
時間序列異常檢測演算法S-H-ESD
1. 基於統計的異常檢測
Grubbs' Test
Grubbs' Test為一種假設檢驗的方法,常被用來檢驗服從正太分佈的單變數資料集(univariate data set)\(Y\) 中的單個異常值。若有異常值,則其必為資料集中的最大值或最小值。原假設與備擇假設如下:
\(H_0\): 資料集中沒有異常值
\(H_1\): 資料集中有一個異常值
Grubbs' Test檢驗假設的所用到的檢驗統計量(test statistic)為
\[ G = \frac{\max |Y_i - \overline{Y}|}{s} \]
其中,\(\overline{Y}\)為均值,\(s\)為標準差。原假設\(H_0\)
\[ G > \frac{(N-1)}{\sqrt{N}}\sqrt{\frac{ (t_{\alpha/(2N), N-2})^2}{N-2 + (t_{\alpha/(2N), N-2})^2}} \]
其中,\(N\)為資料集的樣本數,\(t_{\alpha/(2N), N-2}\)為顯著度(significance level)等於\(\alpha/(2N)\)、自由度(degrees of freedom)等於\(N-2\)的t分佈臨界值。實際上,Grubbs' Test可理解為檢驗最大值、最小值偏離均值的程度是否為異常。
ESD
在現實資料集中,異常值往往是多個而非單個。為了將Grubbs' Test擴充套件到\(k\)
- 計算與均值偏離最遠的殘差,注意計算均值時的資料序列應是刪除上一輪最大殘差樣本資料後;
\begin{equation}
R_j = \frac{\max_i |Y_i - \overline{Y'}|}{s}, \quad 1 \leq j \leq k
\label{eq:esd_test}
\end{equation}
- 計算臨界值(critical value);
\[ \lambda_j = \frac{(n-j) * t_{p,n-j-1}}{\sqrt{(n-j-1+t_{p,n-j-1}^2)(n-j+1)}}, \quad 1 \leq j \leq k \]
檢驗原假設,比較檢驗統計量與臨界值;若\(R_i > \lambda_j\),則原假設\(H_0\)不成立,該樣本點為異常點;
重複以上步驟\(k\)次至演算法結束。
2. 時間序列的異常檢測
鑑於時間序列資料具有周期性(seasonal)、趨勢性(trend),異常檢測時不能作為孤立的樣本點處理;故而Twitter的工程師提出了S- ESD (Seasonal ESD)與S-H-ESD (Seasonal Hybrid ESD)演算法,將ESD擴充套件到時間序列資料。
S-ESD
STL將時間序列資料分解為趨勢分量、週期分量和餘項分量。想當然的解法——將ESD運用於STL分解後的餘項分量中,即可得到時間序列上的異常點。但是,我們會發現在餘項分量中存在著部分假異常點(spurious anomalies)。如下圖所示:
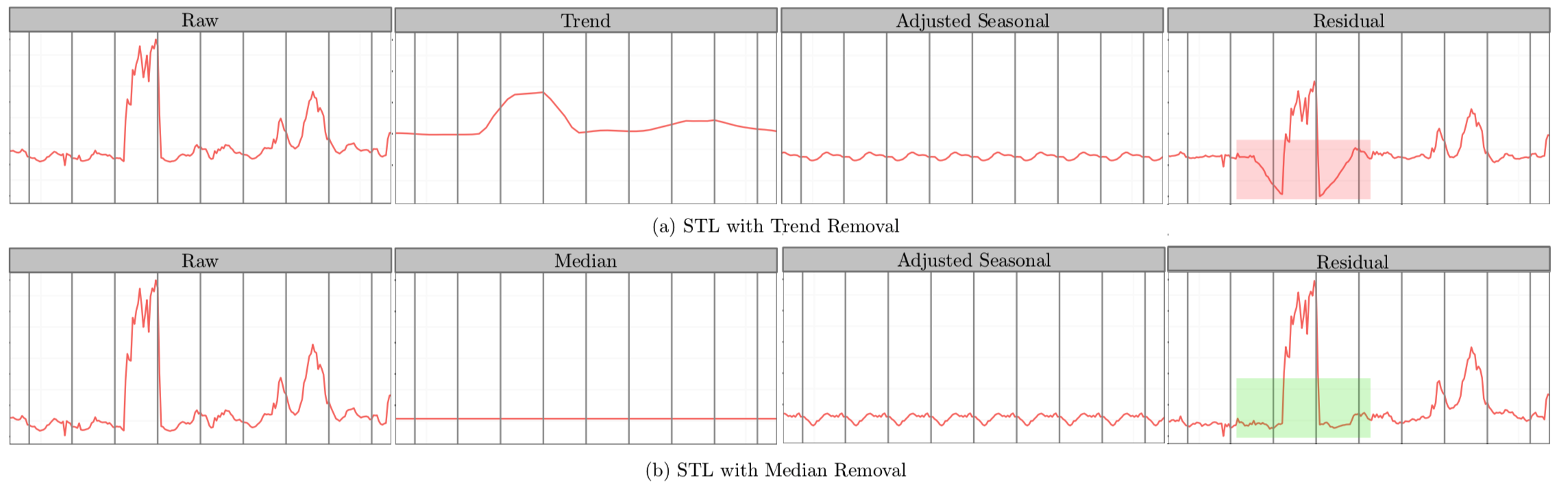
在紅色矩形方框中,向下突起點被誤報為異常點。為了解決這種假陽性降低準確率的問題,S-ESD演算法用中位數(median)替換掉趨勢分量;餘項計算公式如下:
\[ R_X = X - S_X- \tilde{X} \]
其中,\(X\)為原時間序列資料,\(S_X\)為STL分解後的週期分量,\(\tilde{X}\)為\(X\)的中位數。
S-H-ESD
由於個別異常值會極大地拉伸均值和方差,從而導致S-ESD未能很好地捕獲到部分異常點,召回率偏低。為了解決這個問題,S-H-ESD採用了更具魯棒性的中位數與絕對中位差(Median Absolute Deviation, MAD)替換公式\eqref{eq:esd_test}中的均值與標準差。MAD的計算公式如下:
\[ MAD = median(|X_i - median(X)|) \]
3. 參考資料
[1] Hochenbaum, Jordan, Owen S. Vallis, and Arun Kejariwal. "Automatic Anomaly Detection in the Cloud Via Statistical Learning." arXiv preprint arXiv:1704.07706 (2017).
相關推薦
時間序列異常檢測演算法S-H-ESD
1. 基於統計的異常檢測 Grubbs' Test Grubbs' Test為一種假設檢驗的方法,常被用來檢驗服從正太分佈的單變數資料集(univariate data set)\(Y\) 中的單個異常值。若有異常值,則其必為資料集中的最大值或最小值。原假設與備擇假設如下: \(H_0\): 資料集中沒有異常
基於Spark技術實現大規模時間序列異常檢測成功落地
最近一直忙於異常檢測專案的上線,一直沒有時間來更新部落格,該系統已經在大規模時間序列場景穩定執行1個多月,簡單總結一下。 達到的目標,通過Spark對3萬個伺服器進行預測,每個伺服器包括5個指標,每個指標對應一個時間序列,模型全量15萬,全量訓練用21個Core耗時3個小
[吳恩達機器學習筆記]15.1-3非監督學習異常檢測演算法/高斯回回歸模型
15.異常檢測 Anomaly detection 覺得有用的話,歡迎一起討論相互學習~Follow Me 15.1問題動機 Problem motivation 飛機引擎異常檢測
時間序列聚類演算法-《k-Shape: Efficient and Accurate Clustering of Time Series》解讀
摘要 本文提出了一個新穎的時間序列聚類演算法k-shape,該演算法的核心是迭代增強過程,可以生成同質且較好分離的聚類。該演算法採用標準的互相關距離衡量方法,基於此距離衡量方法的特性,提出了一個計算簇心的方法,在每一次迭代中都用它來更新時間序列的聚類分配。作者通過大量和具有
sklearn中異常檢測演算法建模彙總
借鑑於http://scikit-learn.org/stable/modules/outlier_detection.html#novelty-and-outlier-detection 一、概況 兩大異常 novelty detection 這些訓練資料沒有被異常值所汙染,我們有
斯坦福大學機器學習筆記——異常檢測演算法(高斯分佈、多元高斯分佈、異常檢測演算法)
異常檢測問題介紹: 異常檢測演算法主要用於無監督學習問題,但從某種角度看它又類似於一種有監督學習的問題,下面我們從一個例子中簡單介紹一下什麼是異常檢測問題。 比如我們有一個飛機引擎製造商,對於一個新造出的飛機引擎我們想判斷這個引擎是不是異常的。 假如我們有
基於圖的異常檢測演算法——概述
正在調研基於圖的異常檢測演算法,先出個概述,後面再慢慢填坑 基於圖的異常檢測給定一個圖資料庫,找到其中罕見不同於其他資料物件的點/邊/子結構 靜態圖的異常檢測 普通靜態圖 基於結構
白話異常檢測演算法Isolation Forest
前言 好久沒講演算法了,今天分享一個異常點檢測演算法Isolation Forest。之前也是沒聽說過這個演算法,中文名叫孤立森林,聽客戶講了就順便查了下這個演算法的論文,感覺還是非常有用滴。 異常檢測的概念 首先聊下什麼是異常檢測,異常檢測就是發現一堆資料中
序列異常檢測
序列在現實世界中是非常常見的一種資料形式,即在時間維度上感測器採集的資料流。我們最常見的序列資料像語音,自然語言,視訊等訊號,它們的共同點就是有很強的上下文。一般而言,任何高階有效的模型在處理這種資料時都會考慮這種上下文關係,充分挖掘潛藏的時空相關性,以對資料進
異常檢測演算法:Isolation Forest
iForest (Isolation Forest)是由Liu et al. [1] 提出來的基於二叉樹的ensemble異常檢測演算法,具有效果好、訓練快(線性複雜度)等特點。 1. 前言 iForest為聚類演算法,不需要標記資料訓練。首先給出幾個定義: 劃分(partition)指樣本空間一分為二,相
時間序列挖掘-預測演算法-三次指數平滑法(Holt-Winters)
在時間序列中,我們需要基於該時間序列當前已有的資料來預測其在之後的走勢,三次指數平滑(Triple/Three Order Exponential Smoothing,Holt-Winters)演算法可以很好的進行時間序列的預測。 時間序列資料一般有以下幾種特點:
異常檢測演算法--isolation forest
轉自: http://www.cnblogs.com/fengfenggirl/p/iForest.html 南大周志華老師在2010年提出一個異常檢測演算法Isolation Forest,在工業界很實用,演算法效果好,時間效率高,能有效處理高維資料和海量資料,這裡對這個
異常檢測演算法演變及學習筆記
【說在前面】本人部落格新手一枚,象牙塔的老白,職業場的小白。以下內容僅為個人見解,歡迎批評指正,不喜勿噴![認真看圖][認真看圖] 【補充說明】異常檢測,又稱離群點檢測,有著廣泛應用。例如金融反欺詐、工業損毀檢測、電網竊電行為等! 一、基於時間序列分析 關於時間序列分析的介紹,歡迎瀏覽我的另一篇部
深度學習應用於時間序列資料的異常檢測
本文關鍵點 神經網路是一種模仿生物神經元的機器學習模型,資料從輸入層進入並流經啟用閾值的多個節點。遞迴性神經網路一種能夠對之前輸入資料進行內部儲存記憶的神經網路,所以他們能夠學習到資料流中的時間依賴結構。 如今機器學習已經被應用到很多的產品中去了,例如,siri、Goog
基於時間序列的異常檢測系統的實現思路之一
技術方案:Spark、kafka、opentsdb、Yahoo的egads 模型靜態訓練:採用兩種演算法進行模型的訓練:指數移動平均和HotWinters,模型一天訓練一次,即每天0點開始訓練,每天凌晨0:5分根據訓練好的模型進行異常檢測,具體包括點的預測以及點的異常檢測;
Predix平臺上通過分類器實現時間序列的實時異常檢測
Author: Alex Zhang,Data Scientist,GE Digital 內容簡介 本文提供了在Predix上進行資料分析的例項 。該例項 通過AnalyticFramework
檢測使用者命令序列異常——使用LSTM分類演算法【使用樸素貝葉斯,類似垃圾郵件分類的做法也可以,將命令序列看成是垃圾郵件】
# -*- coding:utf-8 -*- import sys import re import numpy as np import nltk import csv import matplotlib.pyplot as plt from nltk.probability import Fre
多元季節性時間序列模型SARIMAX的應用——預測與異常診斷
import pandas as pd import numpy as np import matplotlib.pylab as plt from matplotlib.pylab import rcParams rcParams["figure.figsize"] = 15,6 #讀取資料 f
時間序列預測演算法總結
時間序列演算法 time series data mining 主要包括decompose(分析資料的各個成分,例如趨勢,週期性),prediction(預測未來的值),classification(對有序資料序列的feature提取與分類),clustering(相似數列聚類)等。 時間序
檢測用戶命令序列異常——使用LSTM分類算法
trac sta red index with open .py dex rip utils 通過 搜集 Linux 服務器 的 bash 操作 日誌, 通過 訓練 識別 出 特定 用戶 的 操作 習慣, 然後 進一步 識別 出 異常 操作 行為。使用 SEA 數據 集 涵