
路由器逆向分析------sasquatch和squashfs-tools工具的安裝和使用
一、sasquatch工具的安裝和使用
sasquatch工具支援對 非標準的SquashFS格式的檔案映象 進行解壓並且sasquatch工具也binwalk工具整合的一個功能元件之一。最新版的sasquatch工具是基於squashfs 4.3的原始碼修改而來的,具體修改那些檔案如下,修改的那些內容在sasquatch的GitHub的pathes目錄下有詳細說明。
The sasquatch project is a set of patches to the standard unsquashfs utility (part of squashfs-tools) that attempts to add support for as many hacked-up vendor-specific SquashFS implementations as possible.
If the vendor has done something simple like just muck a bit with the header fields, sasquatch should sort it out.
If the vendor has made changes to the underlying LZMA compression options, or to how these options are stored in the compressed data blocks, sasquatch will attempt to automatically resolve such customizations
via a brute-force method.
Additional advanced command line options have been added for testing/debugging.
原始squashfs工具的有關說明和原始碼的下載地址:https://sourceforge.net/projects/squashfs/files/squashfs/。sasquatch工具的編譯指令碼build.sh中詳細的記錄裡squashfs被path後變成sasquatch工具的過程。
sasquatch工具的github下載地址為:https://github.com/devttys0/sasquatch,sasquatch工具先安裝需要的依賴庫檔案,然後進行編譯,編譯完成以後就可以使用了。#!/bin/sh # Script to download squashfs-tools v4.3, apply the patches, perform a clean build, and install. # If not root, perform 'make install' with sudo if [ "$UID" = "0" ] then SUDO="" else SUDO="sudo" fi # Install prerequisites if hash apt-get &>/dev/null then $SUDO apt-get install build-essential liblzma-dev liblzo2-dev zlib1g-dev fi # Make sure we're working in the same directory as the build.sh script cd $(dirname `readlink -f $0`) # Download squashfs4.3.tar.gz if it does not already exist if [ ! -e squashfs4.3.tar.gz ] then wget https://downloads.sourceforge.net/project/squashfs/squashfs/squashfs4.3/squashfs4.3.tar.gz fi # Remove any previous squashfs4.3 directory to ensure a clean patch/build rm -rf squashfs4.3 # Extract squashfs4.3.tar.gz tar -zxvf squashfs4.3.tar.gz # Patch, build, and install the source cd squashfs4.3 patch -p0 < ../patches/patch0.txt cd squashfs-tools make && $SUDO make install
Prerequisites
You need a C/C++ compiler, plus the liblzma, liblzo and zlib development libraries:
$ sudo apt-get install build-essential liblzma-dev liblzo2-dev zlib1g-dev
Installation
The included build.sh script will download squashfs-tools v4.3, patch the source, then build and installsasquatch:
$ ./build.sh
sasquatch工具的下載和安裝:
# 安裝依賴庫檔案
$ sudo apt-get install build-essential liblzma-dev liblzo2-dev zlib1g-dev
# 下載原始碼
$ git clone https://github.com/devttys0/sasquatch.git
# 原始碼的編譯
$ (cd sasquatch && ./build.sh)sasquatch原始碼編譯成功後的結果,使用sasquatch工具的時候,直接命令列輸入 sasquatch加對應的引數就可以執行。
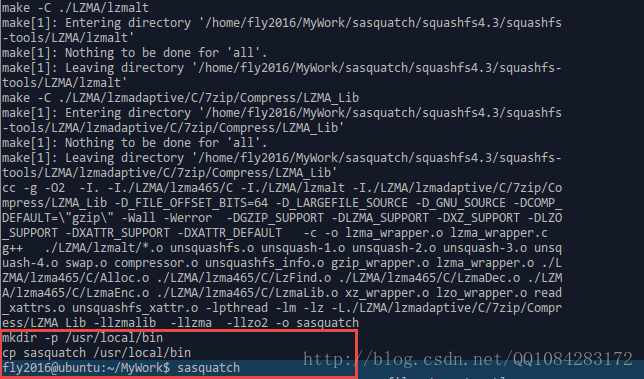
sasquatch工具的使用幫助和支援解壓的squashfs檔案的格式:
[email protected]:~$ sasquatch
SYNTAX: sasquatch [options] filesystem [directories or files to extract]
-v[ersion] print version, licence and copyright information
-d[est] <pathname> unsquash to <pathname>, default "squashfs-root"
-n[o-progress] don't display the progress bar
-no[-xattrs] don't extract xattrs in file system
-x[attrs] extract xattrs in file system (default)
-u[ser-xattrs] only extract user xattrs in file system.
Enables extracting xattrs
-p[rocessors] <number> use <number> processors. By default will use
number of processors available
-i[nfo] print files as they are unsquashed
-li[nfo] print files as they are unsquashed with file
attributes (like ls -l output)
-l[s] list filesystem, but don't unsquash
-ll[s] list filesystem with file attributes (like
ls -l output), but don't unsquash
-f[orce] if file already exists then overwrite
-s[tat] display filesystem superblock information
-e[f] <extract file> list of directories or files to extract.
One per line
-da[ta-queue] <size> Set data queue to <size> Mbytes. Default 256
Mbytes
-fr[ag-queue] <size> Set fragment queue to <size> Mbytes. Default
256 Mbytes
-r[egex] treat extract names as POSIX regular expressions
rather than use the default shell wildcard
expansion (globbing)
-trace Enable verbose trace output
-lc <value> Set the lzma-adaptive lc parameter [0-4]
-lp <value> Set the lzma-adaptive lp parameter [0-4]
-pb <value> Set the lzma-adaptive pb parameter [0-8]
-dict <value> Set the lzma-adaptive dictionary size
-lzma-offset <value> Set the lzma-adaptive LZMA data offset
-major <version> Manually set the SquashFS major version number
-minor <version> Manually set the SquashFS minor version number
-be Treat the filesystem as big endian
-le Treat the filesystem as little endian
-c[omp] <decompressor> Specify the decompressor to use
Decompressors available:
gzip
lzma
lzma-adaptive
lzma-alt
lzma-ddwrt
lzo
xz二、squashfs-tools工具的安裝和使用
squashfs-tools工具既可以對squashfs格式的檔案進行解壓也可以對
INSTALLING SQUASHFS
The squashfs4.3.tar.gz file contains the squashfs-tools directory containing
mksquashfs and unsquashfs.
1. Kernel support
-----------------
This release is for 2.6.29 and newer kernels. Kernel patching is not necessary.
Extended attribute support requires 2.6.35 or newer. File systems with
extended attributes can be mounted on 2.6.29 and newer kernels (the
extended attributes will be ignored with a warning).
LZO compression support requires 2.6.36 or newer kernels.
XZ compression support requires 2.6.38 or newer kernels.
LZ4 support is not yet in any mainline kernel.
2. Building squashfs tools
--------------------------
The squashfs-tools directory contains the mksquashfs and unsquashfs programs.
These can be made by typing make (or make install to install in /usr/local/bin).
By default the tools are built with GZIP compression and extended attribute
support. Read the Makefile in squashfs-tools/ for instructions on building
LZO, LZ4 and XZ compression support, and for instructions on disabling GZIP
and extended attribute support if desired.1.通過github的方式安裝squashfs-tools工具。
$ git clone https://github.com/plougher/squashfs-tools.git
$ cd ./squashfs-tools/squashfs-tools
$ sudo make && sudo make install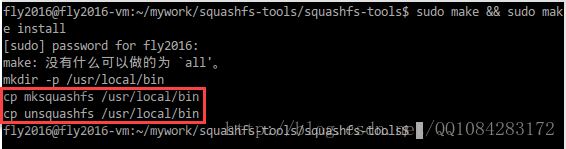
2.通過sourceforge.net網站下載的方式安裝squashfs-tools工具。
$ wget https://nchc.dl.sourceforge.net/project/squashfs/squashfs/squashfs4.3/squashfs4.3.tar.gz
$ tar -zxvf squashfs4.3.tar.gz
$ cd squashfs4.3/squashfs-tools
$ sudo make && sudo make install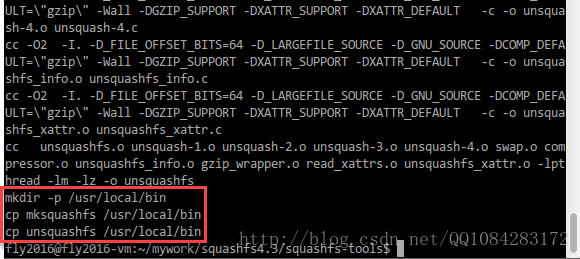
3.通過apt-get的方式進行直接安裝.
$ sudo apt-get install squashfs-tools SQUASHFS 4.3 - A squashed read-only filesystem for Linux
Copyright 2002-2014 Phillip Lougher <[email protected]>
Released under the GPL licence (version 2 or later).
Welcome to Squashfs version 4.3. Please read the README-4.3 and CHANGES files
for details of changes.
Squashfs is a highly compressed read-only filesystem for Linux.
It uses either gzip/xz/lzo/lz4 compression to compress both files, inodes
and directories. Inodes in the system are very small and all blocks are
packed to minimise data overhead. Block sizes greater than 4K are supported
up to a maximum of 1Mbytes (default block size 128K).
Squashfs is intended for general read-only filesystem use, for archival
use (i.e. in cases where a .tar.gz file may be used), and in constrained
block device/memory systems (e.g. embedded systems) where low overhead is
needed.
1. SQUASHFS OVERVIEW
--------------------
1. Data, inodes and directories are compressed.
2. Squashfs stores full uid/gids (32 bits), and file creation time.
3. In theory files up to 2^64 bytes are supported. In theory filesystems can
be up to 2^64 bytes.
4. Inode and directory data are highly compacted, and packed on byte
boundaries. Each compressed inode is on average 8 bytes in length
(the exact length varies on file type, i.e. regular file, directory,
symbolic link, and block/char device inodes have different sizes).
5. Squashfs can use block sizes up to 1Mbyte (the default size is 128K).
Using 128K blocks achieves greater compression ratios than the normal
4K block size.
6. File duplicates are detected and removed.
7. Filesystems can be compressed with gzip, xz (lzma2), lzo or lz4
compression algorithms.
1.1 Extended attributes (xattrs)
--------------------------------
Squashfs filesystems now have extended attribute support. The
extended attribute implementation has the following features:
1. Layout can store up to 2^48 bytes of compressed xattr data.
2. Number of xattrs per inode unlimited.
3. Total size of xattr data per inode 2^48 bytes of compressed data.
4. Up to 4 Gbytes of data per xattr value.
5. Inline and out-of-line xattr values supported for higher performance
in xattr scanning (listxattr & getxattr), and to allow xattr value
de-duplication.
6. Both whole inode xattr duplicate detection and individual xattr value
duplicate detection supported. These can obviously nest, file C's
xattrs can be a complete duplicate of file B, and file B's xattrs
can be a partial duplicate of file A.
7. Xattr name prefix types stored, allowing the redundant "user.", "trusted."
etc. characters to be eliminated and more concisely stored.
8. Support for files, directories, symbolic links, device nodes, fifos
and sockets.
Extended attribute support is in 2.6.35 and later kernels. Filesystems
with extended attributes can be mounted on 2.6.29 and later kernels, the
extended attributes will be ignored with a warning.
2. USING SQUASHFS
-----------------
Squashfs filesystems should be mounted with 'mount' with the filesystem type
'squashfs'. If the filesystem is on a block device, the filesystem can be
mounted directly, e.g.
%mount -t squashfs /dev/sda1 /mnt
Will mount the squashfs filesystem on "/dev/sda1" under the directory "/mnt".
If the squashfs filesystem has been written to a file, the loopback device
can be used to mount it (loopback support must be in the kernel), e.g.
%mount -t squashfs image /mnt -o loop
Will mount the squashfs filesystem in the file "image" under
the directory "/mnt".
3. MKSQUASHFS
-------------
3.1 Mksquashfs options and overview
-----------------------------------
As squashfs is a read-only filesystem, the mksquashfs program must be used to
create populated squashfs filesystems.
SYNTAX:./mksquashfs source1 source2 ... dest [options] [-e list of exclude
dirs/files]
Filesystem build options:
-comp <comp> select <comp> compression
Compressors available:
gzip (default)
lzo
lz4
xz
-b <block_size> set data block to <block_size>. Default 128 Kbytes
Optionally a suffix of K or M can be given to specify
Kbytes or Mbytes respectively
-no-exports don't make the filesystem exportable via NFS
-no-sparse don't detect sparse files
-no-xattrs don't store extended attributes
-xattrs store extended attributes (default)
-noI do not compress inode table
-noD do not compress data blocks
-noF do not compress fragment blocks
-noX do not compress extended attributes
-no-fragments do not use fragments
-always-use-fragments use fragment blocks for files larger than block size
-no-duplicates do not perform duplicate checking
-all-root make all files owned by root
-force-uid uid set all file uids to uid
-force-gid gid set all file gids to gid
-nopad do not pad filesystem to a multiple of 4K
-keep-as-directory if one source directory is specified, create a root
directory containing that directory, rather than the
contents of the directory
Filesystem filter options:
-p <pseudo-definition> Add pseudo file definition
-pf <pseudo-file> Add list of pseudo file definitions
-sort <sort_file> sort files according to priorities in <sort_file>. One
file or dir with priority per line. Priority -32768 to
32767, default priority 0
-ef <exclude_file> list of exclude dirs/files. One per line
-wildcards Allow extended shell wildcards (globbing) to be used in
exclude dirs/files
-regex Allow POSIX regular expressions to be used in exclude
dirs/files
Filesystem append options:
-noappend do not append to existing filesystem
-root-becomes <name> when appending source files/directories, make the
original root become a subdirectory in the new root
called <name>, rather than adding the new source items
to the original root
Mksquashfs runtime options:
-version print version, licence and copyright message
-exit-on-error treat normally ignored errors as fatal
-recover <name> recover filesystem data using recovery file <name>
-no-recovery don't generate a recovery file
-info print files written to filesystem
-no-progress don't display the progress bar
-progress display progress bar when using the -info option
-processors <number> Use <number> processors. By default will use number of
processors available
-mem <size> Use <size> physical memory. Currently set to 1922M
Optionally a suffix of K, M or G can be given to specify
Kbytes, Mbytes or Gbytes respectively
Miscellaneous options:
-root-owned alternative name for -all-root
-noInodeCompression alternative name for -noI
-noDataCompression alternative name for -noD
-noFragmentCompression alternative name for -noF
-noXattrCompression alternative name for -noX
-Xhelp print compressor options for selected compressor
Compressors available and compressor specific options:
gzip (default)
-Xcompression-level <compression-level>
<compression-level> should be 1 .. 9 (default 9)
-Xwindow-size <window-size>
<window-size> should be 8 .. 15 (default 15)
-Xstrategy strategy1,strategy2,...,strategyN
Compress using strategy1,strategy2,...,strategyN in turn
and choose the best compression.
Available strategies: default, filtered, huffman_only,
run_length_encoded and fixed
lzo
-Xalgorithm <algorithm>
Where <algorithm> is one of:
lzo1x_1
lzo1x_1_11
lzo1x_1_12
lzo1x_1_15
lzo1x_999 (default)
-Xcompression-level <compression-level>
<compression-level> should be 1 .. 9 (default 8)
Only applies to lzo1x_999 algorithm
lz4
-Xhc
Compress using LZ4 High Compression
xz
-Xbcj filter1,filter2,...,filterN
Compress using filter1,filter2,...,filterN in turn
(in addition to no filter), and choose the best compression.
Available filters: x86, arm, armthumb, powerpc, sparc, ia64
-Xdict-size <dict-size>
Use <dict-size> as the XZ dictionary size. The dictionary size
can be specified as a percentage of the block size, or as an
absolute value. The dictionary size must be less than or equal
to the block size and 8192 bytes or larger. It must also be
storable in the xz header as either 2^n or as 2^n+2^(n+1).
Example dict-sizes are 75%, 50%, 37.5%, 25%, or 32K, 16K, 8K
etc.
Source1 source2 ... are the source directories/files containing the
files/directories that will form the squashfs filesystem. If a single
directory is specified (i.e. mksquashfs source output_fs) the squashfs
filesystem will consist of that directory, with the top-level root
directory corresponding to the source directory.
If multiple source directories or files are specified, mksquashfs will merge
the specified sources into a single filesystem, with the root directory
containing each of the source files/directories. The name of each directory
entry will be the basename of the source path. If more than one source
entry maps to the same name, the conflicts are named xxx_1, xxx_2, etc. where
xxx is the original name.
To make this clear, take two example directories. Source directory
"/home/phillip/test" contains "file1", "file2" and "dir1".
Source directory "goodies" contains "goodies1", "goodies2" and "goodies3".
usage example 1:
%mksquashfs /home/phillip/test output_fs
This will generate a squashfs filesystem with root entries
"file1", "file2" and "dir1".
example 2:
%mksquashfs /home/phillip/test goodies output_fs
This will create a squashfs filesystem with the root containing
entries "test" and "goodies" corresponding to the source
directories "/home/phillip/test" and "goodies".
example 3:
%mksquashfs /home/phillip/test goodies test output_fs
This is the same as the previous example, except a third
source directory "test" has been specified. This conflicts
with the first directory named "test" and will be renamed "test_1".
Multiple sources allow filesystems to be generated without needing to
copy all source files into a common directory. This simplifies creating
filesystems.
The -keep-as-directory option can be used when only one source directory
is specified, and you wish the root to contain that directory, rather than
the contents of the directory. For example:
example 4:
%mksquashfs /home/phillip/test output_fs -keep-as-directory
This is the same as example 1, except for -keep-as-directory.
This will generate a root directory containing directory "test",
rather than the "test" directory contents "file1", "file2" and "dir1".
The Dest argument is the destination where the squashfs filesystem will be
written. This can either be a conventional file or a block device. If the file
doesn't exist it will be created, if it does exist and a squashfs
filesystem exists on it, mksquashfs will append. The -noappend option will
write a new filesystem irrespective of whether an existing filesystem is
present.
3.2 Changing compression algorithm and compression specific options
-------------------------------------------------------------------
By default Mksquashfs will compress using the gzip compression
algorithm. This algorithm offers a good trade-off between compression
ratio, and memory and time taken to decompress.
Squashfs also supports LZ4, LZO and XZ (LZMA2) compression. LZO offers worse
compression ratio than gzip, but is faster to decompress. XZ offers better
compression ratio than gzip, but at the expense of greater memory and time
to decompress (and significantly more time to compress). LZ4 is similar
to LZO, but, support for it is not yet in the mainline kernel, and so
its usefulness is currently limited to using Squashfs with Mksquashfs/Unsquashfs
as an archival system like tar.
If you're not building the squashfs-tools and kernel from source, then
the tools and kernel may or may not have been built with support for LZ4, LZO or
XZ compression. The compression algorithms supported by the build of
Mksquashfs can be found by typing mksquashfs without any arguments. The
compressors available are displayed at the end of the help message, e.g.
Compressors available and compressor specific options:
gzip (default)
-Xcompression-level <compression-level>
<compression-level> should be 1 .. 9 (default 9)
-Xwindow-size <window-size>
<window-size> should be 8 .. 15 (default 15)
-Xstrategy strategy1,strategy2,...,strategyN
Compress using strategy1,strategy2,...,strategyN in turn
and choose the best compression.
Available strategies: default, filtered, huffman_only,
run_length_encoded and fixed
lzo
-Xalgorithm <algorithm>
Where <algorithm> is one of:
lzo1x_1
lzo1x_1_11
lzo1x_1_12
lzo1x_1_15
lzo1x_999 (default)
-Xcompression-level <compression-level>
<compression-level> should be 1 .. 9 (default 8)
Only applies to lzo1x_999 algorithm
lz4
-Xhc
Compress using LZ4 High Compression
xz
-Xbcj filter1,filter2,...,filterN
Compress using filter1,filter2,...,filterN in turn
(in addition to no filter), and choose the best compression.
Available filters: x86, arm, armthumb, powerpc, sparc, ia64
-Xdict-size <dict-size>
Use <dict-size> as the XZ dictionary size. The dictionary size
can be specified as a percentage of the block size, or as an
absolute value. The dictionary size must be less than or equal
to the block size and 8192 bytes or larger. It must also be
storable in the xz header as either 2^n or as 2^n+2^(n+1).
Example dict-sizes are 75%, 50%, 37.5%, 25%, or 32K, 16K, 8K
etc.
If the compressor offers compression specific options (all the compressors now
have compression specific options except the deprecated lzma1 compressor)
then these options are also displayed (.i.e. in the above XZ is shown with two
compression specific options). The compression specific options are, obviously,
specific to the compressor in question, and the compressor documentation and
web sites should be consulted to understand their behaviour. In general
the Mksquashfs compression defaults for each compressor are optimised to
give the best performance for each compressor, where what constitutes
best depends on the compressor. For gzip/xz best means highest compression,
for LZO/LZ4 best means a tradeoff between compression and (de)-compression
overhead (LZO/LZ4 by definition are intended for weaker processors).
3.3 Changing global compression defaults used in mksquashfs
-----------------------------------------------------------
There are a large number of options that can be used to control the
compression in mksquashfs. By and large the defaults are the most
optimum settings and should only be changed in exceptional circumstances!
Note, this does not apply to the block size, increasing the block size
from the default of 128Kbytes will increase compression (especially
for the xz compressor) and should increase I/O performance too. However,
a block size of greater than 128Kbytes may increase latency in certain
cases (where the filesystem contains lots of fragments, and no locality
of reference is observed). For this reason the block size default is
configured to the less optimal 128Kbytes. Users should experiment
with 256Kbyte sizes or above.
The -noI, -noD and -noF options (also -noInodeCompression, -noDataCompression
and -noFragmentCompression) can be used to force mksquashfs to not compress
inodes/directories, data and fragments respectively. Giving all options
generates an uncompressed filesystem.
The -no-fragments tells mksquashfs to not generate fragment blocks, and rather
generate a filesystem similar to a Squashfs 1.x filesystem. It will of course
still be a Squashfs 4.0 filesystem but without fragments, and so it won't be
mountable on a Squashfs 1.x system.
The -always-use-fragments option tells mksquashfs to always generate
fragments for files irrespective of the file length. By default only small
files less than the block size are packed into fragment blocks. The ends of
files which do not fit fully into a block, are NOT by default packed into
fragments. To illustrate this, a 100K file has an initial 64K block and a 36K
remainder. This 36K remainder is not packed into a fragment by default. This
is because to do so leads to a 10 - 20% drop in sequential I/O performance, as a
disk head seek is needed to seek to the initial file data and another disk seek
is need to seek to the fragment block. Specify this option if you want file
remainders to be packed into fragment blocks. Doing so may increase the
compression obtained BUT at the expense of I/O speed.
The -no-duplicates option tells mksquashfs to not check the files being
added to the filesystem for duplicates. This can result in quicker filesystem
generation and appending although obviously compression will suffer badly if
there is a lot of duplicate files.
The -b option allows the block size to be selected, both "K" and "M" postfixes
are supported, this can be either 4K, 8K, 16K, 32K, 64K, 128K, 256K, 512K or
1M bytes.
3.4 Specifying the UIDs/GIDs used in the filesystem
---------------------------------------------------
By default files in the generated filesystem inherit the UID and GID ownership
of the original file. However, mksquashfs provides a number of options which
can be used to override the ownership.
The options -all-root and -root-owned (both do exactly the same thing) force all
file uids/gids in the generated Squashfs filesystem to be root. This allows
root owned filesystems to be built without root access on the host machine.
The "-force-uid uid" option forces all files in the generated Squashfs
filesystem to be owned by the specified uid. The uid can be specified either by
name (i.e. "root") or by number.
The "-force-gid gid" option forces all files in the generated Squashfs
filesystem to be group owned by the specified gid. The gid can be specified
either by name (i.e. "root") or by number.
3.5 Excluding files from the filesystem
---------------------------------------
The -e and -ef options allow files/directories to be specified which are
excluded from the output filesystem. The -e option takes the exclude
files/directories from the command line, the -ef option takes the
exlude files/directories from the specified exclude file, one file/directory
per line.
Two styles of exclude file matching are supported: basic exclude matching, and
extended wildcard matching. Basic exclude matching is a legacy feature
retained for backwards compatibility with earlier versions of Mksquashfs.
Extended wildcard matching should be used in preference.
3.5.1 Basic exclude matching
----------------------------
Each exclude file is treated as an exact match of a file/directory in
the source directories. If an exclude file/directory is absolute (i.e.
prefixed with /, ../, or ./) the entry is treated as absolute, however, if an
exclude file/directory is relative, it is treated as being relative to each of
the sources in turn, i.e.
%mksquashfs /tmp/source1 source2 output_fs -e ex1 /tmp/source1/ex2 out/ex3
Will generate exclude files /tmp/source1/ex2, /tmp/source1/ex1, source2/ex1,
/tmp/source1/out/ex3 and source2/out/ex3.
3.5.2 Extended exclude file handling
------------------------------------
Extended exclude file matching treats each exclude file as a wildcard or
regex expression. To enable wildcard matching specify the -wildcards
option, and to enable regex matching specify the -regex option. In most
cases the -wildcards option should be used rather than -regex because wildcard
matching behaviour is significantly easier to understand!
In addition to wildcards/regex expressions, exclude files can be "anchored" or
"non-anchored". An anchored exclude is one which matches from the root of the
directory and nowhere else, a non-anchored exclude matches anywhere. For
example given the directory hierarchy "a/b/c/a/b", the anchored exclude
"a/b" will match "a/b" at the root of the directory hierarchy, but
it will not match the "/a/b" sub-directory within directory "c", whereas a
non-anchored exclude would.
A couple of examples should make this clearer.
Anchored excludes
1. mksquashfs example image.sqsh -wildcards -e 'test/*.gz'
Exclude all files matching "*.gz" in the top level directory "test".
2. mksquashfs example image.sqsh -wildcards -e '*/[Tt]est/example*'
Exclude all files beginning with "example" inside directories called
"Test" or "test", that occur inside any top level directory.
Using extended wildcards, negative matching is also possible.
3. mksquashfs example image.sqsh -wildcards -e 'test/!(*data*).gz'
Exclude all files matching "*.gz" in top level directory "test",
except those with "data" in the name.
Non-anchored excludes
By default excludes match from the top level directory, but it is
often useful to exclude a file matching anywhere in the source directories.
For this non-anchored excludes can be used, specified by pre-fixing the
exclude with "...".
Examples:
1. mksquashfs example image.sqsh -wildcards -e '... *.gz'
Exclude files matching "*.gz" anywhere in the source directories.
For example this will match "example.gz", "test/example.gz", and
"test/test/example.gz".
2. mksquashfs example image.sqsh -wildcards -e '... [Tt]est/*.gz'
Exclude files matching "*.gz" inside directories called "Test" or
"test" that occur anywhere in the source directories.
Again, using extended wildcards, negative matching is also possible.
3. mksquashfs example image.sqsh -wildcards -e '... !(*data*).gz'
Exclude all files matching "*.gz" anywhere in the source directories,
except those with "data" in the name.
3.5.3 Exclude files summary
---------------------------
The -e and -ef exclude options are usefully used in archiving the entire
filesystem, where it is wished to avoid archiving /proc, and the filesystem
being generated, i.e.
%mksquashfs / /tmp/root.sqsh -e proc /tmp/root.sqsh
Multiple -ef options can be specified on the command line, and the -ef
option can be used in conjuction with the -e option.
3.6 Appending to squashfs filesystems
-------------------------------------
Running squashfs with the destination directory containing an existing
filesystem will add the source items to the existing filesystem. By default,
the source items are added to the existing root directory.
To make this clear... An existing filesystem "image" contains root entries
"old1", and "old2". Source directory "/home/phillip/test" contains "file1",
"file2" and "dir1".
example 1:
%mksquashfs /home/phillip/test image
Will create a new "image" with root entries "old1", "old2", "file1", "file2" and
"dir1"
example 2:
%mksquashfs /home/phillip/test image -keep-as-directory
Will create a new "image" with root entries "old1", "old2", and "test".
As shown in the previous section, for single source directories
'-keep-as-directory' adds the source directory rather than the
contents of the directory.
example 3:
%mksquashfs /home/phillip/test image -keep-as-directory -root-becomes
original-root
Will create a new "image" with root entries "original-root", and "test". The
'-root-becomes' option specifies that the original root becomes a subdirectory
in the new root, with the specified name.
The append option with file duplicate detection, means squashfs can be
used as a simple versioning archiving filesystem. A squashfs filesystem can
be created with for example the linux-2.4.19 source. Appending the linux-2.4.20
source will create a filesystem with the two source trees, but only the
changed files will take extra room, the unchanged files will be detected as
duplicates.
3.7 Appending recovery file feature
-----------------------------------
Recovery files are created when appending to existing Squashfs
filesystems. This allows the original filesystem to be recovered
if Mksquashfs aborts unexpectedly (i.e. power failure).
The recovery files are called squashfs_recovery_xxx_yyy, where
"xxx" is the name of the filesystem being appended to, and "yyy" is a
number to guarantee filename uniqueness (the PID of the parent Mksquashfs
process).
Normally if Mksquashfs exits correctly the recovery file is deleted to
avoid cluttering the filesystem. If Mksquashfs aborts, the "-recover"
option can be used to recover the filesystem, giving the previously
created recovery file as a parameter, i.e.
mksquashfs dummy image.sqsh -recover squashfs_recovery_image.sqsh_1234
The writing of the recovery file can be disabled by specifying the
"-no-recovery" option.
3.8 Pseudo file support
-----------------------
Mksquashfs supports pseudo files, these allow fake files, directories, character
and block devices to be specified and added to the Squashfs filesystem being
built, rather than requiring them to be present in the source directories.
This, for example, allows device nodes to be added to the filesystem without
requiring root access.
Mksquashfs 4.1 added support for "dynamic pseudo files" and a modify operation.
Dynamic pseudo files allow files to be dynamically created when Mksquashfs
is run, their contents being the result of running a command or piece of
shell script. The modifiy operation allows the mode/uid/gid of an existing
file in the source filesystem to be modified.
Two Mksquashfs options are supported, -p allows one pseudo file to be specified
on the command line, and -pf allows a pseudo file to be specified containing a
list of pseduo definitions, one per line.
3.8.1. Creating a dynamic file
------------------------------
Pseudo definition
Filename f mode uid gid command
mode is the octal mode specifier, similar to that expected by chmod.
uid and gid can be either specified as a decimal number, or by name.
command can be an executable or a piece of shell script, and it is executed
by running "/bin/sh -c command". The stdout becomes the contents of
"Filename".
Examples:
Running a basic command
-----------------------
/somedir/dmesg f 444 root root dmesg
creates a file "/somedir/dmesg" containing the output from dmesg.
Executing shell script
----------------------
RELEASE f 444 root root \
if [ ! -e /tmp/ver ]; then \
echo 0 > /tmp/ver; \
fi; \
ver=`cat /tmp/ver`; \
ver=$((ver +1)); \
echo $ver > /tmp/ver; \
echo -n `cat /tmp/release`; \
echo "-dev #"$ver `date` "Build host" `hostname`
Creates a file RELEASE containing the release name, date, build host, and
an incrementing version number. The incrementing version is a side-effect
of executing the shell script, and ensures every time Mksquashfs is run a
new version number is used without requiring any other shell scripting.
The above example also shows that commands can be split across multiple lines
using "\". Obviously as the script will be presented to the shell as a single
line, a semicolon is need to separate individual shell commands within the
shell script.
Reading from a device (or fifo/named socket)
--------------------------------------------
input f 444 root root dd if=/dev/sda1 bs=1024 count=10
Copies 10K from the device /dev/sda1 into the file input. Ordinarily Mksquashfs
given a device, fifo, or named socket will place that special file within the
Squashfs filesystem, the above allows input from these special files to be
captured and placed in the Squashfs filesystem.
3.8.2. Creating a block or character device
-------------------------------------------
Pseudo definition
Filename type mode uid gid major minor
Where type is either
b - for block devices, and
c - for character devices
mode is the octal mode specifier, similar to that expected by chmod.
uid and gid can be either specified as a decimal number, or by name.
For example:
/dev/chr_dev c 666 root root 100 1
/dev/blk_dev b 666 0 0 200 200
creates a character device "/dev/chr_dev" with major:minor 100:1 and
a block device "/dev/blk_dev" with major:minor 200:200, both with root
uid/gid and a mode of rw-rw-rw.
3.8.3. Creating a directory
---------------------------
Pseudo definition
Filename d mode uid gid
mode is the octal mode specifier, similar to that expected by chmod.
uid and gid can be either specified as a decimal number, or by name.
For example:
/pseudo_dir d 666 root root
creates a directory "/pseudo_dir" with root uid/gid and mode of rw-rw-rw.
3.8.4. Modifying attributes of an existing file
-----------------------------------------------
Pseudo definition
Filename m mode uid gid
mode is the octal mode specifier, similar to that expected by chmod.
uid and gid can be either specified as a decimal number, or by name.
For example:
dmesg m 666 root root
Changes the attributes of the file "dmesg" in the filesystem to have
root uid/gid and a mode of rw-rw-rw, overriding the attributes obtained
from the source filesystem.
3.9 Miscellaneous options
-------------------------
The -info option displays the files/directories as they are compressed and
added to the filesystem. The original uncompressed size of each file
is printed, along with DUPLICATE if the file is a duplicate of a
file in the filesystem.
The -nopad option informs mksquashfs to not pad the filesystem to a 4K multiple.
This is performed by default to enable the output filesystem file to be mounted
by loopback, which requires files to be a 4K multiple. If the filesystem is
being written to a block device, or is to be stored in a bootimage, the extra
pad bytes are not needed.
4. UNSQUASHFS
-------------
Unsquashfs allows you to decompress and extract a Squashfs filesystem without
mounting it. It can extract the entire filesystem, or a specific
file or directory.
The Unsquashfs usage info is:
SYNTAX: ./unsquashfs [options] filesystem [directories or files to extract]
-v[ersion] print version, licence and copyright information
-d[est] <pathname> unsquash to <pathname>, default "squashfs-root"
-n[o-progress] don't display the progress bar
-no[-xattrs] don't extract xattrs in file system
-x[attrs] extract xattrs in file system (default)
-u[ser-xattrs] only extract user xattrs in file system.
Enables extracting xattrs
-p[rocessors] <number> use <number> processors. By default will use
number of processors available
-i[nfo] print files as they are unsquashed
-li[nfo] print files as they are unsquashed with file
attributes (like ls -l output)
-l[s] list filesystem, but don't unsquash
-ll[s] list filesystem with file attributes (like
ls -l output), but don't unsquash
-f[orce] if file already exists then overwrite
-s[tat] display filesystem superblock information
-e[f] <extract file> list of directories or files to extract.
One per line
-da[ta-queue] <size> Set data queue to <size> Mbytes. Default 256
Mbytes
-fr[ag-queue] <size> Set fragment queue to <size> Mbytes. Default
256 Mbytes
-r[egex] treat extract names as POSIX regular expressions
rather than use the default shell wildcard
expansion (globbing)
Decompressors available:
gzip
lzo
lz4
xz
To extract a subset of the filesystem, the filenames or directory
trees that are to be extracted can be specified on the command line. The
files/directories should be specified using the full path to the
files/directories as they appear within the Squashfs filesystem. The
files/directories will also be extracted to those positions within the specified
destination directory.
The extract files can also be given in a file using the "-e[f]" option.
Similarly to Mksquashfs, wildcard matching is performed on the extract
files. Wildcard matching is enabled by default.
Examples:
1. unsquashfs image.sqsh 'test/*.gz'
Extract all files matching "*.gz" in the top level directory "test".
2. unsquashfs image.sqsh '[Tt]est/example*'
Extract all files beginning with "example" inside top level directories
called "Test" or "test".
Using extended wildcards, negative matching is also possible.
3. unsquashfs image.sqsh 'test/!(*data*).gz'
Extract all files matching "*.gz" in top level directory "test",
except those with "data" in the name.
4.1 Unsquashfs options
----------------------
The "-ls" option can be used to list the contents of a filesystem without
decompressing the filesystem data itself. The "-lls" option is similar
but it also displays file attributes (ls -l style output).
The "-info" option forces Unsquashfs to print each file as it is decompressed.
The -"linfo" is similar but it also displays file attributes.
The "-dest" option specifies the directory that is used to decompress
the filesystem data. If this option is not given then the filesystem is
decompressed to the directory "squashfs-root" in the current working directory.
The "-force" option forces Unsquashfs to output to the destination
directory even if files or directories already exist. This allows you
to update an existing directory tree, or to Unsquashfs to a partially
filled directory. Without the "-force" option, Unsquashfs will
refuse to overwrite any existing files, or to create any directories if they
already exist. This is done to protect data in case of mistakes, and
so the "-force" option should be used with caution.
The "-stat" option displays filesystem superblock information. This is
useful to discover the filesystem version, byte ordering, whether it has a NFS
export table, and what options were used to compress the filesystem, etc.
Unsquashfs can decompress all Squashfs filesystem versions, 1.x, 2.x, 3.x and
4.0 filesystems.
5. FILESYSTEM LAYOUT
--------------------
A squashfs filesystem consists of a maximum of nine parts, packed together on a
byte alignment:
---------------
| superblock |
|---------------|
| compression |
| options |
|---------------|
| datablocks |
| & fragments |
|---------------|
| inode table |
|---------------|
| directory |
| table |
|---------------|
| fragment |
| table |
|---------------|
| export |
| table |
|---------------|
| uid/gid |
| lookup table |
|---------------|
| xattr |
| table |
---------------
Compressed data blocks are written to the filesystem as files are read from
the source directory, and checked for duplicates. Once all file data has been
written the completed super-block, compression options, inode, directory,
fragment, export, uid/gid lookup and xattr tables are written.
5.1 Compression options
-----------------------
Compressors can optionally support compression specific options (e.g.
dictionary size). If non-default compression options have been used, then
these are stored here.
5.2 Inodes
----------
Metadata (inodes and directories) are compressed in 8Kbyte blocks. Each
compressed block is prefixed by a two byte length, the top bit is set if the
block is uncompressed. A block will be uncompressed if the -noI option is set,
or if the compressed block was larger than the uncompressed block.
Inodes are packed into the metadata blocks, and are not aligned to block
boundaries, therefore inodes overlap compressed blocks. Inodes are identified
by a 48-bit number which encodes the location of the compressed metadata block
containing the inode, and the byte offset into that block where the inode is
placed (<block, offset>).
To maximise compression there are different inodes for each file type
(regular file, directory, device, etc.), the inode contents and length
varying with the type.
To further maximise compression, two types of regular file inode and
directory inode are defined: inodes optimised for frequently occurring
regular files and directories, and extended types where extra
information has to be stored.
5.3 Directories
---------------
Like inodes, directories are packed into compressed metadata blocks, stored
in a directory table. Directories are accessed using the start address of
the metablock containing the directory and the offset into the
decompressed block (<block, offset>).
Directories are organised in a slightly complex way, and are not simply
a list of file names. The organisation takes advantage of the
fact that (in most cases) the inodes of the files will be in the same
compressed metadata block, and therefore, can share the start block.
Directories are therefore organised in a two level list, a directory
header containing the shared start block value, and a sequence of directory
entries, each of which share the shared start block. A new directory header
is written once/if the inode start block changes. The directory
header/directory entry list is repeated as many times as necessary.
Directories are sorted, and can contain a directory index to speed up
file lookup. Directory indexes store one entry per metablock, each entry
storing the index/filename mapping to the first directory header
in each metadata block. Directories are sorted in alphabetical order,
and at lookup the index is scanned linearly looking for the first filename
alphabetically larger than the filename being looked up. At this point the
location of the metadata block the filename is in has been found.
The general idea of the index is ensure only one metadata block needs to be
decompressed to do a lookup irrespective of the length of the directory.
This scheme has the advantage that it doesn't require extra memory overhead
and doesn't require much extra storage on disk.
5.4 File data
-------------
Regular files consist of a sequence of contiguous compressed blocks, and/or a
compressed fragment block (tail-end packed block). The compressed size
of each datablock is stored in a block list contained within the
file inode.
To speed up access to datablocks when reading 'large' files (256 Mbytes or
larger), the code implements an index cache that caches the mapping from
block index to datablock location on disk.
The index cache allows Squashfs to handle large files (up to 1.75 TiB) while
retaining a simple and space-efficient block list on disk. The cache
is split into slots, caching up to eight 224 GiB files (128 KiB blocks).
Larger files use multiple slots, with 1.75 TiB files using all 8 slots.
The index cache is designed to be memory efficient, and by default uses
16 KiB.
5.5 Fragment lookup table
-------------------------
Regular files can contain a fragment index which is mapped to a fragment
location on disk and compressed size using a fragment lookup table. This
fragment lookup table is itself stored compressed into metadata blocks.
A second index table is used to locate these. This second index table for
speed of access (and because it is small) is read at mount time and cached
in memory.
5.6 Uid/gid lookup table
------------------------
For space efficiency regular files store uid and gid indexes, which are
converted to 32-bit uids/gids using an id look up table. This table is
stored compressed into metadata blocks. A second index table is used to
locate these. This second index table for speed of access (and because it
is small) is read at mount time and cached in memory.
5.7 Export table
----------------
To enable Squashfs filesystems to be exportable (via NFS etc.) filesystems
can optionally (disabled with the -no-exports Mksquashfs option) contain
an inode number to inode disk location lookup table. This is required to
enable Squashfs to map inode numbers passed in filehandles to the inode
location on disk, which is necessary when the export code reinstantiates
expired/flushed inodes.
This table is stored compressed into metadata blocks. A second index table is
used to locate these. This second index table for speed of access (and because
it is small) is read at mount time and cached in memory.
5.8 Xattr table
---------------
The xattr table contains extended attributes for each inode. The xattrs
for each inode are stored in a list, each list entry containing a type,
name and value field. The type field encodes the xattr prefix
("user.", "trusted." etc) and it also encodes how the name/value fields
should be interpreted. Currently the type indicates whether the value
is stored inline (in which case the value field contains the xattr value),
or if it is stored out of line (in which case the value field stores a
reference to where the actual value is stored). This allows large values
to be stored out of line improving scanning and lookup performance and it
also allows values to be de-duplicated, the value being stored once, and
all other occurences holding an out of line reference to that value.
The xattr lists are packed into compressed 8K metadata blocks.
To reduce overhead in inodes, rather than storing the on-disk
location of the xattr list inside each inode, a 32-bit xattr id
is stored. This xattr id is mapped into the location of the xattr
list using a second xattr id lookup table.
6. AUTHOR INFO
--------------
Squashfs was written by Phillip Lougher, email [email protected],
in Chepstow, Wales, UK. If you like the program, or have any problems,
then please email me, as it's nice to get feedback!相關推薦
路由器逆向分析------sasquatch和squashfs-tools工具的安裝和使用
一、sasquatch工具的安裝和使用 sasquatch工具支援對 非標準的SquashFS格式的檔案映象 進行解壓並且sasquatch工具也binwalk工具整合的一個功能元件之一。最新版的sasquatch工具是基於squashfs 4.3的原始碼修改而來的
路由器逆向分析------firmware-mod-kit工具安裝和使用說明
一、firmware-mod-kit工具的安裝 firmware-mod-kit工具的功能和binwalk工具的類似,其實firmware-mod-kit工具在功能上有呼叫binwalk工具提供的功能以及其他的韌體解包工具的整合。下載firmware-mod-kit工
路由器逆向分析------binwalk工具的詳細使用說明
一、binwalk工具的基本用法介紹 1.獲取幫助資訊 $ binwalk -h # 或者 $ binwalk --help 2.韌體分析掃描 $ binwalk firmware.bin # 或者 $ binwalk firmware.bin | head
路由器逆向分析------binwalk工具的安裝
一、binwalk工具執行支援的平臺 Operating System Core Support Optional Feature Support Ease of Installation Linux Excellent Excellent Very easy O
路由器逆向分析------MIPS交叉編譯環境的搭建(Buildroot)
為了能在我們熟悉的windows或者ubuntu下開發mips架構的程式,需要搭建mips程式的交叉編譯環境。mips程式的交叉編譯環境的構建需要用編譯Buildroot,Buildroot在編譯的過程中,會下載一些依賴包,所以在Buildroot的編譯安裝過程中必須確
路由器逆向分析------在Linux上安裝IDA Pro
Installing WineHQ packages If you have previously installed a Wine package from another repository, please remove it and any packages that depend on it (
路由器逆向分析------QEMU的基本使用方法(MIPS)
一、QEMU的執行模式 直接摘抄自己《揭祕家用路由器0day漏洞挖掘技術》,網上查了一下也沒有找到令人滿意的QEMU的使用說明,就採用這本書上的介紹。如果後期能夠找到比較滿意的QEMU的使用方法的說明,再新增上來。 QEMU模擬器主要有兩種比較常見的運作模式:Use
Navicat for MySQL數據庫管理工具安裝和破解
安裝目錄 http 數據庫 官方下載 有一個 .com x64 load 安裝 Navicat for MySQL官方下載地址:https://www.navicat.com/en/download/navicat-for-mysql 1、下載後安裝 navicat110_
inotify-tools工具安裝配置
inotify 文件監視 目錄改動監控 什麽是Inotify? Inotify一種強大的、細粒度的、異步文件系統監控機制,它滿足各種各樣的文件監控需要,可以監控文件系統的訪問屬性、讀寫屬性、權限屬性、刪除創建、移動等操作,也就是可以監控文件發生的一切變化。。 inotify-tools是一個C庫和
kail中tools的安裝和第一個php學習筆記
安裝tools 開啟 滑鼠右擊選擇 建立資料夾 mkdir cdrom 把tools檔案複製到 位置——計算機——cdrom資料夾下 開啟 cdrom cd cdrom 複製生成的目錄 解壓資料夾:tar zxvf 貼上目錄 回車 ls 複製目錄 cd 貼上目錄 ls 複製字尾為pl的目錄
PostgreSQL應用(一,環境搭建和客戶端工具安裝)
一,PostgreSQL下載 官方下載地址: https://www.postgresql.org/download/ pgAdmin4客戶端工具下載地址:https://www.pgadmin.org/download/pgadmin-4-windows/ 二,安裝 本次PostgreSQ
ubuntu16.04安裝教程及VMware Tools工具安裝
下面是安裝ubuntu16.04的教程,話不多說,看圖操作吧,首先建立虛擬機器, 這裡選擇64位,注意 這裡看個人情況分配磁碟大小,
Android中Dev Tools的安裝和使用
原文地址:http://blog.micro-studios.com/?p=790 SDK自帶的系統映象中,預設安裝了Dev Tools;因此,你可以在Androi模擬器上使用它。 使用Dev Tools,你可以開啟裝置上的很多設定,這讓測試和除錯應用程式變得更容易了。 如
Cygwin工具安裝和使用指導書
前言 Cygwin工具可以滿足你在Windows系統上學習Linux基本命令操作、指令碼除錯的基本需求。 Cygwin使用優點介紹 1、Cygwin安裝簡單,可以讓你免於安裝VMWARE+Linux映象。 2、Cygwin可以讓你在Windows系統上使用Li
siege壓力測試工具安裝和介紹
前言 最近公司有個專案需要做一個短輪詢類推送伺服器(推送伺服器分為三種,短輪詢,長輪詢,長連線),使用者量不大,但是為了保險起見還是做一下壓力測試.用的工具是siege. 目錄 1.siege介紹 輸入引數說明: 輸入名稱 解釋
【UML和UML Tools】 UML和模式應用
讀書筆記: 《UML和模式應用》 Craig Larman著 機械工作出版社 系統設計的關鍵問題: 如何為物件分配職責? 物件之間應該如何協作? 什麼樣的類應該做什麼樣的事情? 分析和設計: 分析:強調的是對問題和需求的調查研究,而不是解決方案。 (應該回答如下問
iw工具安裝和使用
iw 是一種新的基於 nl80211 的用於無線裝置的CLI配置實用程式。它支援最近已新增到核心所有新的驅動程式。採用無線擴充套件介面的舊工具iwconfig已被廢棄,強烈建議切換到 iw 和 nl8
樹莓派入門教程——I2C Tools的安裝和使用
轉載地址:http://www.embed-net.com/thread-143-1-1.html 前言 在進行I2C相關程式開發時,很多時候我們需要確認硬體是否正常連線,裝置是否正常工作,裝置的地址是多少等等,這裡我們就需要使用一個用於測試I2C匯流排的工具——i2c t
解決vmware tools工具安裝時出現的the path“”is not a valid問題
問題如圖這個問題是因為:1.你沒有裝kernel-devel2.你裝了kernel-devel但是版本與你的linux核心版本不相容(大概是這個意思)同樣也或出現gcc的這個問題,那就是沒裝gcc了。怎麼解決呢,首先使用#uname -r檢視你的核心,我裝的是centos7,
BurpSuit工具安裝和基本使用方法
burpsuite是滲透的必備工具,使用它可以進行一些截包分析,修改包資料、暴力破解、掃描等功能,使用最多的場景應該是設定代理攔截資料包分析資料和爆破。 JDK工具下載和安裝(可選) 執行BurpSuit工具依賴JDK,所以本地需要先安裝JDK軟體,如果已存在JDK,跳過此步驟。