
Spark-SQL的安裝及使用
安裝步驟
下載編譯了Hive的Spark版本
官網下載連結給出的都是編譯過Hive的(至少1.6版可以確定是)。CDH自帶的Spark都是沒有帶Hive的,若直接執行./spark-sql,會報錯如下Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.hive.cli.CliDriver at java.net.URLClassLoader$1.run(URLClassLoader.java:366) at java.net.URLClassLoader$1.run(URLClassLoader.java:355) at java.security.AccessController.doPrivileged(Native Method) at java.net.URLClassLoader.findClass(URLClassLoader.java:354) at java.lang.ClassLoader.loadClass(ClassLoader.java:425) at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308) at java.lang.ClassLoader.loadClass(ClassLoader.java:358) ... 18 more也可以手動編譯帶Hive的Spark,見參考博文1,2。
- 測試
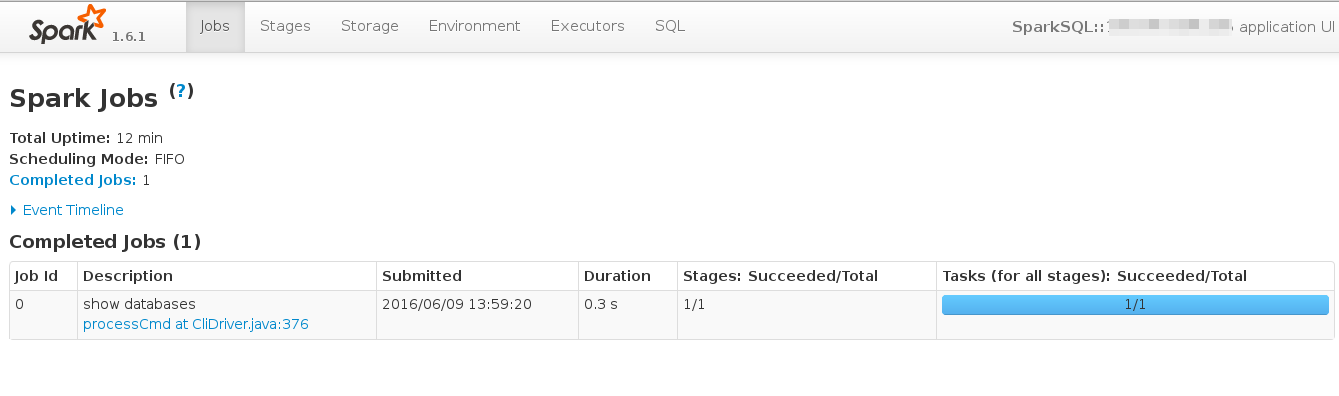
執行./spark-sql後,可以在http://your-host:4040/jobs/介面檢視該Spark作業。
在命令列輸入show databases;,給出結果default。同時,可以在介面檢視到執行該語句的job,見下圖,
若執行其它語句時報錯,應當是Spark與Hive版本不相容造成的,見下一小結的解決方案處理。 配置Hive資料來源
在Spark安裝目錄下的conf檔案中,新建檔案hive-site.xml,並新增如下內容,以使Spark使用Hive的資料來源(上述步驟2使用的應該是自帶Hive的資料來源)<?xml version="1.0" encoding="UTF-8"?> <!--Autogenerated by Cloudera Manager--> <configuration> <property> <name>hive.metastore.uris</name> <value>thrift://Hive-Metastore-Server:9083</value> </property> </configuration>之後重新執行spark-sql,在命令列輸入
show databases;,給出結果default lykdata。
問題–Hive版本不相容的問題
1.下載沒有hadoop的版本。
比如spark-1.5.2-bin-without-hadoop.tgz。
2.複製CDH中關於Spark 的 conf
採用如下方式獲取Spark的配置,Hadoop的配置獲取方式也類似。
[[email protected] spark-1.3.0-bin-hadoop2.4]# ll /etc/spark/conf
lrwxrwxrwx. 1 root root 28 3月 18 用最後獲取到的配置檔案替換掉Spark目錄下的conf。
3.修改conf/spark-env.sh
export SPARK_HOME=.
4.修改conf/spark-defaults.conf
上傳Spark自帶的lib/spark-assembly-1.6.0-hadoop2.2.0.jar
到/user/asin/spark-assembly-1.6.0-hadoop2.2.0.jar,之後修改conf/spark-defaults.conf,
spark.yarn.jar=hdfs:///user/asin/spark-assembly-1.6.0-hadoop2.2.0.jar
參考
相關推薦
Spark本地安裝及Linux下偽分散式搭建
title: Spark本地安裝及Linux下偽分散式搭建 date: 2018-12-01 12:34:35 tags: Spark categories: 大資料 toc: true 個人github部落格:Josonlee’s Blog 文章目錄
Spark SQL簡介及以程式設計方式實現SQL查詢
1.什麼是SparkSQL? Spark SQL是Spark用來處理結構化資料的一個模組,它提供了一個程式設計抽象叫做DataFrame並且作為分散式SQL查詢引擎的作用。 2.SparkSQL的特點: 我們已經學習了Hive,它是將Hive SQL轉換成M
Spark叢集安裝及Streaming除錯
安裝前置條件 1. 系統需要安裝the Oracle Java Development Kit(not OpenJDK),安裝jdk1.7以上,下載目錄:http://www.oracle.com/technetwork/java/javase/downlo
hive on spark的安裝及問題
配置hive hive-site <property> <name>hive.metastore.uris</name> <value>thrift://database:9083</value>
Spark-SQL的安裝及使用
安裝步驟 下載編譯了Hive的Spark版本 官網下載連結給出的都是編譯過Hive的(至少1.6版可以確定是)。CDH自帶的Spark都是沒有帶Hive的,若直接執行./spark-sql,會報錯如下 Caused by: java.lang.C
SQL server數據庫的在server 2008R2上的安裝及基本管理
server 數據庫 SQL server數據庫的在server 2008R2上的安裝及基本管理(一)選擇SQL的數據庫的鏡像文件雙擊setup.ext 執行安裝程序這裏選擇安裝項,並選擇全新安裝安裝的環境監測全部通過因為這裏是使用的破解版的鏡像,所以會自動生成密鑰再一次檢測安裝環境
win10安裝及卸載SQL Server2008數據庫
color 規則 report 窗體 連接 wid 客戶 無法 正常 一.數據庫安裝環境 操作系統:win10 SQL server:SQL server 2008 R2二.全新數據庫安裝1.安裝擴展文件 雙擊安裝文件,彈出如下窗
大數據筆記(二十七)——Spark Core簡介及安裝配置
sin cli sca follow com clu 同時 graphx 信息 1、Spark Core: 類似MapReduce 核心:RDD 2、Spark SQL: 類似Hive,支持SQL 3、Spark Streaming:類似
PL SQL 12.0.7的安裝及註冊碼,漢化包,連接Oracle遠程數據庫,中文亂碼問題處理
目錄結構 百度雲盤 des 遠程 .html nload key 選擇 計算機 首先,在官網下載PL SQL 的對應版本,本機是64位的就下載64位的,網址:https://www.allroundautomations.com/downloads.html#PLS 點擊應
Shell 實現Docker MySQL5.7安裝及SQL指令碼執行
Linux Shell 實現Docker MySQL安裝及指令碼執行的目標: 1、實現MySQL5.7安裝 2、安裝完成後建立對應的賬號和資料庫例項表等 建立docker mysql容器例項 定義docker_mysql_install.sh #! /bin/bash #fi
大資料篇:Spark安裝及測試PI的值
本文執行的具體環境如下: centos7.3 Hadoop 2.8.4 Java JDK 1.8 Spark 1.6.3 一、安裝Hadoop 關於Hadoop的安裝,這裡就不概述了! 二、安裝 Spark 下載網址http://archive.apa
SQL Server大容量複製實用工具bcp下載安裝及使用
1.下載安裝 1,1下載 SQL Server2008點選這裡,SQL Server2016點選這裡 選中如圖兩項下載(請自行選擇64位或32位)。 1.2安裝 先安裝sqlncli.msi,後安裝SqlCmdLnUtils.msi。 1.3配環境變數 環境變數地址
Spark環境安裝部署及詞頻統計例項
Spark是一個高效能的分散式計算框架,由於是在記憶體中進行操作,效能比MapReduce要高出很多. 具體的我就不介紹了,直接開始安裝部署並進行例項測試 首先在官網下載http://spark.ap
SQL Server 2016 AlwaysOn 安裝及配置注意事項
參考部落格: 此部落格寫已經很詳細了,我只是為了記錄一下在實際操作過程中遇到的問題。 1.叢集管理配置 仲裁見證注意:這個路徑的許可權必須everyone角色具有讀寫許可權,否則叢集會出現以下錯誤提示,如果AlwasyOn的網路共享路徑也配置在域伺服器應該避免檔案見
oracle客戶端安裝及PL/SQL安裝
1.安裝oracle客戶端後,設定oracle環境變數: 新增3個環境變數: 變數名:ORACLE_HOME //客戶端安裝路徑 變數值:D:\Program Files\oracle 變數名:TNS
第76課:Spark SQL實戰使用者日誌的輸入匯入Hive及SQL計算PV實戰
內容: 1.Hive資料匯入操作 2.SparkSQL對資料操作實戰 一、Hive資料匯入操作 create table userLogs(date String,timestamp bigint,userI
Spark SQL的介紹和DataFrame的建立及使用
1. Spark SQL定位處理結構化資料的模組。SparkSQL提供相應的優化機制,並支援不同語言的開發API。 java、scala、Python,類SQL的方法呼叫(DSL) 2. RDD與Spark SQL的比較說明: 使用Spark SQL的優勢:a.面向結構化資料;b.優化
SQL安裝常見錯誤及解決辦法
錯誤1:安裝sql2008出現不是有效的安裝資料夾解決方法:找到安裝檔案所在的資料夾,然後點選裡面的“Setup.exe”進行安裝,便可以安裝了。之前提示安裝路徑的原因我在安裝時,點選的是開始選單欄裡的“安裝中心”進行安裝的,所以出現了提示資訊。錯誤2:sql server2
spark安裝及環境搭建
安裝 版本配套 Spark: 1.6.2 Scala: 2.12.1 軟體安裝 1、安裝JDK 手工配置JAVA_HOME環境變數,並將JDK的bin目錄加入Path環境變數中。 2、安裝Scala Windows版 通過.msi軟體包安裝。安裝完成後自動配置環境變數SC
sql server 安裝及 錯誤處理方法
此外,我從某位大神處得知,如果不安裝sql server 2008 management studio的話,在VS2010裡面也是可以視覺化地操作sql server 2008的,具體還有待考證,安不安自己選擇。 安裝過程中如果出現什麼本文沒有提到的異常,請照著程式提示操作,或者自行搜尋解決方案,Goo