
異常檢測演算法:Isolation Forest
iForest (Isolation Forest)是由Liu et al. [1] 提出來的基於二叉樹的ensemble異常檢測演算法,具有效果好、訓練快(線性複雜度)等特點。
1. 前言
iForest為聚類演算法,不需要標記資料訓練。首先給出幾個定義:
- 劃分(partition)指樣本空間一分為二,相當於決策樹中節點分裂;
- isolation指將某個樣本點與其他樣本點區分開。
iForest的基本思想非常簡單:完成異常點的isolation所需的劃分數大於正常樣本點(非異常)。如下圖所示:
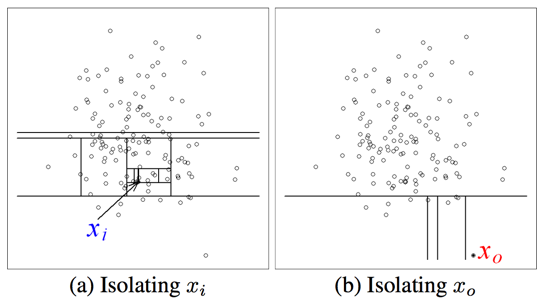
\(x_i\)樣本點的isolation需要大概12次劃分,而異常點\(x_0\)指需要4次左右。因此,我們可以根據劃分次數來區分是否為異常點。但是,如何建模呢?我們容易想到:劃分對應於決策樹中節點分裂,那麼劃分次數即為從決策樹的根節點到葉子節點所經歷的邊數,稱之為路徑長度(path length)。假設樣本集合共有\(n\)
\[ c(n) = 2H(n-1) -(2(n-1)/n) \]
其中,\(H(i)\)為harmonic number,可估計為\(\ln (i) + 0.5772156649\)。那麼,可建模anomaly score:
\[ s(x,n) = 2^{-\frac{E(h(x))}{c(n)}} \]
其中,\(h(x)\)為樣本點\(x\)的路徑長度,\(E(h(x))\)為iForest的多棵樹中樣本點\(x\)的路徑長度的期望。特別地,

當\(s\)值越高(接近於1),則表明該點越可能為異常點。若所有的樣本點的\(s\)
2. 詳解
iForest採用二叉決策樹來劃分樣本空間,每一次劃分都是隨機選取一個屬性值來做,具體流程如下:

停止分裂條件:
- 樹達到了最大高度;
- 落在孩子節點的樣本數只有一個,或者所有樣本點的值均相同;
為了避免錯檢(swamping)與漏檢(masking),在訓練每棵樹的時候,為了更好地區分,不會拿全量樣本,而會sub-sampling樣本集合。iForest的訓練流程如下:

sklearn給出了iForest與其他異常檢測演算法的比較。
3. 參考資料
[1] Liu, Fei Tony, Kai Ming Ting, and Zhi-Hua Zhou. "Isolation forest." Data Mining, 2008. ICDM'08. Eighth IEEE International Conference on
相關推薦
異常檢測演算法:Isolation Forest
iForest (Isolation Forest)是由Liu et al. [1] 提出來的基於二叉樹的ensemble異常檢測演算法,具有效果好、訓練快(線性複雜度)等特點。 1. 前言 iForest為聚類演算法,不需要標記資料訓練。首先給出幾個定義: 劃分(partition)指樣本空間一分為二,相
白話異常檢測演算法Isolation Forest
前言 好久沒講演算法了,今天分享一個異常點檢測演算法Isolation Forest。之前也是沒聽說過這個演算法,中文名叫孤立森林,聽客戶講了就順便查了下這個演算法的論文,感覺還是非常有用滴。 異常檢測的概念 首先聊下什麼是異常檢測,異常檢測就是發現一堆資料中
異常檢測演算法--isolation forest
轉自: http://www.cnblogs.com/fengfenggirl/p/iForest.html 南大周志華老師在2010年提出一個異常檢測演算法Isolation Forest,在工業界很實用,演算法效果好,時間效率高,能有效處理高維資料和海量資料,這裡對這個
[吳恩達機器學習筆記]15.1-3非監督學習異常檢測演算法/高斯回回歸模型
15.異常檢測 Anomaly detection 覺得有用的話,歡迎一起討論相互學習~Follow Me 15.1問題動機 Problem motivation 飛機引擎異常檢測
常用目標檢測演算法:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD
一、目標檢測常見演算法 object detection,就是在給定的圖片中精確找到物體所在位置,並標註出物體的類別。所以,object detection要解決的問題就是物體在哪裡以及是什麼的整個流程問題。
sklearn中異常檢測演算法建模彙總
借鑑於http://scikit-learn.org/stable/modules/outlier_detection.html#novelty-and-outlier-detection 一、概況 兩大異常 novelty detection 這些訓練資料沒有被異常值所汙染,我們有
斯坦福大學機器學習筆記——異常檢測演算法(高斯分佈、多元高斯分佈、異常檢測演算法)
異常檢測問題介紹: 異常檢測演算法主要用於無監督學習問題,但從某種角度看它又類似於一種有監督學習的問題,下面我們從一個例子中簡單介紹一下什麼是異常檢測問題。 比如我們有一個飛機引擎製造商,對於一個新造出的飛機引擎我們想判斷這個引擎是不是異常的。 假如我們有
基於圖的異常檢測演算法——概述
正在調研基於圖的異常檢測演算法,先出個概述,後面再慢慢填坑 基於圖的異常檢測給定一個圖資料庫,找到其中罕見不同於其他資料物件的點/邊/子結構 靜態圖的異常檢測 普通靜態圖 基於結構
目標檢測演算法:RCNN、YOLO vs DPM
以下內容節選自我的研究報告。 1. 背景 目標檢測(object detection)簡單說就是框選出目標,並預測出類別的一個任務。它是一種基於目標幾何和統計特徵的影象分割,將目標的分割和識別合
時間序列異常檢測演算法S-H-ESD
1. 基於統計的異常檢測 Grubbs' Test Grubbs' Test為一種假設檢驗的方法,常被用來檢驗服從正太分佈的單變數資料集(univariate data set)\(Y\) 中的單個異常值。若有異常值,則其必為資料集中的最大值或最小值。原假設與備擇假設如下: \(H_0\): 資料集中沒有異常
基於深度學習的目標檢測演算法:Faster R-CNN
問題引入: R-CNN、SPP net、Fast R-CNN等目標檢測演算法,它們proposals都是事先通過selecetive search方法得到。然而,這一過程將耗費大量的時間,從而影響目標檢測系統的實時性。Faster R-CNN針對這一問題,提
碰撞檢測演算法:點和矩形碰撞、矩形碰撞
以下程式碼Lua可直接除錯. 點與矩形碰撞 -- 點與矩形碰撞 function testPoint(x0,y0,w0,h0,x1,y1) return x1 >= x0 and x1 <= x0 + w0 and y1>=y0
UEBA 學術界研究現狀——用戶行為異常檢測思路:序列挖掘prefixspan,HMM,LSTM/CNN,SVM異常檢測,聚類CURE算法
改進 處理 業務 class 動態 大型 clas 基於用戶 模式 論文 技術分析《關於網絡分層信息泄漏點快速檢測仿真》 "1、基於動態閾值的泄露點快速檢測方法,采樣Mallat算法對網絡分層信息的離散采樣數據進行離散小波變換;利用滑動窗口對該尺度上的小波系數進行加窗處理,
異常檢測演算法演變及學習筆記
【說在前面】本人部落格新手一枚,象牙塔的老白,職業場的小白。以下內容僅為個人見解,歡迎批評指正,不喜勿噴![認真看圖][認真看圖] 【補充說明】異常檢測,又稱離群點檢測,有著廣泛應用。例如金融反欺詐、工業損毀檢測、電網竊電行為等! 一、基於時間序列分析 關於時間序列分析的介紹,歡迎瀏覽我的另一篇部
【異常檢測】孤立森林(Isolation Forest)演算法簡介
# 簡介 工作的過程中經常會遇到這樣一個問題,在構建模型訓練資料時,我們很難保證訓練資料的純淨度,資料中往往會參雜很多被錯誤標記噪聲資料,而資料的質量決定了最終模型效能的好壞。如果進行人工二次標記,成本會很高,我們希望能使用一種無監督演算法幫我們做這件事,異常檢測演算法可以在一定程度上解決這個問題。
【異常檢測】Isolation forest 的spark 分布式實現
交流 國內 所有 eal vat cost replace 如果 ola 1.算法簡介 算法的原始論文 http://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/icdm08b.pdf 。python的sklearn中已
簡要介紹Active Learning(主動學習)思想框架,以及從IF(isolation forest)衍生出來的演算法:FBIF(Feedback-Guided Anomaly Discovery)
1. 引言 本文所討論的內容為筆者對外文文獻的翻譯,並加入了筆者自己的理解和總結,文中涉及到的原始外文論文和相關學習連結我會放在reference裡,另外,推薦讀者朋友購買 Stephen Boyd的《凸優化》Convex Optimization這本書,封面一半橘黃色一半白色的,有國內學者翻譯成了中文版,
Python機器學習筆記:異常點檢測演算法——LOF(Local Outiler Factor)
完整程式碼及其資料,請移步小編的GitHub 傳送門:請點選我 如果點選有誤:https://github.com/LeBron-Jian/MachineLearningNote 在資料探勘方面,經常需要在做特徵工程和模型訓練之前對資料進行清洗,剔除無效資料和異常資料。異常檢測也是資料探勘的一個方
目標檢測演算法理解:從R-CNN到Mask R-CNN
因為工作了以後時間比較瑣碎,所以更多的時候使用onenote記錄知識點,但是對於一些演算法層面的東西,個人的理解畢竟是有侷限的。我一直做的都是影象分類方向,最近開始接觸了目標檢測,也看了一些大牛的論文,雖然網上已經有很多相關的演算法講解,但是每個人對同一個問題的理解都不太一樣,本文主
Andrew Ng 機器學習筆記 14 :異常檢測
異常檢測問題 高斯分佈 高斯分佈中,μ和σ的關係 異常檢測的具體演算法 異常檢測演算法步驟總結 異常檢測 VS 監督學習 對不服從高斯分佈的資料進行