
使用R完成決策樹分類
關於決策樹理論方面的介紹,李航的《統計機器學習》第五章有很好的講解。
傳統的ID3和C4.5一般用於分類問題,其中ID3使用資訊增益進行特徵選擇,即遞迴的選擇分類能力最強的特徵對資料進行分割,C4.5唯一不同的是使用資訊增益比進行特徵選擇。
特徵A對訓練資料D的資訊增益g(D, A) = 集合D的經驗熵H(D) - 特徵A給定情況下D的經驗條件熵H(D|A)
特徵A對訓練資料D的資訊增益比r(D, A) = g(D, A) / H(D)
而CART(分類與迴歸)模型既可以用於分類、也可以用於迴歸,對於迴歸樹(最小二乘迴歸樹生成演算法),需要尋找最優切分變數和最優切分點,對於分類樹(CART生成演算法),使用基尼指數選擇最優特徵。
參考自部落格,一個使用rpart完成決策樹分類的例子如下:
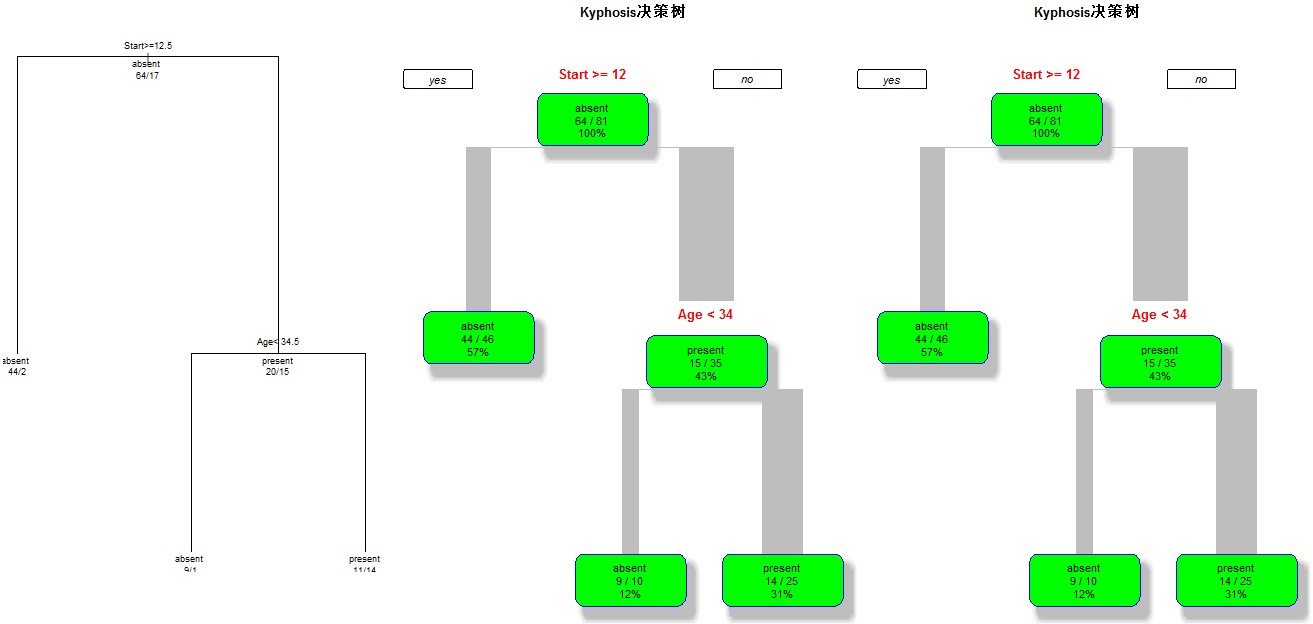
library(rpart); ## rpart.control對樹進行一些設定 ## xval是10折交叉驗證 ## minsplit是最小分支節點數,這裡指大於等於20,那麼該節點會繼續分劃下去,否則停止 ## minbucket:葉子節點最小樣本數 ## maxdepth:樹的深度 ## cp全稱為complexity parameter,指某個點的複雜度,對每一步拆分,模型的擬合優度必須提高的程度 ct <- rpart.control(xval=10, minsplit=20, cp=0.1) ## kyphosis是rpart這個包自帶的資料集 ## na.action:缺失資料的處理辦法,預設為刪除因變數缺失的觀測而保留自變數缺失的觀測。 ## method:樹的末端資料型別選擇相應的變數分割方法: ## 連續性method=“anova”,離散型method=“class”,計數型method=“poisson”,生存分析型method=“exp” ## parms用來設定三個引數:先驗概率、損失矩陣、分類純度的度量方法(gini和information) ## cost我覺得是損失矩陣,在剪枝的時候,葉子節點的加權誤差與父節點的誤差進行比較,考慮損失矩陣的時候,從將“減少-誤差”調整為“減少-損失” fit <- rpart(Kyphosis~Age + Number + Start, data=kyphosis, method="class",control=ct, parms = list(prior = c(0.65,0.35), split = "information")); ## 第一種 par(mfrow=c(1,3)); plot(fit); text(fit,use.n=T,all=T,cex=0.9); ## 第二種,這種會更漂亮一些 library(rpart.plot); rpart.plot(fit, branch=1, branch.type=2, type=1, extra=102, shadow.col="gray", box.col="green", border.col="blue", split.col="red", split.cex=1.2, main="Kyphosis決策樹"); ## rpart包提供了複雜度損失修剪的修剪方法,printcp會告訴分裂到每一層,cp是多少,平均相對誤差是多少 ## 交叉驗證的估計誤差(“xerror”列),以及標準誤差(“xstd”列),平均相對誤差=xerror±xstd printcp(fit); ## 通過上面的分析來確定cp的值 ## 我們可以用下面的辦法選擇具有最小xerror的cp的辦法: ## prune(fit, cp= fit$cptable[which.min(fit$cptable[,"xerror"]),"CP"]) fit2 <- prune(fit, cp=0.01); rpart.plot(fit2, branch=1, branch.type=2, type=1, extra=102, shadow.col="gray", box.col="green", border.col="blue", split.col="red", split.cex=1.2, main="Kyphosis決策樹");
效果圖如下:
相關推薦
使用R完成決策樹分類
關於決策樹理論方面的介紹,李航的《統計機器學習》第五章有很好的講解。 傳統的ID3和C4.5一般用於分類問題,其中ID3使用資訊增益進行特徵選擇,即遞迴的選擇分類能力最強的特徵對資料進行分割,C4.5唯一不同的是使用資訊增益比進行特徵選擇。 特徵A對訓練資料D的資訊增益g(
R語言學習(三)——決策樹分類
分類 分類(Classification)任務就是通過學習獲得一個目標函式(Target Function)f, 將每個屬性集x對映到一個預先定義好的類標號y。 分類任務的輸入資料是記錄的集合,每條記錄也稱為例項或者樣例。用元組(X,y)表示,其中,X 是屬性集合,y是一個特殊的
機器學習演算法(二)——決策樹分類演算法及R語言實現方法
決策樹演算法是分類演算法中最常用的演算法之一。決策樹是一種類似流程圖的樹形結構,可以處理高維資料,直觀易理解,且準確率較高,因此應用廣泛。本篇小博就決策樹的若干演算法:ID3演算法、C4.5演算法以及分類迴歸樹(CART)、C5.0進行對比介紹,並對比C4.5與C5.0處理
統計學習方法五 決策樹分類
回歸 element row tps 樣本 pan 類別 表示 splay 決策樹分類 1,概念 2,決策樹算法 2.1,特征選擇: 熵:值越大,不確定性因素越大;條件熵:條件對結果的影響不確定性;信息增益;信息增益比
機器學習之路: python 決策樹分類 預測泰坦尼克號乘客是否幸存
現象 info n) 指標 ssi 直觀 learn 保持 afr 使用python3 學習了決策樹分類器的api 涉及到 特征的提取,數據類型保留,分類類型抽取出來新的類型 需要網上下載數據集,我把他們下載到了本地, 可以到我的git下載代碼和數據集: https
R語言︱決策樹族——隨機森林演算法
筆者寄語:有一篇《有監督學習選擇深度學習還是隨機森林或支援向量機?》(作者Bio:SebastianRaschka)中提到,在日常機器學習工作或學習中,當我們遇到有監督學習相關問題時,不妨考慮下先用簡單的假設空間(簡單模型集合),例如線性模型邏輯迴歸。若效果不好,也即並沒達到你的預期或評判效果基
sklearn的快速使用之六(決策樹分類)
print(__doc__) import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClas
決策樹分類鳶尾花資料集
import numpy as np import pandas as pd import matplotlib as mpl import matplotlib.pyplot as plt from sklearn.tree import DecisionTreeClassifier iris_
sklearn學習筆記之決策樹分類和線性迴歸
decisoin tree: # -*- coding: utf-8 -*- import sklearn from sklearn import tree import matplotlib.pyplot as plt from sklearn.model_selection impor
R語言 決策樹及其實現
一顆決策樹包含一個根結點、若干個內部結點和若干個葉結點;葉結點對應於決策結果,其他每個結點則對應於一個屬性測試;每個結點包含的樣本集合根據屬性測試的結果被劃分到子結點中;根結點包含樣本全集。從根結點到葉結點的路徑對應於了一個判定測試序列。目的:為了產生一顆泛化能力強,即處理未
決策樹分類器演算法實現
# -*- coding: cp936 -*- #決策樹分類器 my_data=[['slashdot','USA','yes',18,'None'],['google','France','yes',23,'Premium'], ['digg','USA
R語言-決策樹-員工離職預測訓練賽
題目:員工離職預測訓練賽 網址:http://www.pkbigdata.com/common/cmpt/員工離職預測訓練賽_競賽資訊.html 要求: 資料主要包括影響員工離職的各種因素(工資、出差、工作環境滿意度、工作投入度、是否加班、是否升職、工資提升比例等)以及員工
R語言-決策樹-party包
1、首先解釋下熵和吉尼係數在決策樹的功用 決策樹學習的關鍵是如何選擇最優的劃分屬性。通常,隨著劃分過程的不斷進行,我們希望決策樹的內部分支節點所包含的樣本儘可能屬於同一類別,即節點的“純度”越來越高。
r語言決策樹
決策樹演算法 決策樹的建立 建立決策樹的問題可以用遞迴的形式表示: 1、首先選擇一個屬性放置在根節點,為每一個可能的屬性值產生一個分支:將樣本拆分為多個子集,一個子集對應一種屬性值; 2、在每一個分支上遞迴地重複這個過程,選出真正達到這個分支的例項; 3、如果在一個節點上的
R語言 決策樹
決策樹是以樹的形式表示選擇及其結果的圖。圖中的節點表示事件或選擇,並且圖的邊緣表示決策規則或條件。它主要用於使用R的機器學習和資料探勘應用程式。 決策樹的使用的例子是 - 預測電子郵件是垃圾郵件或非垃圾郵件,預測腫瘤癌變,或者基於這些因素預測貸款的信用風險。通
決策樹分類鳶尾花資料demo
code:import numpy as np import pandas as pd import matplotlib.pyplot as plt import matplotlib as mpl from sklearn import tree from sklearn
R語言-決策樹演算法(C4.5和CART)的實現
決策樹演算法的實現: 一、C4.5演算法的實現 a、需要的包:sampling、party library(sampling) library(party) sampling用於實現資料分層隨機抽樣,構造訓練集和測試集。 party用於實現決策樹演算法 另外,還可以設定隨
決策樹分類——matlab程式
%% 使用ID3決策樹演算法預測銷量高低 clc; clear ; %% 資料預處理 disp('正在進行資料預處理...'); [matrix,attributes_label,attributes] = id3_preprocess(); %% 構造ID3決策樹,其
影像資訊提取之——基於專家知識的決策樹分類
可以將多源資料用於影像分類當中,這就是專家知識的決策樹分類器,本專題以ENVI中Decision Tree為例來敘述這一分類器。 本專題包括以下內容: 專家知識分類器概述 知識(規則)定義 ENVI中Decision Tree的使用 概述 基於知識的決策樹分
R語言決策樹演算法
1,生成樹:rpart()函式raprt(formular,data,weight,subset,na.action=na.rpart,method,model=FALSE,x=FALSE,y=TRUE,parms,control,cost,...) fomula :模型格式形如outcom