
白話異常檢測演算法Isolation Forest
前言
好久沒講演算法了,今天分享一個異常點檢測演算法Isolation Forest。之前也是沒聽說過這個演算法,中文名叫孤立森林,聽客戶講了就順便查了下這個演算法的論文,感覺還是非常有用滴。
異常檢測的概念
首先聊下什麼是異常檢測,異常檢測就是發現一堆資料中的異常點。可以應用到很多領域,比如:
-
噪聲資料的排查
-
新的天體的發現
-
異常的網路攻擊的發現
-
異常的信用卡購物記錄的發現
異常點在資料分析領域非常有用途,目前常用的異常點檢測有以下幾種:
基於距離的異常檢測:遍歷所有的資料點之間的距離,與大部分資料的距離都比較遠的點,就是異常點。這麼算的結果比較準,但是基於距離的計算複雜度高,計算開銷大。
基於密度的異常點檢測:基於密度也比較好理解,就是normal資料一定是處於密度集中的區域,anormal資料一定是在相對稀疏的領域。同樣有計算開銷的問題,密度本質上也是一種距離計算。
Isolation Forest演算法,本質上是一種平面切分的理念,計算成本比較小,下面我們詳細介紹下。
Isolation Forest
理解它概念可能需要一些空間幾何的背景,我們可以想象所有的資料點都是在一個n維空間分佈的,n取決於資料的欄位個數,理論上可以通過平面切分的方式將任意一個點與其它點隔離開。
Isolation Forest的思路就是,如果是normal資料,你需要更多地切割平面才能區分這條資料。如果是anormal資料,就可以用較少的平面切割。如下圖所示:
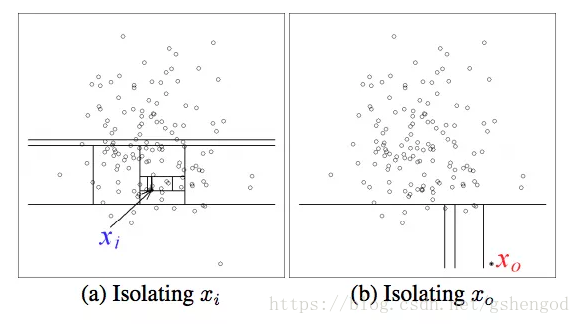
如果要區分
- (a)圖中的點,這個點顯然是個normal資料,需要非常多的切割平面,
- (b)中的anormal資料需要的切割面就比較少。
於是基於這樣的理論,需要一種數學模型來表示切割平面個數以及資料的關係,二叉樹就是一種合適的方式。
可以用樹的深度表示切割平面數,每條資料對應二叉樹中的一個節點。資料的切割面越多,資料在二叉樹中的縱深越深。
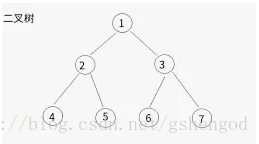
這樣建模有一個很大的好處,如果目的是找出異常點,那麼不需要每一個二叉樹都完整建立,也就是不需要每次都遍歷所有資料,因為要找的異常點是每棵樹比較靠近父節點的節點,非常的節約計算資源。
ok~關於Isolation Forest就介紹這麼多,希望對大家有幫助,提前預祝大家十一玩的愉快。