
神經網路訓練loss不下降原因集合
train loss與test loss結果分析
train loss 不斷下降,test loss不斷下降,說明網路仍在學習;
train loss 不斷下降,test loss趨於不變,說明網路過擬合;
train loss 趨於不變,test loss不斷下降,說明資料集100%有問題;
train loss 趨於不變,test loss趨於不變,說明學習遇到瓶頸,需要減小學習率或批量數目;
train loss 不斷上升,test loss不斷上升,說明網路結構設計不當,訓練超引數設定不當,資料集經過清洗等問題。
例項
這段在使用caffe的時候遇到了兩個問題都是在訓練的過程中loss基本保持常數值,特此記錄一下。
1.loss等於87.33不變
loss等於87.33這個問題是在對Inception-V3網路不管是fine-tuning還是train的時候遇到的,無論網路迭代多少次,網路的loss一直保持恆定。
查閱相關資料以後發現是由於loss的最大值由FLT_MIN計算得到,FLT_MIN是1.17549435e−38F1.17549435e−38F其對應的自然對數正好是-87.3356,這也就對應上了loss保持87.3356了。
這說明softmax在計算的過程中得到了概率值出現了零,由於softmax是用指數函式計算的,指數函式的值都是大於0的,所以應該是計算過程中出現了float溢位的異常,也就是出現了inf,nan等異常值導致softmax輸出為0.
當softmax之前的feature值過大時,由於softmax先求指數,會超出float的資料範圍,成為inf。inf與其他任何數值的和都是inf,softmax在做除法時任何正常範圍的數值除以inf都會變成0.然後求loss就出現了87.3356的情況。
解決辦法
由於softmax輸入的feature由兩部分計算得到:一部分是輸入資料,另一部分是各層的權值等組成
減小初始化權重,以使得softmax的輸入feature處於一個比較小的範圍
降低學習率,這樣可以減小權重的波動範圍
如果有BN(batch normalization)層,finetune時最好不要凍結BN的引數,否則資料分佈不一致時很容易使輸出值變得很大(注意將batch_norm_param中的use_global_stats設定為false )。
觀察資料中是否有異常樣本或異常label導致資料讀取異常
本文遇到的情況採用降低學習率的方法,learning rate設定為0.01或者原來loss的1/5或者1/10。
2.loss保持0.69左右
採用VGG-16在做一個二分類問題,所以計算loss時等價與下面的公式:
loss=−log(Pk==label)loss=−log(Pk==label)
當p=0.5時,loss正好為0.693147,也就是訓練過程中,無論如何調節網路都不收斂。最初的網路配置檔案卷積層的引數如下所示:
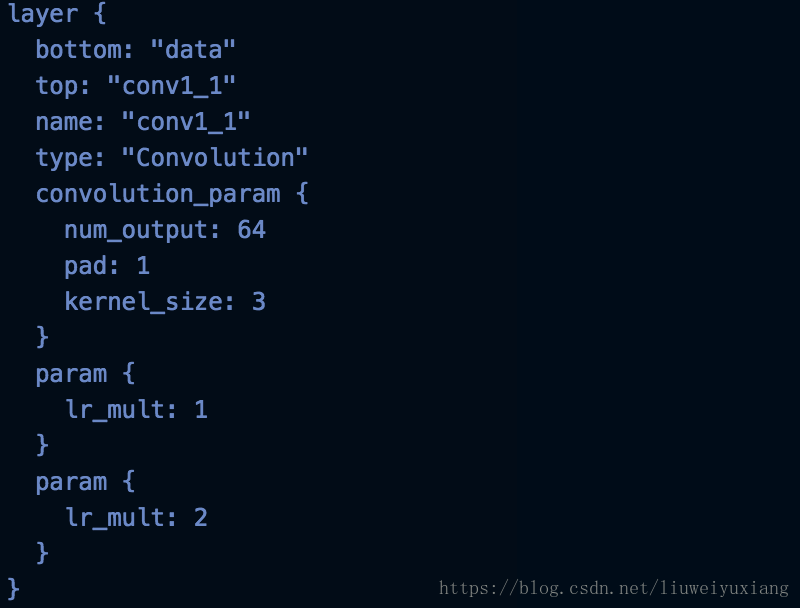
從VGG-16訓練好的模型進行fine-tuning也不發生改變,當在網路中加入初始化引數和decay_mult以後再次訓練網路開始收斂。

但是具體是什麼原因造成的,暫時還沒有找到,難道是初始化引數的問題還是?
總結
loss一直不下降的原因有很多,可以從頭到尾濾一遍: 1)資料的輸入是否正常,data和label是否一致。 2)網路架構的選擇,一般是越深越好,也分資料集。 並且用不用在大資料集上pre-train的引數也很重要的 3)loss 公式對不對。
相關部落格推薦
相關推薦
神經網路訓練loss不下降原因集合
train loss與test loss結果分析 train loss 不斷下降,test loss不斷下降,說明網路仍在學習; train loss 不斷下降,test loss趨於不變,說明網路過擬合; train loss 趨於不變,test loss不斷下降,說
訓練loss不下降原因集合
一,train loss與test loss結果分析 train loss 不斷下降,test loss不斷下降,說明網路仍在學習; train loss 不斷下降,test loss趨於不變,說明網路過擬合; train loss 趨於不變,test loss不斷下降,說明資料集100
為什麼使用神經網路訓練得到的語言模型不需要做資料平滑
我們都知道,在自然語言處理的語言模型裡面,最核心的就是計算得到一個句子的概率,為了得到這個概率,我們需要計算得到一系列的條件概率。這些條件概率就是整個語言模型的引數。 為了得到條件概率,我們可以有兩種不同的方法。 第一種就是使用統計概率方法,通過統計的方法得到不同的詞對的條件概率。這種方
神經網路訓練中,傻傻分不清Epoch、Batch Size和迭代
你肯定經歷過這樣的時刻,看著電腦螢幕抓著頭,困惑著:「為什麼我會在程式碼中使用這三個術語,它們有什麼區別嗎?」因為它們看起來實在太相似了。 為了理解這些術語有什麼不同,你需要了解一些關於機器學習的術語,比如梯度下降,以幫助你理解。 這裡簡單總結梯度下降的含義… 梯度下降 這是一個在機器學習中用於尋找最
caffe訓練CNN時,loss不收斂原因分析
人工智慧/機器學習/深度學習交流QQ群:811460433 也可以掃一掃下面二維碼加入微信群,如果二維碼失效,可以新增博主個人微信,拉你進群 1. 資料和標籤 資料分類標註是否準確?資料是否乾淨? 另外博主經歷過自己建立資料的時候資料標籤設定為1,2,...,N,
斯坦福cs231n學習筆記(11)------神經網路訓練細節(梯度下降演算法大總結/SGD/Momentum/AdaGrad/RMSProp/Adam/牛頓法)
神經網路訓練細節系列筆記: 通過學習,我們知道,因為訓練神經網路有個過程: <1>Sample 獲得一批資料; <2>Forward 通過計算圖前向傳播,獲得loss; <3>Backprop 反向傳播計算梯度,這
神經網路訓練中的訓練集、驗證集以及測試集合
1:在NN訓練中我們很常用的是訓練集合以及測試集合,在訓練集合上訓練模型(我個人認為模型就是訓練的方法以及對應的引數值,更偏重於引數值吧),訓練好之後拿到測試集合上驗證模型的泛華(就是該模型可以拿去實戰的效果)的能力。 2:但是對於上述情況,舉個例子,比如是在訓練一個多層
神經網路訓練時,出現NaN loss
1、梯度爆炸 原因:在學習過程中,梯度變得非常大,使得學習的過程偏離了正常的軌跡 症狀:觀察輸出日誌(runtime log)中每次迭代的loss值,你會發現loss隨著迭代有明顯的增長,最後因為loss值太大以至於不能用浮點數去表示,所以變成了NaN。 可採取的方法:1.
Loss和神經網路訓練
1.訓練 在前一節當中我們討論了神經網路靜態的部分:包括神經網路結構、神經元型別、資料部分、損失函式部分等。這個部分我們集中講講動態的部分,主要是訓練的事情,集中在實際工程實踐訓練過程中要注意的一些點,如何找到最合適的引數。 1.1 關於梯度檢驗 之前
TensorFlow官方文件樣例——三層卷積神經網路訓練MNIST資料
上篇部落格根據TensorFlow官方文件樣例實現了一個簡單的單層神經網路模型,在訓練10000次左右可以達到92.7%左右的準確率。但如果將神經網路的深度拓展,那麼很容易就能夠達到更高的準確率。官方中文文件中就提供了這樣的樣例,它的網路結構如
#####好好好好####Keras深度神經網路訓練分類模型的四種方法
Github程式碼: Keras樣例解析 歡迎光臨我的部落格:https://gaussic.github.io/2017/03/03/imdb-sentiment-classification/ (轉載請註明出處:https://gaussic.github.io) Keras的官方E
【opencv3--ANN神經網路訓練識別OCR資料集】
#include <string> #include <iostream> #include <opencv2\opencv.hpp> #include <opencv2\ml.hpp> #include<fstream> using n
Tensorpack,一個基於TensorFlow的神經網路訓練介面,原始碼包含很多示例
Tensorpack是一個基於TensorFlow的神經網路訓練介面。 https://github.com/tensorpack/tensorpack 特徵: 它是另一個TF高階API,具有速度,可讀性和靈活性。
深度學習神經網路訓練調參技巧
本文主要介紹8種實現細節的技巧或tricks:資料增廣、影象預處理、網路初始化、訓練過程中的技巧、啟用函式的選擇、不同正則化方法、來自於資料的洞察、整合多個深度網路的方法原文如下:http://blog.csdn.net/u013709270/article/details/70949304。
TensorFlow遊樂園介紹及其神經網路訓練過程
TensorFlow遊樂場是一個通過網頁瀏覽器就可以訓練簡單神經網路。並實現了視覺化訓練過程的工具。遊樂場地址為http://playground.tensorflow.org/ 一、TensorFlow遊樂園引數介紹&nb
神經網路學習——入門(不定時更新)
主要功能:分類識別(影象、語音、文字)。其中影象和語音:密集型矩陣,文字:稀疏型矩陣 網路結構:每層的節點不一定太多,但層數在一直增長。 更深的神經網路比寬的神經網路,學習花費更低。比如10層網路能解決的問題,如果用單層解決,可能需要幾千個節點。 每一層可以理解為一層理解力 如果每一
神經網路訓練中Epoch、batch_size、iterator的關係
為了理解這些術語的不同,需要先了解些機器學習術語,如:梯度下降 梯度下降 這是一個在機器學習中用於尋找最佳結果(曲線的最小值)的迭代優化演算法。 梯度的含義是斜率或者斜坡的傾斜度。 下降的含義是代價函式的下降。 演算法是迭代的,意思是需要多次使用演算法獲取結果,以得
將神經網路訓練成一個“放大鏡”
摘要: 想不想將神經網路訓練成一個“放大鏡”?我們就訓練了一個這樣炫酷的神經網路,點選文章一起看下吧! 低解析度蝴蝶的放大 當我們網購時,我們肯定希望有一個貼近現實的購物體驗,也就是說能夠全方位的看清楚產品的細節。而解析度高的大影象能夠對商品進行更加詳細的介紹,這真的可以改變顧客的購物體驗,
為什麼在神經網路裡面使用梯度下降法對模型的權值矩陣進行調整
我們都知道,神經網路是先將模型引數的調整問題轉換為一個求某個損失函式的極小值問題,然後通過梯度下降演算法讓引數選擇合適的值使得該損失函式取得極小值。那麼為什麼梯度下降演算法可以完成這個任務呢? 假設一個
BP神經網路——訓練一個加法運算
#include <stdio.h> #include <math.h> #include <time.h> #include <stdlib.h> #define num 3000 #define learn 0.001 double qian