
RNN與反向傳播演算法(BPTT)的理解
RNN是序列建模的強大工具。
今天主要搬運兩天來看到的關於RNN的很好的文章:
PS: 第一個連結中的Toy Code做一些說明
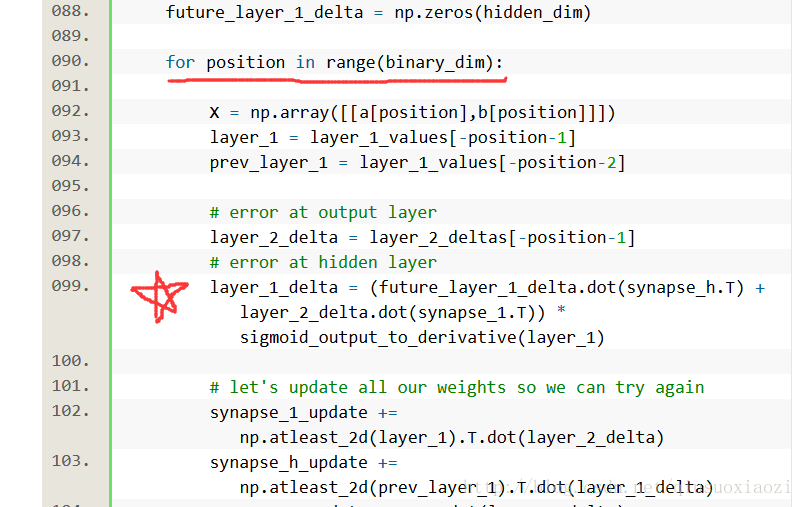
之所以要迴圈8(binary_dim=8)次,是因為輸入是2維的(a和b各輸入一個bit),那麼,每個bit只會影響8個時間戳。因此要注意RNN的訓練,應該以每一個完整的序列(這裡就是a和b兩個八位二進位制數)作為一個training sample,而非以每一次輸入(2 bits)作為一個sample;同樣的在反向傳播時,也同樣遵循這個原則,此處因為每次輸入會影響8個時間戳(或者說每8次輸入為一個完整的training sample),所以要迴圈8次。
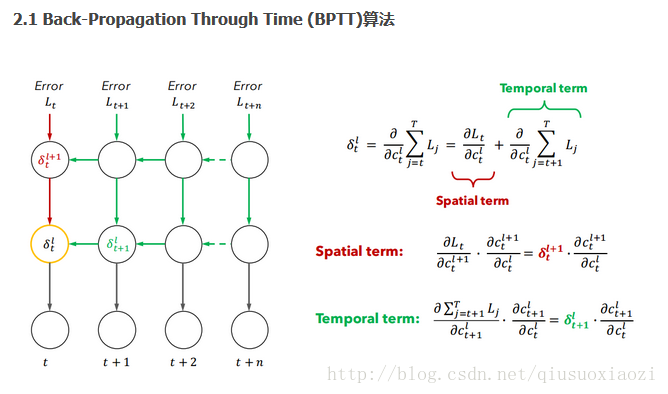
再然後,第99行(五角星處)的隱層delta更新法則與上面給出的RNN反向傳播演算法BPTT一文中的下圖正好一致!
先寫這麼多。
相關推薦
RNN與反向傳播演算法(BPTT)的理解
RNN是序列建模的強大工具。 今天主要搬運兩天來看到的關於RNN的很好的文章: PS: 第一個連結中的Toy Code做一些說明 之所以要迴圈8(binary_dim=8)次,是因為輸入是2維的(a和b各輸入一個bit),那麼,每個bit只會影響8
全連線神經網路的反向傳播演算法(BP)
一、預熱篇 參考連結:http://colah.github.io/posts/2015-08-Backprop/ 要理解的主要點:路徑上所有邊相乘,所有路徑相加 反向傳播演算法(Backpropagation)已經是神經網路模型進行學習的標配。但是有很多問題值得思考一下: 反向傳播
神經網路中反向傳播演算法(BP)
神經網路中反向傳播演算法(BP) 本文只是對BP演算法中的一些內容進行一些解釋,所以並不是嚴格的推導,因為我在推導的過程中遇見很多東西,當時不知道為什麼要這樣,所以本文只是對BP演算法中一些東西做點自己的合理性解釋,也便於自己理解。 要想看懂本文,要懂什麼是神經網路,對前向傳播以
對反向傳播演算法(Back-Propagation)的推導與一點理解
最近在對卷積神經網路(CNN)進行學習的過程中,發現自己之前對反向傳播演算法的理解不夠透徹,所以今天專門寫篇部落格記錄一下反向傳播演算法的推導過程,算是一份備忘錄吧,有需要的朋友也可以看一下這篇文章,寫的挺不錯的:http://www.cnblogs.com/lancel
梯度下降演算法原理與反向傳播思想(推導及核心觀點)
梯度下降方法是常用的引數優化方法,經常被用在神經網路中的引數更新過程中。 神經網路中,將樣本中的輸入X和輸出Y當做已知值(對於一個樣本[X,Y],其中X和Y分別是標準的輸入值和輸出值,X輸入到模型中計算得到Y,但是模型中的引數值我們並不知道,所以我們的做法是隨機初始化模型的
反向傳播演算法(BP演算法)
BP演算法(即反向傳播演算法),適合於多層神經元網路的一種學習演算法,它建立在梯度下降法的基礎上。BP網路的輸入輸出關係實質上是一種對映關係:一個n輸入m輸出的BP神經網路所完成的功能是從n維歐氏空間向m維歐氏空間中一有限域的連續對映,這一對映具有高度非線性。它的資訊處理能力來源於簡單非線性函式的多
反向傳播演算法(過程及公式推導)
反向傳播演算法(Backpropagation)是目前用來訓練人工神經網路(Artificial Neural Network,ANN)的最常用且最有效的演算法。其主要思想是: (1)將訓練集資料輸入到ANN的輸入層,經過隱藏層,最後達到輸出層並輸出結果,這是ANN的前向傳
C++實現誤差反向傳播演算法(BP神經網路)
誤差反向傳播學習演算法 實現Iris資料分類 Denverg Secret Number 29,April 2018 實驗目的 用C++實現BP神經網路 實驗原理 人工神經網路模型 人們從40年代開始研究人腦神經元功能。1943年
機器學習sklearn19.0——整合學習——boosting與梯度提升演算法(GBDT)、Adaboost演算法
一、boosting演算法原理 二、梯度提升演算法 關於提升梯度演算法的詳細介紹,參照部落格:http://www.cnblogs.com/pinard/p/6140514.html 對該演算法的sklearn的類庫介紹和調參,參照網址:http://
[2] TensorFlow 向前傳播演算法(forward-propagation)與反向傳播演算法(back-propagation)
TensorFlow Playground http://playground.tensorflow.org 幫助更好的理解,遊樂場Playground可以實現視覺化訓練過程的工具 TensorFlow Playground的左側提供了不同的資料集來測試神經網路。預設的資料為左上角被框出來的那個。被
標籤傳播演算法(LPA)Python實現
標籤傳播演算法(LPA)的做法比較簡單: 第一步:為所有節點指定一個唯一的標籤; 第二步:逐輪重新整理所有節點的標籤,直到達到收斂要求為止。對於每一輪重新整理,節點標籤重新整理的規則如下:
吳恩達機器學習(第十章)---神經網路的反向傳播演算法
一、簡介 我們在執行梯度下降的時候,需要求得J(θ)的導數,反向傳播演算法就是求該導數的方法。正向傳播,是從輸入層從左向右傳播至輸出層;反向傳播就是從輸出層,算出誤差從右向左逐層計算誤差,注意:第一層不計算,因為第一層是輸入層,沒有誤差。 二、如何計算 設為第l層,第j個的誤差。
(轉載)深度學習基礎(3)——神經網路和反向傳播演算法
原文地址:https://www.zybuluo.com/hanbingtao/note/476663 轉載在此的目的是自己做個筆記,日後好複習,如侵權請聯絡我!! 在上一篇文章中,我們已經掌握了機器學習的基本套路,對模型、目標函式、優化演算法這些概念有了一定程度的理解,而且已經會訓練單個的感知器或者
深度學習 --- BP演算法詳解(誤差反向傳播演算法)
本節開始深度學習的第一個演算法BP演算法,本打算第一個演算法為單層感知器,但是感覺太簡單了,不懂得找本書看看就會了,這裡簡要的介紹一下單層感知器: 圖中可以看到,單層感知器很簡單,其實本質上他就是線性分類器,和機器學習中的多元線性迴歸的表示式差不多,因此它具有多元線性迴歸的優點和缺點。
BP神經網路反向傳播演算法一步一步例項推導(Backpropagation Example)
1. loss 函式的優化 籠統來講: 設計loss函式是為了衡量網路輸出值和理想值之間的差距,儘管網路的直接輸出並不顯式的包含權重因子,但是輸出是同權重因子直接相關的,因此仍然可以將loss函式視作在權重因子空間中的一個函式。 可以將loss 記為E(w),這裡為
DNN網路(二)反向傳播演算法
本文摘自: https://www.cnblogs.com/pinard/p/6422831.html http://www.cnblogs.com/charlotte77/p/5629865.html 一、DNN求解引數的方法 在監督學習中,優化引數的方法 首
迴圈神經網路(RNN)模型與前向反向傳播演算法
在前面我們講到了DNN,以及DNN的特例CNN的模型和前向反向傳播演算法,這些演算法都是前向反饋的,模型的輸出和模型本身沒有關聯關係。今天我們就討論另一類輸出和模型間有反饋的神經網路:迴圈神經網路(Recurrent Neural Networks ,以下簡稱RNN),它廣泛的用於自然語言處理中的語音
深度學習基礎2(反向傳播演算法)
我們先是用鏈式法則解釋。比如如下的神經網路 前向傳播對於節點來說,的淨輸入如下: 接著對做一個sigmoid函式得到節點的輸出: 類似的,我們能得到節點、、的輸出、、。 誤差得到結果後,整個神經網路的輸出誤差可以表示為: 其中就是剛剛通過前向傳播算出來的、;是節點、的目標值。用來衡量二者的誤差。 這個
深度神經網路(DNN)反向傳播演算法(BP)
在深度神經網路(DNN)模型與前向傳播演算法中,我們對DNN的模型和前向傳播演算法做了總結,這裡我們更進一步,對DNN的反向傳播演算法(Back Propagation,BP)做一個總結。 1. DNN反向傳播演算法要解決的問題 在瞭解DNN的反向傳播演算法前,我們先要知道DNN反向傳播演算法
深度學習(一)--反向傳播演算法
本文從李飛飛的課件cs231n的得到啟發,將關於反向傳播演算法的內容做下總結。 下圖是對深度學習的直觀解釋: 該圖右側表示影象空間,通過幾個分介面將影象空間分成幾個不同的區域,每個區域的影象具有相似的特徵。 左側為卷積神經網路的簡單版,將輸入影