詳細的分析經仔細閱讀原文。
4. SSD演算法的優缺點
優點:執行速度超過YOLO,精度超過Faster-rcnn(一定條件下,對於稀疏場景的大目標而言)。
缺點:
- 需要人工設定prior box的min_size,max_size和aspect_ratio值。網路中default box的基礎大小和形狀不能直接通過學習獲得,而是需要手工設定。而網路中每一層feature使用的default box大小和形狀恰好都不一樣,導致除錯過程非常依賴經驗。(相比之下,YOLO2使用聚類找出大部分的anchor box形狀,這個思想能直接套在SSD上)
- 雖然採用了pyramdial feature hierarchy的思路,但是對小目標的recall依然一般,並沒有達到碾壓Faster RCNN的級別。可能是因為SSD使用conv4_3低階feature去檢測小目標,而低階特徵卷積層數少,存在特徵提取不充分的問題。
個人觀點:SSD到底好不好,需要根據你的應用和需求來講,真正合適你的應用場景的檢測演算法需要你去做效能驗證,比如你的場景是密集的包含多個小目標的,我很建議你用Faster-rcnn,針對特定的網路進行優化,也是可以加速的;如果你的應用對速度要求很苛刻,那麼肯定首先考慮SSD,至於那些測試集上的評估結果,和真實的資料還是有很大的差距,演算法的效能也需要進一步進行評估。
五、總結
SSD演算法是在YOLO的基礎上改進的單階段方法,通過融合多個feature map上的BB,在提高速度的同時提高了檢測的精度,效能超過了YOLO和Faster-rcnn。下圖是其檢測結果:

圖15 SSD檢測效果
參考文獻:
[1] SSD論文閱讀(Wei Liu——【ECCV2016】SSD Single Shot MultiBox Detector),相關連結
[2] 物體檢測論文-SSD和FPN,相關連結
[3] 目標檢測之YOLO,SSD,相關連結
[4] 論文閱讀:SSD: Single Shot MultiBox Detector,相關連結
[5] http://blog.csdn.net/u014380165/article/details/72824889,相關連結
注意事項:
[1] 該部落格是本人原創部落格,如果您對該部落格感興趣,想要轉載該部落格,請與我聯絡(qq郵箱:[email protected]),我會在第一時間回覆大家,謝謝大家。
[2] 由於個人能力有限,該部落格可能存在很多的問題,希望大家能夠提出改進意見。
[3] 如果您在閱讀本部落格時遇到不理解的地方,希望可以聯絡我,我會及時的回覆您,和您交流想法和意見,謝謝。
相關推薦
SSD詳解 + default box生成過程
在mxnet上面看李沐大神的視訊,自己看了SSD的paper裡面還是有些一知半解的東西,於是就用篇部落格記錄下來。文章中的圖和部分見解都來自於網路有些錯誤的圖已經修正,如有侵權,聯絡我刪除。 先放一張SSD演算法的模型圖。SSD採用不用卷積層的feature map進行綜合,將VGG16的
目標檢測與分割(三):SSD詳解
SSD github : https://github.com/weiliu89/caffe/tree/ssd SSD paper : https://arxiv.org/abs/1512.02325 SSD eccv2016 slide pdf : http://d
SSD詳解
論文題目:SSD: Single Shot MultiBox Detector論文連結:論文連結論文程式碼:Caffe程式碼點選此處This results in a significant improvement in speed for high-accuracy det
SSD(single shot multibox detector)算法及Caffe代碼詳解[轉]
作者 3.4 pdf 論文 做了 對比度調整 覆蓋 eccv 添加 這篇博客主要介紹SSD算法,該算法是最近一年比較優秀的object detection算法,主要特點在於采用了特征融合。 論文:SSD single shot multibox detector論文鏈接:h
ssd論文詳解
這篇部落格主要介紹SSD演算法,該演算法是最近一年比較優秀的object detection演算法,主要特點在於採用了特徵融合。 論文:SSD single shot multibox detector 論文連結:https://
SSD之OP詳解
當你買了一塊SSD,有沒有發現其實你得到的容量並不是SSD標稱的容量。比如你買的是128GB的SSD,你的得到的可使用容量肯定小於128GB,一般在120GB,甚至更小。到底是誰“偷”走了本應該屬於你的容量呢?經過不懈努力,警察蜀黍已經找到“真凶”,就是OP,全
SSD內部詳解
1、ssd的基本架構 直接上圖,給出一個簡單SSD的內部基本架構 從這個圖中可以看到FTL層主要是三個功能:地址對映表、損耗均衡、垃圾回收 地址對映表:顧名思義,把檔案系統的邏輯地址,對映到flash的實體地址上。 損耗均衡:進行損耗的排程,讓所有快的差不多一起寫壞,而不是其中某一塊
【文字檢測】SSD+Tensorflow 300&512 配置詳解
SSD_300_vgg和SSD_512_vgg weights下載連結【需要科學上網~】: Model Training data Testing data mAP FPS SSD-300 VGG-base
SSD 演算法詳解 及其 keras 實現(上)
https://blog.csdn.net/remanented/article/details/79943418 (看原文吧,我就不進行截圖了) 看了幾天的SSD的論文和keras實現的程式碼,對SSD也有了一定的理解,把這幾天的學習成果記錄下來。可能是因為之前學習了Mask R-CNN
【目標檢測】SSD演算法--損失函式的詳解(tensorflow實現)
SSD的損失函式包含用於分類的log loss 和用於迴歸的smooth L1,並對正負樣本比例進行了控制,可以提高優化速度和訓練結果的穩定性。 總的損失函式是分類和迴歸的誤差的帶權加和。α表示兩者的權重,N表示匹配到default box的數量 1 loc的損失函式
【深度學習SSD】——深刻解讀SSD tensorflow及原始碼詳解
<code class="language-python"># Copyright 2016 Paul Balanca. All Rights Reserved. # # Licensed under the Apache License, Version 2.0 (the "Lice
【文字檢測】SSD+Tensorflow 300&512 配置詳解
SSD_300_vgg和SSD_512_vgg weights下載連結【需要科學上網~】: Model Training data Testing data mAP FPS VOC07+12+COCO trainval VOC07
SSD(single shot multibox detector)演算法及Caffe程式碼詳解
這篇部落格主要介紹SSD演算法,該演算法是最近一年比較優秀的object detection演算法,主要特點在於採用了特徵融合。 演算法概述: 本文提出的SSD演算法是一種直接預測bounding box的座標和類別的object detection
雙硬碟(SSD+HDD)安裝雙系統(win10+ubuntu18.04)詳解
電腦配置不是很好,換電腦還沒到那個經濟水平,只能加記憶體條加固態硬碟。於是,目前電腦有三星(SSD 128G)和希捷(HDD 500G)。現在因為學習的需要,選擇了雙系統:Ubuntu18.04+win10。之前在一塊硬碟上安裝過雙系統,於是在安裝完wi
SSD演算法Tensorflow版詳解(一)
之前看了SSD的論文,但也只是僅僅停留在論文層面,這幾天在github上找到了一位大神在一年前用Tensorflow實現了SSD演算法。這幾天也抽空閱讀了下程式碼,主要分析了下幾個重要的模組,接下來做一個簡單的總結。SSD(Single Shot MultiBox Detec
SSD(single shot multibox detector)演算法及Caffe程式碼詳解(轉載)
這篇部落格主要介紹SSD演算法,該演算法是最近一年比較優秀的object detection演算法,主要特點在於採用了特徵融合。 演算法概述: 本文提出的SSD演算法是一種直接預測bounding box的座標和類別的object detection演算法,沒有生
SSD演算法詳解
SSD目標檢測 白裳丶 為啥你們只收藏不點贊? 161 人讚了該文章 SSD,全稱Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一種目標檢測演算法,截至目前是主要的檢測框架之一,相比Faster RCN
目標檢測之SSD:資料增強引數詳解
資料增強效果圖假設原圖輸入是一張640*480的圖片,這裡由於版面問題我放縮了圖片尺寸並且沒做mean subtract,由於最後會有resize引數導致輸出的圖片都會resize到300x300,但是主要看的是增強的效果,SSD中的資料增強的順序是:DistortImage
ssd原理及程式碼實現詳解
通過https://github.com/amdegroot/ssd.pytorch,結合論文https://arxiv.org/abs/1512.02325來理解ssd. ssd由三部分組成: base extra predict base原論文裡用的是vgg16去掉全連線層. base + extr
java Io 流類詳解
修改 文件目錄 != exe [] 深入 clas one fileinput 關於java 流類的復習;習慣性的復習按照圖結構一層層往下深入去了解去復習,最後通過代碼來實現感覺印象會更深刻一些; 關於 I/O流:IO可以理解為JAVA用來傳遞數據的管道