
mac下Hadoop、HDFS、Spark環境的安裝和搭建
環境搭建
相比之前搭建Hadoop環境的Windows系統的相對繁瑣步驟,Mac下顯得簡單不少。
雖然我們需要搭建的是Spark環境,但是因為Spark依賴了Hadoop的HDFS以及YARN計算框架,當然還有類似軟體包管理軟體。
安裝前必備
作業系統:Mac
OS X
JDK:1.8.0_121
命令終端:iTerm2(Mac自帶的命令終端也一樣,只是配置環境引數需要到~/.bash_profile下新增,對於iTerm2需要到~/.zshrc中新增)
軟體包管理工具:brew(能夠方便的安裝和解除安裝軟體,使用brew
cash還可以安裝圖形化的軟體,類似於Ubuntu下的apt-get
npm)
安裝Hadoop
上面步驟和條件如果都具備的話,就可以安裝Hadoop了,這也是我唯一遇到坑的地方。
1. 配置ssh
配置ssh就是為了能夠實現免密登入,這樣方便遠端管理Hadoop並無需登入密碼在Hadoop叢集上共享檔案資源。
如果你的機子沒有配置ssh的話,在命令終端輸入ssh
localhost是需要輸入你的電腦登入密碼的。配置好ssh後,就無需輸入密碼了。
第一步就是在終端執行ssh-keygen
-t rsa -P '',之後一路enter鍵,當然如果你之前已經執行過這樣的語句,那過程中會提示是否要覆蓋原有的key,輸入y即可。
第二步執行語句cat
~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
理論上這時候,你在終端輸入
ssh
lcoalhost就能夠免密登入了。
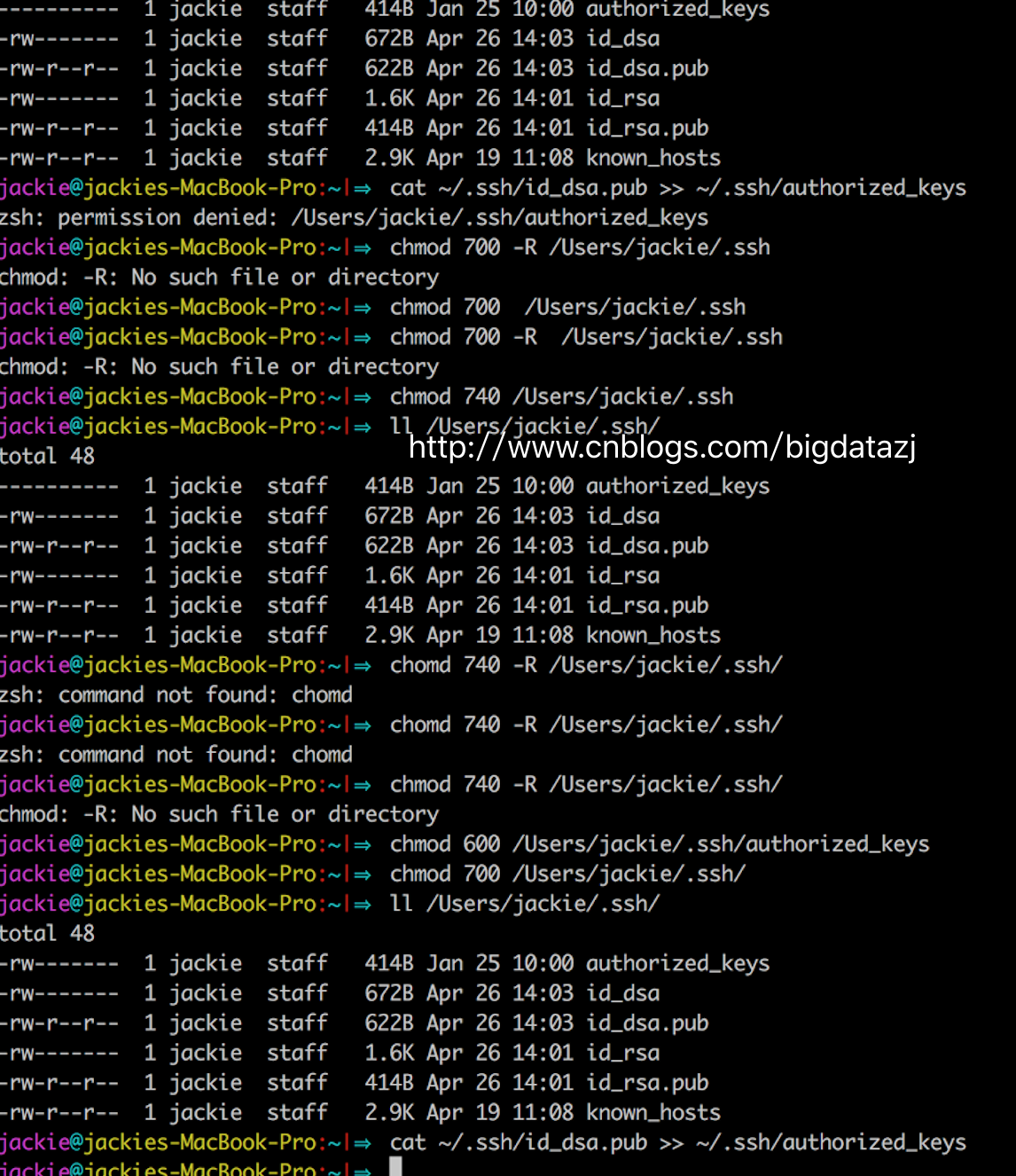
但是,我在這裡遇到了個問題,折騰了我蠻久。當我執行cat
~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys的時候,總是出現如下警告zsh:
permission denied: /Users/jackie/.ssh/authorized_keys。
顯然這是許可權問題,我直接為ssh目錄賦予777、740和700都無效,還是報同樣的錯。於是查了下資料在這裡看到了解決方案。
設定authorized_keys許可權——$
chmod 600 authorized_keys
設定
.ssh目錄許可權——$
chmod 700 -R .ssh參考資料給出的解釋是:檔案和目錄的許可權千萬別設定成chmod 777.這個許可權太大了,不安全,數字簽名也不支援--!。
如果是別人電腦ssh到我的電腦,那麼除了要把自己的私鑰複製給別人,還需要執行cat
id_rsa.pub >> authorized_keys命令才行。
生成ssh後,使用 ssh localhost 來測試 ssh 是否成功。給出提醒如下:
ssh:
connect to host localhost port 22: Connection refused
這是因為mac電腦的共享配置未開啟,在System preferences ->Sharing中開啟如下配置:
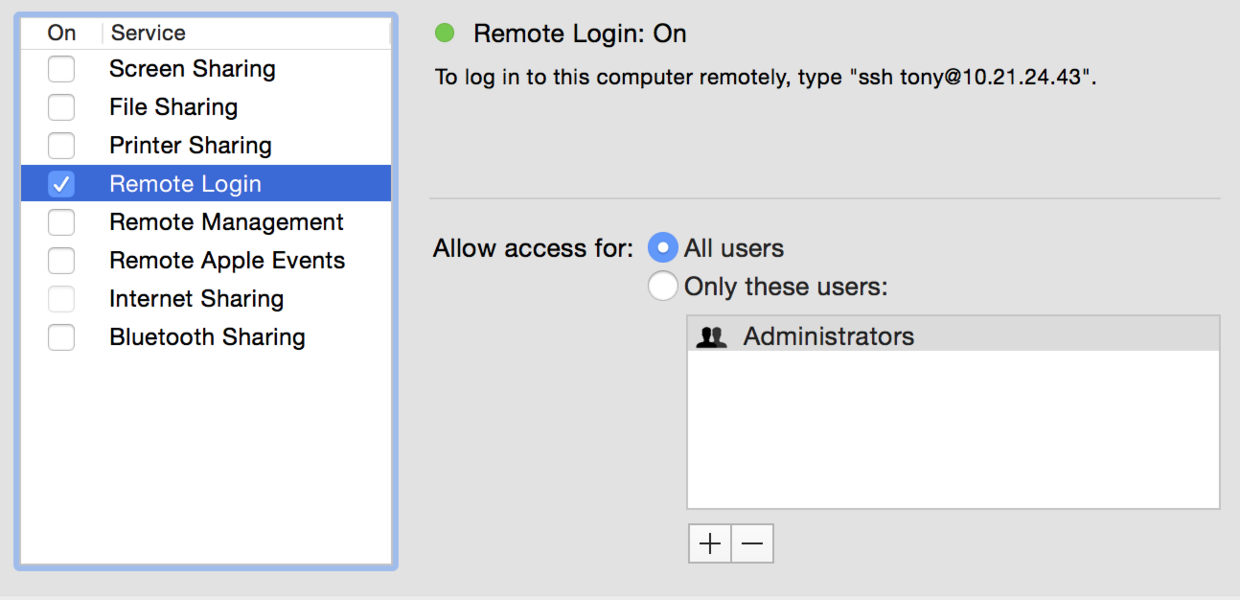
此時再次使用 ssh localhost 命令來測試返回 Last login: Mon Mar 21 09:58:12 2016,表明已經成功。
2. 下載安裝Hadoop
這時候brew的好處就體現出來了,你無需到Hadoop官網去找下載連結,只要在命令終端輸入brew
install hadoop等命令執行完,你就可以看到在/usr/lcoal/Cellar目錄下就有了hadoop目錄,表示安裝成功。(當然命令執行過程中會因為網路或其他原因中斷,這時候你只需要重新執行一次brew
install hadoop即可)
3. 配置Hadoop
3.1 進入安裝目錄/usr/local/Cellar/hadoop/2.8.0/libexec/etc/hadoop,找到並開啟hadoop-env.sh檔案,將export
HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
改為
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true -Djava.security.krb5.realm= -Djava.security.krb5.kdc="
export JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_121.jdk/Contents/Home"(java_home請寫上你本機上jdk安裝的位置)
3.2 配置hdfs地址和埠
進入目錄/usr/local/Cellar/hadoop/2.8.0/libexec/etc/hadoop,開啟core-site.xml將<configuration></configuration>替換為
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/Cellar/hadoop/hdfs/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:8020</value>
</property>
</configuration>
3.3 配置mapreduce中jobtracker的地址和埠
在相同的目錄下,你可以看到一個mapred-site.xml.template首先將檔案重新命名為mapred-site.xml,同樣將<configuration></configuration>替換為
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:8021</value>
</property>
</configuration>
3.4 修改hdfs備份數
相同目錄下,開啟hdfs-site.xml加上
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>4. 格式化HDFS
這個操作相當於一個檔案系統的初始化,執行命令hdfs
namenode -format
在終端最終會顯示成功
17/05/06 15:51:29 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/Cellar/hadoop/hdfs/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
17/05/06 15:51:29 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/Cellar/hadoop/hdfs/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 322 bytes saved in 0 seconds.
17/05/06 15:51:29 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
17/05/06 15:51:29 INFO util.ExitUtil: Exiting with status 0
17/05/06 15:51:29 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at jackies-macbook-pro.local/192.168.*.*
************************************************************/5. 配置Hadoop環境變數
因為我用的是iTerm2,所以開啟~/.zshrc新增
export HADOOP_HOME=/usr/local/Cellar/hadoop/2.8.0
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
再執行source
~/.zhsrac以確保配置生效
配置這個是方便在任意目錄下全域性開啟關閉hadoop相關服務,而不需要到/usr/local/Cellar/hadoop/2.8.0/sbin下執行。
6. 啟動關閉Hadoop服務
啟動/關閉HDSF服務
./start-dfs.sh
./stop-dfs.sh
啟動成功後,我們在瀏覽器中輸入http://localhost:50070可以看到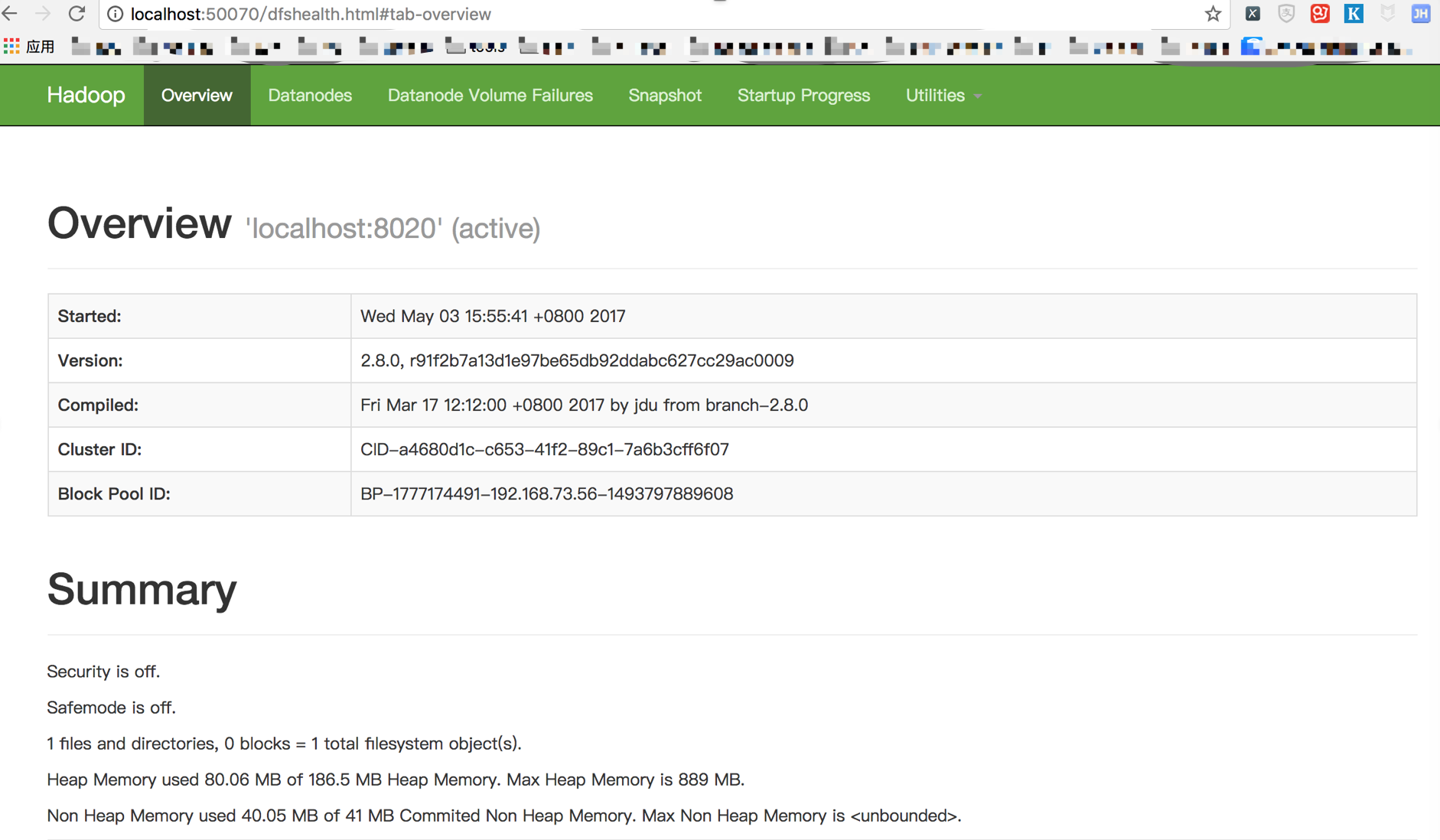
啟動/關閉YARN服務
./start-yarn.sh
./stop-yarn.sh
啟動成功後,我們在瀏覽器中輸入http://localhost:8088可以看到
啟動/關閉Hadoop服務(等效上面兩個)
./start-all.sh
./stop-all.sh另外,可以通過
jps
可以通過
hdfs dfs -mkdir -p /input
安裝Scala
同樣的配方,執行brew
install scala你就可以擁有Scala。
在終端執行scala
-version,如果出現類似Scala
code runner version 2.12.2 -- Copyright 2002-2017, LAMP/EPFL and Lightbend, Inc.說明你安裝成功了。
同樣,不要忘了配置Scala的環境變數,開啟~/.zshrc新增
export SCALA_HOME=/usr/local/Cellar/scala/2.12.2
export PATH=$PATH:$SCALA_HOME/bin安裝Spark
有了前面這麼多的準備工作,終於可以安裝Spark了。也是比較簡單,起碼我沒有遇到坑。
到Spark官網下載你需要的Spark版本,注意這裡我們看到需要有依賴的Hadoop,而且還讓你選擇Hadoop的版本。
下載完直接雙擊壓縮包就會解壓(建議安裝一個解壓軟體),將其重新命名為spark放到/usr/local下面。
毫無例外,我們還需要一個環境引數配置,開啟~/.zshrc新增
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
走到這一步,我們終於可以啟動spark了,開啟終端,輸入spark-shell,這時候會看到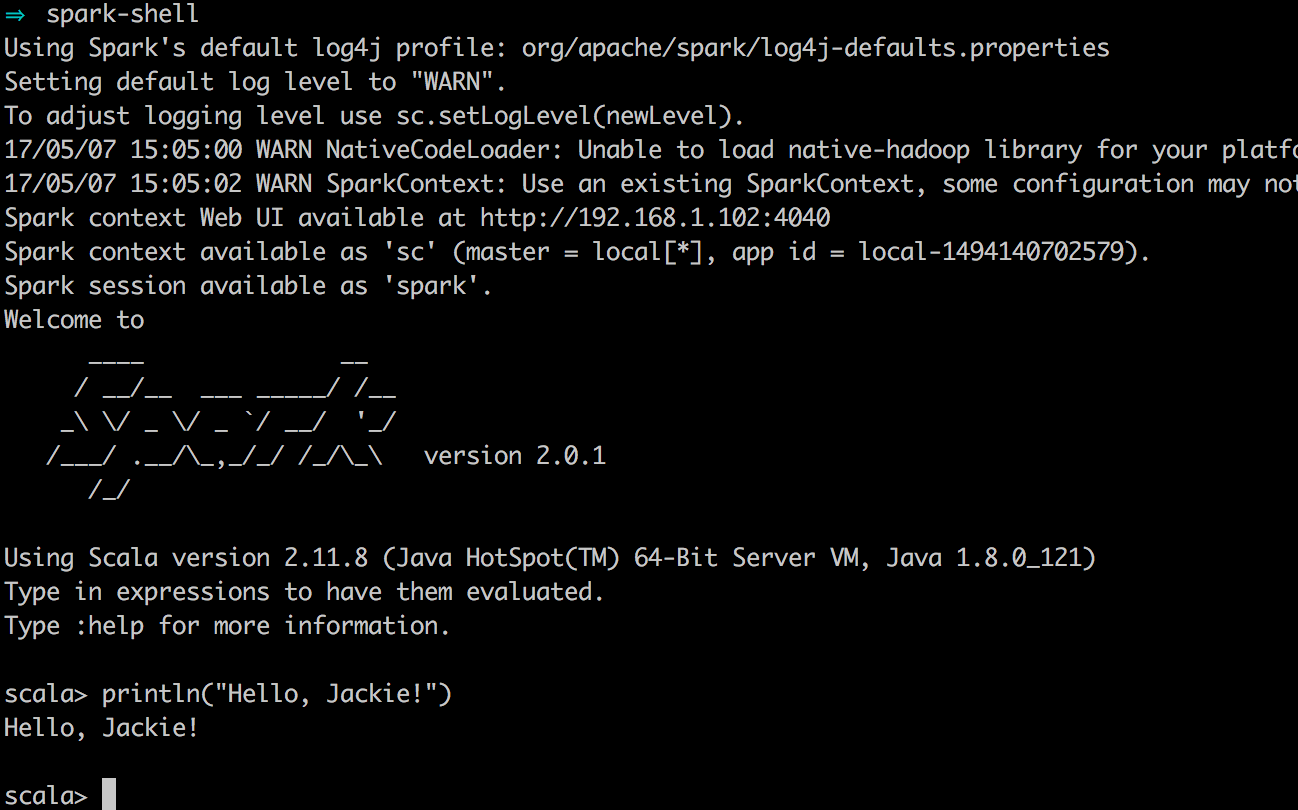
妥了!雖然整個安裝過程沒有遇到什麼大坑,但是還是比較耗時間。
這裡借鑑相關推薦
mac下Hadoop、HDFS、Spark環境的安裝和搭建
環境搭建 相比之前搭建Hadoop環境的Windows系統的相對繁瑣步驟,Mac下顯得簡單不少。 雖然我們需要搭建的是Spark環境,但是因為Spark依賴了Hadoop的HDFS以及YARN計算框架,當然還有類似軟體包管理軟體。 安裝前必備 作業系統:Mac OS
Hadoop(HDFS、YARN、HBase、Hive和Spark等)預設埠表
埠 作用 9000 fs.defaultFS,如:hdfs://172.25.40.171:9000 9001 dfs.namenode.rpc-address,DataNode會連線這個
C#、JAVA操作Hadoop(HDFS、Map/Reduce)真實過程概述。元件、原始碼下載。無法解決:Response status code does not indicate success: 500。
一、Hadoop環境配置概述 三臺虛擬機器,作業系統為:Ubuntu 16.04。 Hadoop版本:2.7.2 NameNode:192.168.72.132 DataNode:192.168.72.135,192.168.72.136
mac下webstorm2016.2啟用、部分漢化和設定風格教程
首先開啟webstorm官方http://www.jetbrains.com/webstorm/whatsnew/選擇下來dmg版本的安裝檔案 下載完成後將webstorm拖入應用程式資料夾,然後在應用程式中開啟,執行安裝步驟 1.啟用 在WebStorm License
hadoop之HDFS、yarn、MapReduce執行原理分析
1、HDFS分散式儲存 namenode:統一管理檔案的元資料資訊 fsImage:儲存了檔案的基本資訊,如檔案路徑,檔案副本集個數,檔案塊的資訊,檔案所在的主機資訊。 editslog:
hive實現txt資料匯入,理解hadoop中hdfs、mapreduce
背景:通過hive操作,瞭解hadoop的hdfs、mapreduce。 場景:hadoop雙機叢集、hive 版本:hadoop和hive的版本搭配最和諧的是什麼,目前沒有定論,每種版本的搭配都會有一些bug出現。 本例中版本:hadoop-1.0.3
Mac下hadoop運行word count的坑
ack world apache 默認 轉換成 OS 刪除 .lib logs Mac下hadoop運行word count的坑 Word count體現了Map Reduce的經典思想,是分布式計算中中的hello world。然而博主很幸運地遇到了Mac下特有的問題Mk
Mac下python+selenium【1】環境搭建
寫在最前面: 搞自動化測試呢有很大概率會用到selenium,其實用什麼語言都可以,這次先從python講起。其實在win下我已經用了很久了,今天講講Mac下的安裝。 首先是環境搭建,本文基於macOS Mojave作業系統,我用的是python3.6+pycharm,這個就不介紹了,然
1、Python簡介及環境安裝
1.Python是著名的“龜叔”Guido van Rossum在1989年聖誕節期間,為了打發無聊的聖誕節而編寫的一個程式語言。 2.程式語言排行(截止2017-04) 3。python的特點:簡單、優雅。 4。python優點:a.完善的基礎程式碼庫 b
Mac下 Hadoop部署簡介(Mac OSX 10.8.3 + Hadoop
OneCoder在自己的筆記本上部署Hadoop環境用於研究學習,記錄部署過程和遇到的問題。 1、安裝JDK。 2、下載Hadoop(1.0.4),在Hadoop中配置JAVA_HOME環境變數。修改hadoop-env.sh檔案。
Mac下Sublime Text3配置Python3開發環境
Sublime沒有幫我們配置python3,要使用Python3的話我們需要自己配置。 Tools -> Build System -> New Build System 在開啟的檔案裡面貼上以下程式碼: { "cmd": ["/opt/anac
mac下微信公眾號開發環境搭建
開發工具:idea 第一步、ngrok實現內網穿透(開發者配置中心中配置的伺服器地址必須是外網地址),操作如下 2. 解壓到指定目錄 3. 開啟“終端”,進入到解壓後的ngrok所在路徑: $ cd /ngrok所在路徑 4. 開啟服務: $ ./
zookeeper執行環境2、3:單節點安裝和偽分散式叢集安裝
轉載:http://www.aboutyun.com/thread-9097-1-1.html 問題導讀: 1.什麼是zookeeper 2.zookeeper有幾種安裝方式? 3.zookeeper偽分佈如何配置myid? 4.zookeeper包含哪些常用操作命令? 前
Mac下Sublime Text3配置Python開發環境
設定Sublime Text的語法為python View -> syntax ->python 設定編譯環境(預設python版本2.7) Tools -> Build Sys
linux、hdfs、hive、hbase常用命令
linux常用命令 pwd 檢視當前工作目錄的絕對路徑 cat input.txt 檢視input.txt檔案的內容 ls 顯示當前目錄下所有的檔案及子目錄 rm recommender-dm-1.0-SNAPSHOT-lib.jar 刪除當前目錄下recommender-dm-1.0-SNAPSHO
Mac 下配置react-native 安卓環境中遇到的坑
解決辦法:https://zhidao.baidu.com/question/1240820068009584939.html?fr=ala&word=osx%2010.11%20sudo&device=mobile&ssid=808c5269736b793333311940&
mac 下hadoop安裝並執行例子
1 安裝 #brew install hadoop 安裝的是2.6.0,目錄為/usr/local/Cellar/hadoop,如果想安裝其他版本,則下載tar包解壓即可。地址:http://mirrors.cnnic.cn/apache/hadoop
1、koala軟件的安裝和使用--less教程
技術分享 demo pan lin target body koa app 密碼 最近在學習less,感覺可以編譯的CSS真是爽,懶人必備。 1、我這裏使用到koala軟件來編譯less文件生成CSS。 附上百度網盤下載鏈接: 下載鏈接 密碼:
Spark環境安裝部署及詞頻統計例項
Spark是一個高效能的分散式計算框架,由於是在記憶體中進行操作,效能比MapReduce要高出很多. 具體的我就不介紹了,直接開始安裝部署並進行例項測試 首先在官網下載http://spark.ap
Mac下mysql 5.7.14壓縮包安裝
前言:寫個紀錄,免得倒黴又重新踩坑 MySql下載 網址: http://dev.mysql.com/downloads/mysql/,這個地址最下面選擇一個點選其右側Download按鈕即可下載這裡喔只針對tar.gz包 點