
基於LSTM和遷移學習的文字分類模型說明(Tensorflow)
考慮到在實際應用場景中,資料有可能後續增加,另外,類別也有可能重新分配,比如銀行業務中的[取款兩萬以下]和[取款兩萬以上]後續可能合併為一類[取款],而重新訓練模型會浪費大量時間,因此我們考慮使用遷移學習來縮短訓練時間。即保留LSTM層的各權值變數,然後重新構建全連線層,即圖中的Softmax層。
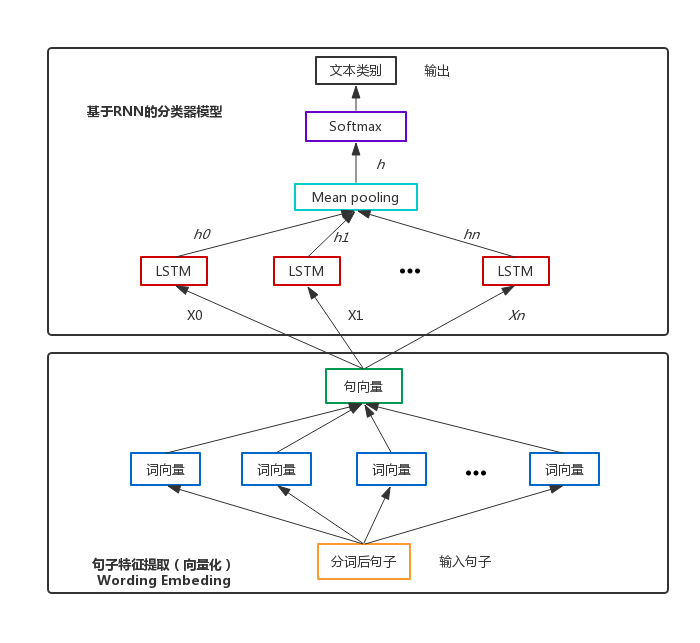
分類器模型結構圖
具體遷移過程如下(程式碼基於Python3.5/Tensorflow1.2 github程式碼地址):
Step1 構建網路模型
with tf.name_scope("Train"): with tf.variable_scope("Model", reuse=None, initializer=initializer): model = RNN_Model(config=config, num_classes=num_classes, is_training=True) with tf.name_scope("Valid"): with tf.variable_scope("Model", reuse=True, initializer=initializer): valid_model = RNN_Model(config=valid_config, num_classes=num_classes, is_training=False)
Step1 構建網路模型
Step2 初始化變數(這一步要先做,以免覆蓋後續載入的Variable)
Step3 restore之前儲存的網路權值,這裡做了判斷
如果沒有模型檔案的話就從頭開始訓練
有模型檔案存在,但是輸出類別沒有發生變化的話,就接著訓練
有模型檔案,同時輸出類別發生了改變,就進行遷移學習
if os.path.exists(checkpoint_dir): classes_file = codecs.open(os.path.join(config.out_dir, "classes"), "r", "utf-8") classes = list(line.strip() for line in classes_file.readlines()) classes_file.close() # 類別是否發生改變 if sorted(classify_names) == sorted(classes): print('-----continue training-----') new_classify_files = [] for c in classes: idx = classify_names.index(c) new_classify_files.append(classify_files[idx]) # classify_files = new_classify_files restored_saver = tf.train.Saver(tf.global_variables()) ckpt = tf.train.get_checkpoint_state(checkpoint_dir) if ckpt and ckpt.model_checkpoint_path: print('restore model: '.format(ckpt.model_checkpoint_path)) restored_saver.restore(session, ckpt.model_checkpoint_path) else: print('-----train from beginning-----') else: print('-----change network-----') not_restore = ['softmax_w:0', 'softmax_b:0'] restore_var = [v for v in tf.global_variables() if v.name.split('/')[-1] not in not_restore] restored_saver = tf.train.Saver(restore_var) ckpt = tf.train.get_checkpoint_state(checkpoint_dir) if ckpt and ckpt.model_checkpoint_path: print('restore model: '.format(ckpt.model_checkpoint_path)) restored_saver.restore(session, ckpt.model_checkpoint_path) else: pass classes_file = codecs.open(os.path.join(config.out_dir, "classes"), "w", "utf-8") for classify_name in classify_names: classes_file.write(classify_name) classes_file.write('\n') classes_file.close() else: print('-----train from begin-----') os.makedirs(checkpoint_dir) classes_file = codecs.open(os.path.join(config.out_dir, "classes"), "w", "utf-8") for classify_name in classify_names: classes_file.write(classify_name) classes_file.write('\n') classes_file.close()
Step4 開始訓練
經驗證,很快loss就收斂了,由於資料的變動不是很大,因此一個epoch就能到達收斂,持續好幾個小時的重複訓練可以縮短至幾分鐘。
另外,在寫程式碼的過程中,發現restored_saver.restore()這個函式的作用是載入之前儲存模型的各Variable,而Graph需要自己重新畫,這個函式的好處是,可以只加載你想要的Variable,不想要的可以丟掉,例如本文中,需要捨棄Softmax層的w 和b,可以這樣寫:
not_restore = ['softmax_w:0', 'softmax_b:0'] restore_var = [v for v in tf.global_variables() if v.name.split('/')[-1] not in not_restore] restored_saver = tf.train.Saver(restore_var) ckpt = tf.train.get_checkpoint_state(checkpoint_dir) if ckpt and ckpt.model_checkpoint_path: print('restore model: '.format(ckpt.model_checkpoint_path)) restored_saver.restore(session, ckpt.model_checkpoint_path)
如果不希望重複定義圖上的運算,也可以使用tf.train.import_meta_graph()直接載入已經持久化的圖,之前那篇部落格在呼叫訓練好的模型進行分類時,就是這麼做的:
saver = tf.train.import_meta_graph("{}.meta".format(checkpoint_file))
saver.restore(self.session, checkpoint_file)這個函式會把整個Graph連同裡面的各個量一股腦載入進來,這樣就導致不能對模型進行微調(fine tuning),就連batch size也是不能改,考慮到這一點,那時候我在訓練的時候驗證集對應的model只能設成1了。
對比感覺還是用restored_saver.restore()更方便、靈活一點,也不容易出錯。
相關推薦
基於LSTM和遷移學習的文字分類模型說明(Tensorflow)
考慮到在實際應用場景中,資料有可能後續增加,另外,類別也有可能重新分配,比如銀行業務中的[取款兩萬以下]和[取款兩萬以上]後續可能合併為一類[取款],而重新訓練模型會浪費大量時間,因此我們考慮使用遷移學習來縮短訓練時間。即保留LSTM層的各權值變數,然後重新構建全連線層,
基於RNN的文字分類模型(Tensorflow)
基於LSTM(Long-Short Term Memory,長短時記憶人工神經網路,RNN的一種)搭建一個文字意圖分類的深度學習模型(基於Python3和Tensorflow1.2),其結構圖如下: 如圖1所示,整個模型包括兩部分 第一部分:句子特徵提取 Step1 讀
文字處理——基於 word2vec 和 CNN 的文字分類 :綜述 & 實踐(一)
導語傳統的向量空間模型(VSM)假設特徵項之間相互獨立,這與實際情況是不相符的,為了解決這個問題,可以採用文字的分散式表示方式(例如 word embedding形式),通過文字的分散式表示,把文字表示成類似影象和語音的連續、稠密的資料。這樣我們就可以把深度學習方法遷移到文字
基於深度學習和遷移學習的遙感影象場景分類實踐(AlexNet、ResNet)
卷積神經網路(CNN)在影象處理方面有很多出色的表現,在ImageNet上有很多成功的模型都是基於CNN的。AlexNet是具有歷史意義的一個網路,2012年提出來當年獲得了當年的ImageNet LSVRC比賽的冠軍,此後ImageNet LSVRC的冠軍都是都是用CNN做的,並且層
基於Tensorflow的LSTM-CNN文字分類模型
題記 前段時間再看QA方面的文章,讀了一篇paper(《LSTM-based deep learning model for non-factoid answer selection》)中,使用了LSTM-CNN模型來做answer與question的語義抽取。受此啟發
【NLP】語言模型和遷移學習
10.13 Update:最近新出了一個state-of-the-art預訓練模型,傳送門: 李入魔:【NLP】Google BERT詳解 zhuanlan.zhihu.com 1. 簡介 長期以來,詞向量一直是NLP任務中的主要表徵技術。隨著2017年底以及2018年初的一系列技術突破,研究證實
從零開始的文字TF-IDF向量構造和基於餘弦相似度的文字分類
一、任務需求 1、給定資料庫裡面的N行資料每行代表一篇文章,屬性分別是[id, title, summuary,content] ,從mysql資料庫獲取資料並生成DataFrame格式的資料,有兩列,分別是id 和con
一種基於CNN的自動化提取n-gram feanture的文字分類模型
今天寫的部落格主要參考了清華大學黃民烈老師團隊2018年在IJCAI上發表的paper《Densely Connected CNN with Multi-scale Feature Attention for Text Classification》。 這篇p
基於 迴圈神經網路 (LSTM) 的情感評論文字分類
基於迴圈神經網路 (LSTM) 的情感評論文字分類 一、簡介 眾所周知,區分使用者發帖或者評論文字的情感分類問題,對商家來說是很重要的,不僅可以及時瞭解到使用者的情緒,而且可以幫助商家進行產品迭代。例如,“汽車之家” 網站上的使用者評論,進過
乾貨 | 基於貝葉斯推斷的分類模型& 機器學習你會遇到的“坑”
本文轉載自公眾號“讀芯術”(ID:AI_Discovery)本文3153字,建議閱讀8分鐘。本文
量價線性模型假設-基於Adaboost和線性迴歸弱分類器
前兩篇的文章中我演示瞭如何進行預測,但是預測的準確率一直停留在50%上下,好一點的有60%,IR就不用說了,有多有少,可操作性比較差。今天從另一個角度解釋一下為什麼這麼難預測。先從一個有趣的題目來入手:任意開啟一張圖表,將價格走勢圖刪掉一部分,但是不要刪成交量的走
使用Keras和預訓練的詞向量訓練新聞文字分類模型
from __future__ import print_function import os import sys import numpy as np from keras.preprocessing.text import Tokenizer from keras.p
深度學習之文字分類模型-前饋神經網路(Feed-Forward Neural Networks)
目錄DAN(Deep Average Network)Fasttextfasttext文字分類fasttext的n-gram模型Doc2vec DAN(Deep Average Network) MLP(Multi-Layer Perceptrons)叫做多層感知機,即由多層網路簡單堆疊而成,進而我們可以在輸
inceptionv3 /v4遷移學習影象分類
研究一個影象分類的任務,現在的問題是對6類影象資料做分類任務,資料的特徵是每一類都只有非常少的資料,並且存在類別不平均,在這種情況下我們的實驗結果存在準確率的問題,對於少量資料,採用端到端從頭開始訓練的方法,模型學習到的特徵很少,泛化能力不夠,採用從ImageNet資料集訓練得到的結果,我們可以採用
機器視覺 OpenCV—python 基於LSTM網路的OCR文字檢測與識別
一、背景與環境搭建 OpenCV的文字識別流程: OpenCV EAST 文字檢測器執行文字檢測, 我們提取出每個文字 ROI 並將其輸入 Tesseract,從而構建完整的 OpenCV OCR 流程! 環境搭建 Tesseract (v4) 最新版本
北大人工智慧網課攻略[4]:基於VGG16的遷移學習
個人程式如下: 連結: https://pan.baidu.com/s/1mi99CsgRvolkXUb-UoW3Gw 提取碼: kyrp 北大人工智慧網課考試二是訓練VGG16模型,並對老師給出的10張圖片進行識別。如果使用老師給出的已經訓練好的VGG16模型引數和呼叫程式
tensorflow遷移學習-使用現有模型進行新專案訓練
怎麼在新的專案上使用已訓練過的模型,以識別花種類為例現代的識別模型動轍有百萬的引數,從頭開始訓練需要許多標記過的訓練資料及訓練時間,遷移學習可以很方便的複用已經訓練過的模型應用到新的場景上,以一個在ImageNet上訓練過的圖片分類模型為例,雖然不如重新訓練一個模型精度好,但是對於幾千而不是上百萬的已打標籤的
幾種使用了CNN(卷積神經網路)的文字分類模型
下面就列舉了幾篇運用CNN進行文字分類的論文作為總結。 1 yoon kim 的《Convolutional Neural Networks for Sentence Classification》。(2014 Emnlp會議) 他用的結構比較簡單,就是使用長度不同的 filter 對文字矩陣進行
基於Python的機器學習之分類學習
所有的資料集都可以從sklearn.datasets中獲得 在評估時,一般使用F1指標,即使用了調和平均數,除了具備平均功能,還會對那些召回率和精血率更加接近的模型給予更高的分數。 分類學習 線性分類器(Linear Classifiers) 線性分類器通過累加計算每
TensorFlow從入門到放棄(二)——基於InceptionV3的遷移學習以及影象特徵的提取
1. flower資料集 共五種花的圖片 2. 圖片處理 將圖片劃分為train、val、test三個子集並提取圖片特徵。這個過程有點兒漫長請耐心等待。。。。。。 import glob import os.path import numpy as np im