
簡易理解RNN與LSTM
總說
這篇主要是如何一步步說明RNN和LSTM的形式的構造,方便對模型有一個更直觀的理解。寫的比較隨意。
RNN
我們知道,卷積是一個輸入,得到一個輸出。但有時候我們想輸出一串,然後得到一串輸出呢?並且是這一串都是相互有關聯的,比如句子翻譯。我們就需要一種能針對歷史資訊進行融合的單元,比如RNN。其實想想,只要以某種形式,將歷史資訊與當前輸入進行有效融合的方式,應該都可以處理類似的問題。
和CNN的區別是,RNN有一個隱層狀態
比如第一次,我們先設定一個
我們通過增加了一個隱層狀態,從而使得RNN能夠將當前輸入與歷史輸入進行有效的融合。隱層狀態是歷史資訊的載體。
對於每次新的輸入
RNN還要有輸出,既然是迭代的,顯然對於第
所以自然就有下面:
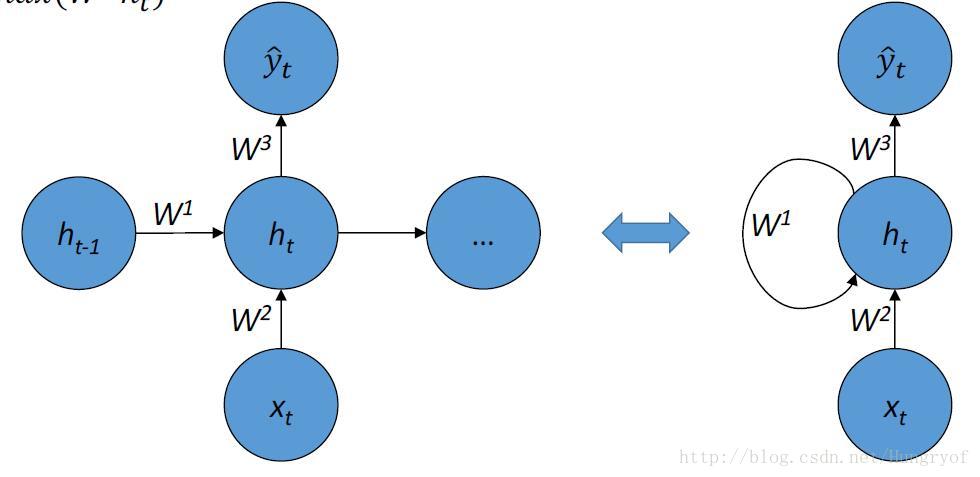
值得注意的是,這幅圖左邊是展開形式。那麼要定義給一個RNN,我們當然要定義這個
看看pytorch的對應函式,emmm,沒啥問題。預設的隱層啟用函式是tanh, 也可以選擇 relu.

num_layers是什麼?
是RNN有多少層,前面看到的都是一層的RNN。比如很經典的預測下一個字母:
輸入是one-hot形式的4*1向量,紅色層是輸入層。隱層淺綠色,狀態是3*1。因此
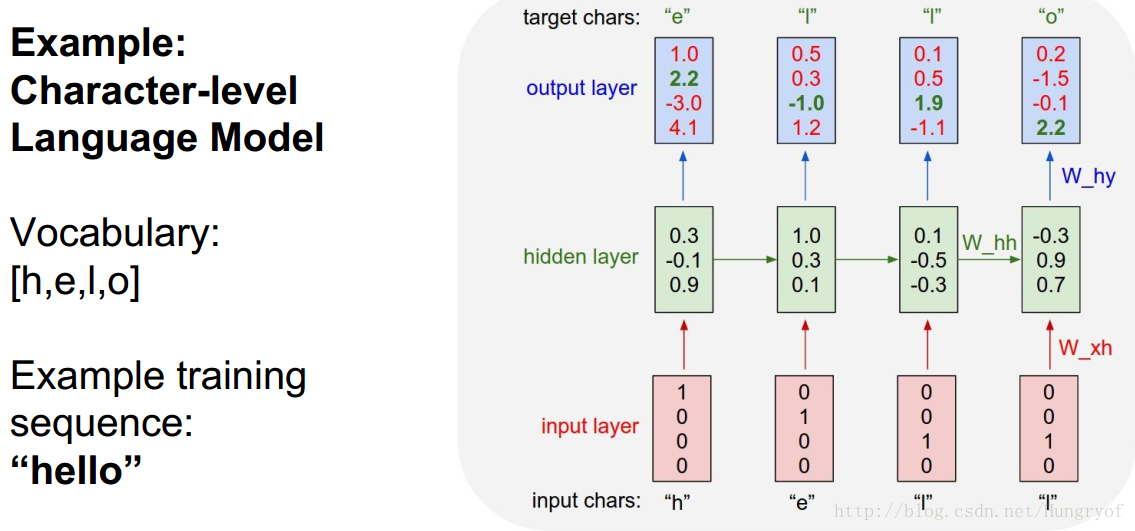
前面的例子都是,輸入經過經過一次線性變換,成為隱層狀態,再經過一次線性變換,直接變成輸出了。為了增加複雜性,可以讓隱層狀態經過多次線性變換,再到輸出。這就是多層RNN!
下面是3層的(綠色代表深度為3的隱層,紅色是輸入層,藍色是輸出層)
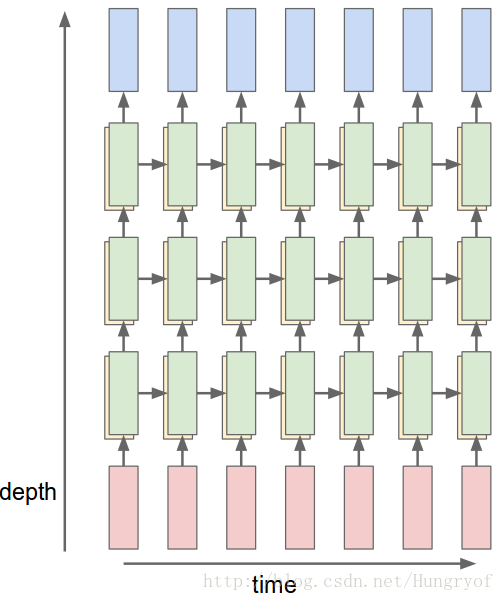
BPTT
反向傳播的梯度推導如下,看看就行。



顯然容易出現梯度爆炸或者梯度消失的現象。對於梯度爆炸,直接梯度裁剪就行。但是梯度消失,就不好弄了,你不可能直接乘以一個數吧~~。
如何解決RNN的梯度消失問題
看看原來咋弄的:
原來的當前隱層狀態的得到,是直接將當前輸入和上一次迭代的隱層狀態,進行簡單融合。那麼求導時,自然就會有連乘形式,那就容易爆炸或是消失啊!要不轉換成“連加”吧。
現在是,上一次迭代的隱層狀態和當前的輸入,融合後的