
深度學習論文翻譯解析(十五):Densely Connected Convolutional Networks
論文標題:Densely Connected Convolutional Networks
論文作者:Gao Huang Zhuang Liu Laurens van der Maaten Kilian Q. Weinberger
論文地址:https://arxiv.org/pdf/1608.06993.pdf
DenseNet 的GitHub地址:https://github.com/liuzhuang13/DenseNet
參考的 DenseNet 翻譯部落格:https://zhuanlan.zhihu.com/p/31647627
宣告:小編翻譯論文僅為學習,如有侵權請聯絡小編刪除博文,謝謝!
小編是一個機器學習初學者,打算認真研究論文,但是英文水平有限,所以論文翻譯中用到了Google,並自己逐句檢查過,但還是會有顯得晦澀的地方,如有語法/專業名詞翻譯錯誤,還請見諒,並歡迎及時指出。
如果需要小編其他論文翻譯,請移步小編的GitHub地址
傳送門:請點選我
如果點選有誤:https://github.com/LeBron-Jian/DeepLearningNote
在計算機視覺領域,卷積神經網路(CNN)已經成為最主流的方法,比如AlexNet, VGGNet, Inception,ResNet等模型。CNN史上一個里程碑事件是ResNet模型的出現,ResNet可以訓練出更深的CNN模型,從而實現更高的準確度。ResNet模型的核心是通過建立前面層與後面層之間的“短路連線”(shortcuts , skip connection),這有助於訓練過程中梯度的反向傳播,從而能訓練出更深的CNN網路。今天我們要介紹的是DenseNet模型,它的基本思路與ResNet一致,但是它建立的是前面所有層與後面層的密集連線(dense connection),它的名稱也是由此而來。
眾所周知,在DenseNet之前,卷積神經網路提高效率的方向,要麼深(比如ResNet,解決了網路深時候的梯度消失問題),要麼寬(比如GoogLeNet的 Inception),而作者從Feature入手,通過對feature 的極致利用達到更好的效果和更少的引數。所以DenseNet的另一大特色是通過特徵在channel 上的連線來實現特徵複用(feature reuse)。這些特點讓DenseNet在引數和計算成本更少的情形下實現比 ResNet 更優的效能,DenseNet也因此斬獲CVPR 2017的最佳論文獎。本文學習其論文。
該文章提出的DenseNet核心思想在於建立了不同層之間的連線關係,充分利用了feature,進一步減輕了梯度消失問題,加深網路不是問題,而且訓練效果非常好。另外,利用bottleneck layer,Translation layer以及較小的growth rate使得網路變窄,引數減少,有效抑制了過擬合,同時計算量也減少了。DenseNet優點很多,而且在和ResNet的對比中優勢還是非常明顯的。


摘要
最近的研究表明,如果神經網路各層到輸入和輸出層採用更短的連線(shorter connections),那麼網路可以設計的更深,更準確且訓練起來更有效率。在這篇文章中,我們基於這個觀點,介紹了稠密卷積網路(DenseNet),該網路在前饋時將每一層與其他的任一層都進行了連線。傳統的 L 層卷積網路有 L 個連線——每一層與它的前一層和後一層相連——我們的網路有 L(L+1)/2 個連線。每一層都將之前的所有層的特徵圖作為輸入,而它自己的特徵圖是之後所有層的輸入。DenseNets 有一些很不錯的優點:有助於解決梯度消失(vanishing-gradient)問題,增強特徵 (feature)傳播,促進特徵的重複利用,大大減少了引數的數量。我們在四個目標檢測任務(CIFAR-10, CIFAR-100, SVHN和 ImageNet)中驗證了我們提出的結構。DenseNets 在這些資料集上大都有較大的提高,而且使用更少的計算量就可以獲得更好的效能。程式碼和預訓練模型如下:https://github.com/liuzhuang13/DenseNet。


1,引言
在視覺檢測任務中,卷積神經網路(CNNs)已經成為佔有絕對優勢的機器學習方法。儘管它們在20年前就已經被提出了,但是計算機硬體和網路結構的改善才使訓練深層的卷積網路在最近成為現實。起初的LeNet5有5層,VGG有19層,只有去年的Highway網路和ResNets網路才克服了100層網路的障礙。
隨著CNNs變得越來越深,一個新的問題出現了:當輸入或梯度資訊在經過很多層的傳遞之後,在到達網路的最後(或開始)可能會消失或者“被沖刷掉”(wash out)。很多最新的研究都說明了這個或者與這個相關的問題。ResNet網路和Highway網路將旁路資訊(bypass Signal)進行連線。隨機深度(stochastic depth)在訓練過程中隨機丟掉了一些層,進而縮短了ResNets網路,獲得了更好的資訊和梯度流。FractalNets 使用不同數量的卷積 block 來重複的連線一些平行層,獲得更深的網路同時還保留了網路中的 short paths。儘管這些方法在網路結構和訓練方法等方面有所不同,但他們都有一個關鍵點:他們都在前幾層和後幾層之間產生了短路徑(short paths)。

上圖為一個dense block的結構圖,在傳統的卷積神經網路中,如果你有 L 層,那麼就會有 L 個連線,但是在DenseNet中,會有 L(L+1)/2 個連線。簡單說,就是每一層的輸入來自前面所有層的輸出。就是說 x0 是 input,H1 的輸入是 x0(input),H2的輸入是 x0 和 x1 (x1 是 H1 的輸出)。

在這篇文章中,我們提出了一個結構,該結構是提煉上述觀點而形成的一種簡單的連線模式:為了保證能夠獲得網路層之間的最大資訊,我們將所有層(使用合適的特徵圖尺寸)都進行互相連線。為了能夠保證前饋的特性,每一層將之前所有層的輸入進行拼接,之後將輸出的特徵圖傳遞給之後的所有層。結構如圖1所示。重要的一點是,與ResNets不同的是,我們不是在特徵傳遞給某一層之前將其進行相加(combine),而是將其進行拼接(concatenate)。因此,第 l 層 有 l 個輸入,這些輸入是該層之前的所有卷積塊(block)的特徵圖,而它自己的特徵圖則傳遞給之後的所有 L-l 層。這就表示,一個 L 層的網路就有 L(L+1)/2 個連線,而不是像傳統的結構僅僅有 L 個連線,由於它的稠密連線模組,所以我們更喜歡將這個方法稱為稠密卷積網路(DenseNet)。

該稠密連線模組的一個優點是它比傳統的卷積網路有更少的引數,因為它不需要再重新學習多餘的特徵圖。傳統的前饋結構可以被看成一種層與層之間狀態傳遞的演算法。每一層接收前一層的狀態,然後將新的狀態傳遞給下一層。它改變了狀態,但也傳遞了需要保留的資訊。ResNets將這種資訊保留的更明顯,因為它加入了本身的變換(identity transformations)。最近很多關於ResNets的研究都表明ResNets的很多層是幾乎沒有起作用的,可以在訓練時隨機的丟掉。這篇論文【21】闡述了ResNets很像(展開的)迴圈神經網路,但是比起迴圈神經網路有更多的引數,因為它每一層都有自己的權重。我們提出的DenseNet結構,增加到網路中的資訊與保留的資訊有明顯的不同。DenseNet層很窄(例如每一層有12個濾波器),僅僅增加小數量的特徵圖到網路的“集體知識”(collective knowledge),並且保持這些特徵圖不變——最後的分類器基於網路中的所有特徵圖進行預測。


除了更好的引數利用率,DenseNet 還有一個優點是它改善了網路中資訊和梯度的傳遞,這就讓網路更容易訓練。每一層都可以直接利用損失函式的梯度以及最開始的輸入資訊,相當於是一種隱形的深度監督(implicit deep supervision)。這有助於訓練更深的網路。此外,我們還發現稠密連線有正則化的作用,在更少訓練集的任務中可以降低過擬合。
我們在四個目標檢測任務(CIFAR-10, CIFAR-100,SVHN和ImageNet)中驗證了DenseNet。在和現有模型有相似準確率的前提下,我們 的模型有更少的引數。此外,我們的網路還超過了目前在大部分的檢測任務都有最好結果的演算法。
 2,相關工作
2,相關工作
自從神經網路被提出之後,網路結構的探索就成為神經網路研究的一部分。最近神經網路的廣泛關注也給這個研究領域注入了新的生機。網路層數的增加也讓更多的人進行結構的改善,不同連線模式的探索,早期研究觀點的復現等方面的研究。
在 1980s 神經網論文中提出的級聯結構很像我們提出的稠密網路。他們之前的工作主要關注在全連線的多層感知機上。最近,使用批梯度下降訓練的全連線的級聯網路也被提出來了。儘管在小資料上有效,但該方法的網路卻有幾百個引數。【9, 23, 31, 41】提出在CNNs 中利用跨層連結獲得的多種特徵,這已經被證明在很多視覺任務上有效。和我們的工作類似,【1】使用和我們相似的跨層連結方式提出了一種純理論的網路架構。

Highway是這些網路中第一個提出使用 100 多層的結構訓練一個端到端的網路。使用旁路(bypassing paths)和門控單元(gating units),Highway 網路可以很輕鬆地優化上百層的網路。旁路被認為是使深層網路容易訓練關鍵因素。該觀點在ResNets中被進一步證實,ResNets使用本身的特徵圖作為旁路。ResNets在很多影象識別,定位和檢測任務(如ImageNet 和 COCO 目標檢測)中都獲得了不錯的效果,並且還打破了之前的記錄。最近,一種可以成功訓練 1202層ResNets的隨機深度(stochastic depth)被提出。隨機深度通過訓練過程中隨機丟掉一些層來優化深度殘差網路的訓練過程。這表明深度(殘差)網路中並不是所有的層都是必要的,有很多層是冗餘的。我們論文的一部分就受到了該論文的啟發。預啟用(pre-activation)的ResNets也有助於訓練超過 1000 層的網路。


一種讓網路更深(如跨層連線)的正交法(orthogonal approach)是增加網路的寬度。GooLeNet使用了“inception”模組,將不同尺度的濾波器產生的特徵進行組合連線。在【38】中,提出了一種具有廣泛寬度的殘差模組,它是ResNets的一種變形。事實上,只簡單的增加ResNets每一層的濾波器個數就可以提升網路的效能。FractalNets 使用一個寬的網路結構在一些資料集上也獲得了不錯的效果。
DenseNets 不是通過很深或者很寬的網路來獲得表徵能力,而是通過特徵的重複使用來利用網路的隱含資訊,獲得更容易訓練,引數效率更高的稠密模型。將不同層學到的特徵圖進行組合連線,增加了之後層輸入的多樣性,提升了效能。這同時也指出了 DenseNets和 ResNets 之間的主要差異。儘管 Inception 網路也組合連線了不同層的特徵,但DenseNets 更簡單,也更高效。
也有很多著名的網路結構獲得了不錯的結果。NIN 結構將多層感知機與卷積層的濾波器相連線來提取更復雜的特徵。在DSN中,通過輔助分類器來監督內部層,加強了前幾層的梯度。Ladder網路將橫向連線(lateral connection)引入到自編碼器中,在半監督學習任務中獲得不錯的效果。在【39】中,DFNs通過連線不同基礎網路的中間層來改善資訊的傳遞。帶有可以最小化重建損失路徑(pathways that minimize reconstruction losses)的網路也可以改善影象分類模型的效能。
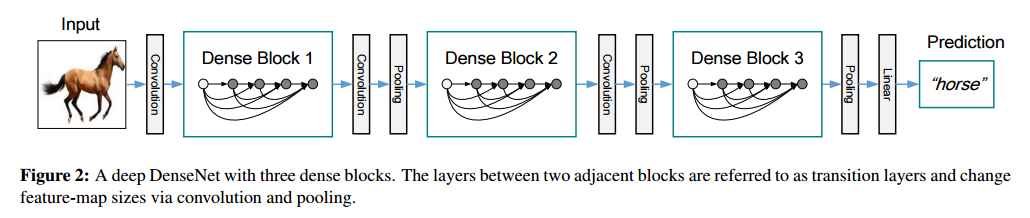
圖1表示的是 Dense block,而圖2 表示的則是一個 DenseNet的結構圖,在這個結構圖中包含了3個 dense block。作者將DenseNet 分為多個 dense block,原因是希望各個 dense block 內的 feature map 的 size 統一,這樣在做 concatenation 就不會有 size的問題。


3,DenseNets
假設一張圖片 x0 在卷積網路中傳播。網路共有 L 層,每一層都有一個非線性轉換 Ht(*),其中 l 表示層的維度(即第幾層)。 Ht(*) 是一個組合函式,有BN,ReLU,池化或者卷積。我們用 xt 表示 lth 層的輸出。
ResNets。傳統的前饋網路是將 lth 層的輸出作為 (l + 1)th 層的輸入,可用該方程來表示:xl = Hl(xt - 1)。ResNets增加了一個跨層連線,將自身與非線性轉換的結果相加:
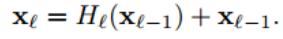
所以對ResNet而言,l 層的輸出是 l-1 層的輸出加上對 l-1 層輸出的非線性變換。
ResNets 的一個優點是可以直接將梯度從後層傳向前層。然而,自身與經過 Hl 得到的輸出是通過求和的形式來連線的。這可能使網路中資訊的傳播受到影響。

稠密連線(Dense connectivity)。為了更好的改善層與層之間資訊的傳遞,我們提出了一種不同的連線模式:將該層與之後的所有層進行連線,如圖1所示,因此,lth 層將與之前所有層的特徵圖 x0,...xl-1作為輸入:

其中 [x0, ...xl-1] 表示第 0, ... l-1層輸出的特徵圖的進行拼接。由於他的稠密連線模式,我們稱該網路結構為稠密卷積網路(DenseNet)。為了便於表達,我們將方程(2)中 Hl(*) 的多個輸入表示為一個向量。
組合函式(composite function)。受【12】的啟發,我們將 Hl(*) 定義為三種操作的組合函式,分別是BN,ReLU和3*3的卷積。

池化層(pooling layers)。當特徵圖的尺寸發生改變時,方程(2)中連線操作就會出現問題。然而,卷積網路有一個基礎的部分——下采樣層,它可以改變特徵圖的尺寸。為了便於下采樣的實現,我們將網路劃分為多個稠密連線的 dense block。如圖2所示。我們將每個 block 之間的層稱為過渡層,完成卷積核池化的操作。在我們的實驗中,過渡層由 BN層,1*1卷積層和2*2平均池化層組成。


增長速率(growth rate)。如果每個函式 Hl 都產生 k個特徵圖,之後的 lth 層就有 k0+k(l+1) 個特徵圖作為輸入,其中 k0 表示該層的通道數。DenseNet和現存網路結構的一個很重要的不同是,DenseNet的網路很窄,如 k=12.我們將超引數 k 稱為網路的增長速率。我們會在文章的第4部分進行說明,一個很小的增長速率在我們測試的資料集上就可以獲得不錯的效果。這種情況的一種解釋就是,每一層都可以和它所在的 block 中之前的所有特徵圖進行連線,使得網路具有了“集體知識”(collective knowledge)。可以將特徵圖看做是網路的全域性狀態。每一層相當於是對當前狀態 增加 k 個特徵圖。增長速率控制著每一層有多少資訊對全域性狀態有效。全域性狀態一旦被寫定,就可以在網路中的任何地方被呼叫,而不用像傳統的網路結構那樣層與層之間的不斷重複。

Bottleneck層。儘管每一層只產生 k 個輸出特徵圖,但它卻有更多的輸入,在【37, 11】中已經說明可以在 bottleneck 層中3*3的卷積之前加入 1*1 的卷積實現降維,可以減少計算量。我們發現這種設計對 DenseNet 極其有效,我們將具有 bottleneck 層,即 BN-ReLU-Conv (1*1)——BN-ReLU-Conv(3*3) 的結構稱為 DenseNet-B。在我們的實驗中,我們令 1*1 的卷積生成 4k 個特徵圖。

Compression(壓縮)。為了簡化模型,我們在過渡層中減少了特徵圖的數量。如果一個Dense block 有 m 個特徵圖,我們讓之後的過渡層生成 θm 個輸出特徵圖,其中 0 < θ <=1 表示Compression係數,當 θ=1 時,經過過渡層的特徵圖數量沒有改變。我們定義 θ<1 的DenseNet為DenseNet-C,並且在我們的實驗中 θ = 0.5。如果 bottleneck 和過渡層都有 θ < 1,我們稱該模型為 DenseNet-BC。

實現細節。在除了ImageNet外的所有資料集上,我們實驗中使用的 DenseNet都有3個dense block,每個 block 都要向他的層數。在進入第一個 dense block 之前,輸入影象先經過 16個(DenseNet-BC中是兩倍的增長速率)卷積。對於 3*3 的卷積層,使用一個畫素的零填充來保證特徵圖尺寸不變。在兩個 dense block 之間的過渡層中,我們在 2*2 的平均池化層之後增加了 1*1 的卷積。在最後一個 dense block 之後,使用全域性平均池化和softmax分類器。三個 dense block 的特徵圖的尺寸分別是 32*32, 16*16, 8*8 。我們改變一些引數 {L=40, k=12},{L=100, k=12},{L=100,k=24},在基本的 DenseNet上做了一些實驗。對於 DenseNet-BC,分別設定{L=100, k=12},{L=250, k=24},{L=190,k=40}。
對於在ImageNet資料集上的實驗,我們使用4個dense block的 DenseNet-BC結構,圖片的輸入是 224*224。最開始的卷積層有 2k(64)個卷積,卷積核是 7*7,步長是2;其餘所有層的特徵圖都設為 k。在ImageNet資料集上的網路如表1所示。
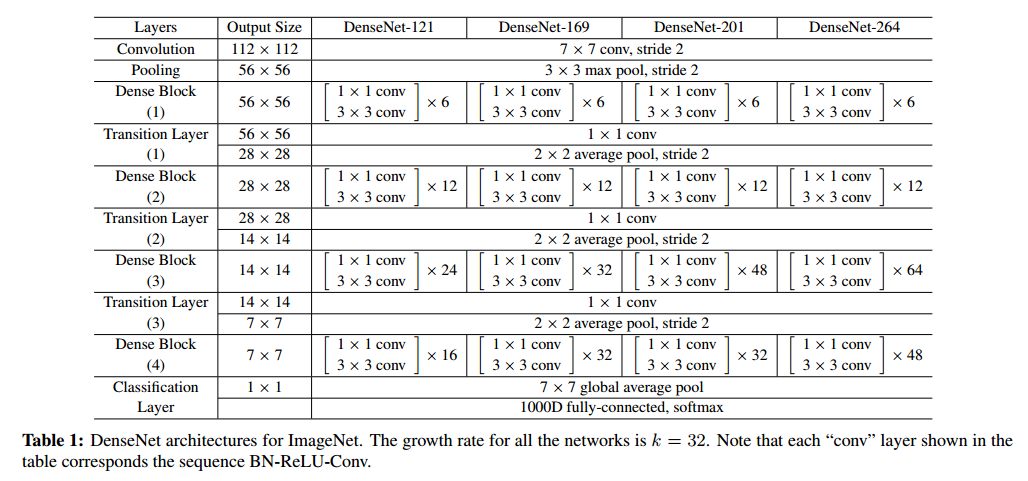
table1 就是整個網路的結構圖。這個表中的 k=32,k=48中的 k 是 growth rate,表示每個 dense block 中每層輸出的 feature map個數。為了避免網路變得很窄,作者都是採用較小的 K,比如32這樣的,作者的實驗也表明小的 k 可以有更好的效果。根據 dense block 的設計,後面幾層可以得到前面所有層的輸入,因此 concat後的輸入 channel 還是比較大的。另外這裡每個 dense block的 3*3 卷積前面都包含了一個 1*1 的卷積操作,就是所謂的 bottleneck layer,目的是減少輸入的 feature map 數量,既能降維減少計算量,又能融合各個通道的特徵。另外作者為了進一步壓縮引數,在每兩個 dense block 之間又增加了 1*1 的卷積操作。因此在後面的實驗對比中,如果看到DenseNet-C這個網路,表示增加了這個 Translation layer,該層的 1*1 卷積的輸出 channel 預設是輸入 channel 到一半。如果你看到 DenseNet-BC這個網路,表示既有 bottleneck layer,又有 Translation layer。

4,實驗
我們在一些檢測任務的資料集上證明 DenseNet的有效性,並且和現有的一些網路進行了對比,特別是ResNet和它的變形。
 4.1 資料集
4.1 資料集
CIFAR。兩種CIFAR資料集都是 32*32 的彩色圖,CIFAR-10(C10)是10類,CIFAR-100(C100)是100類。訓練集和測試集分別有 50000 和 10000 張圖片,我們從訓練集中選 5000 張作為驗證集。我們採用這兩個資料集上廣泛使用的資料增強方式(映象/平移)。用在資料集後的“+”來標色使用了這種資料增強方式(如C10+)。至於預處理,我麼使用每個顏色通道的均值和標準差來歸一化。最後,我們使用全部的 50000 張訓練圖片,在訓練結束時記錄測試誤差。
SVHN。SVHN資料集是 32*32的彩色數字圖。訓練集有 73257張圖片,測試集有 26032張,有 531131 張作為額外的訓練。在接下來實驗中,我們沒有使用任何的資料增強,從訓練集中選取 60000 張圖片作為驗證集。我們用驗證集誤差最小的模型來進行測試。我們對畫素值執行除 255 操作,歸一化到 【0, 1】。

ImageNet。ILSVRC 2012 分類資料集有 1.2百萬張訓練集,50000張驗證集,共 1000類。我們採用和論文【8, 11, 12】同樣的資料增強方式,在測試時使用 Single-crop 或 10-crop 將圖片尺寸變為 224*224。根據【11, 12, 13】,我們記錄了在驗證集上的分類誤差。
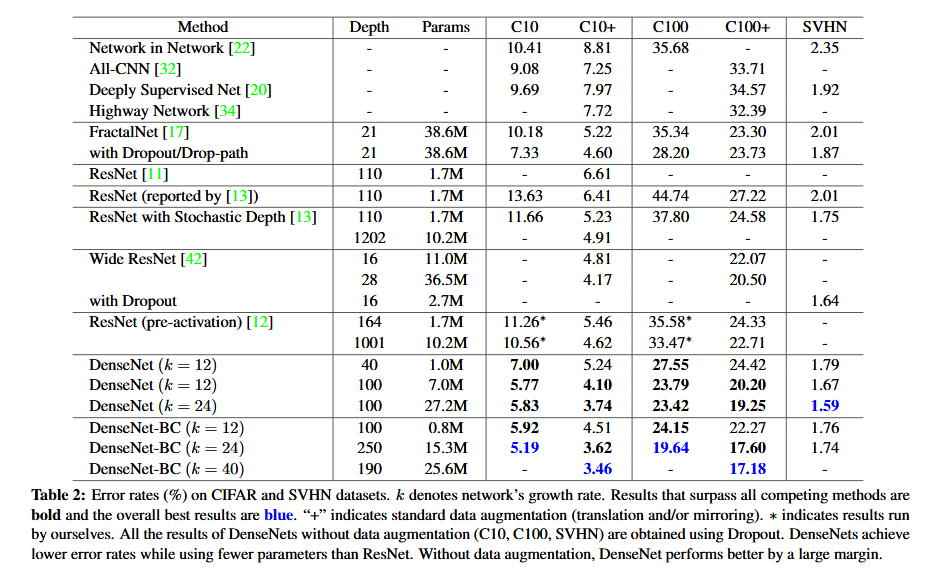
table 2 在三個資料集(C10, C100,SVHN)上和其他演算法的對比結果。ResNet【11】就是Kaiming He的論文,對比結果一目瞭然。DenseNet-BC的網路引數和相同深度的 DenseNet相比確實減少了很多!引數減少除了可以節省記憶體,還能減少過擬合。這裡對於SVHN 資料集,DenseNet-BC的結果並沒有 DenseNet(k=24)的效果好,作者認為原因主要是 SVHN 這個資料集相對簡單,更深的模型容易過擬合。在表格的倒數第二個區域的三個不同深度 L 和 k 的 DenseNet的對比可以看出隨著 L 和 K 的增加,模型的效果是更好的。


4.2 訓練
作者在不同資料集上取樣的 DenseNet 網路會有一點不一樣,比如在 Imagenet 資料集上,DenseNet-BC 有 4個 dense block,但是在別的資料集上只用3個 dense block。
所有的網路均使用隨機梯度下降法(SGD)進行訓練。在CIFAR和SVHN 資料上,我們令 batchsize = 64,分別訓練了 300輪和40輪。最初的學習率都為 0.1,分別在訓練總輪數的 50%和75%時,將學習率變為原來的 0.1倍。在ImageNet上,我們將模型訓練了90輪,batchsize=256。初始學習率設為 0.1,在第30輪和第 40 輪分別將學習率縮小 10倍。受 GPU記憶體的限制,我們設最大的模型(DenseNet-161) batchsize=128。為了彌補小 batch size 的不足,我們將模型訓練了 100 輪,並且在 90輪時將學習率除以 10。
根據【8】,我們設定梯度衰減值為 10e-4,Nesterov 動量設為 0.9。我們採用論文【10】中介紹的權重初始化方式。對於三種沒有使用資料增強的資料,如 C10, C100,SVHN,我們在每個卷積層(除了第一層)之後增加了一層 dropout層,並且設定失活率為 0.2。對於每個任務和每個模型都只進行一次測試。

4.3 在CIFAR 和 SVHN 上的分類結果
我們使用不同的深度(L),不同的增長速率(k),來分別訓練 DenseNets。在CIFAR 和 SVHN 上的結果如表2所示。為了突出結果,我們對其做了標記,將效能優於現存模型的結果加粗,將該資料集上的最好結果用藍色標記。
準確率(Accuracy)。可能最惹人注目的是表2最後一行的結果,其是 L=190, k=40 的 DenseNet-BC 網路在CIFAR 上的結果,效能已超過現存的所有模型。在C10+上錯誤率為 3.45%,在C100+上的錯誤率 為 17.18% 。在C100+上的誤差率遠遠低於寬ResNet(wide ResNet)網路。我們在C100和C100(無資料增強)上的誤差很喜人:比 FractalNets和使用dropout正則項的結果低了接近 30%。在SVHN上,L=100,k=24 的 DenseNet(使用dropout)也遠超寬ResNet 的最好結果。然而,250層的DenseNet-BC 的效能卻沒有提升太多。這可能是因為 SVHN的任務很簡單,複雜的模型往往會導致過擬合。
容量(Capacity)。不考慮 compression或bottleneck層, L和k越大,模型效能越好。我們把這歸功於模型容量的增加。這在C10+和C100+這兩列中得到了很好的證明。在C10+這列,誤差率從 5.24%降到了 4.10%,最後到了 3.74%。因為模型的引數量從1M增加到7M,最後到了 27.2M。在C100+這列,我們可以看到相似的結果。這表明DenseNet可以使用更大更深的模型來增加表徵能力,也表明他們沒有出現過擬合或者殘差網路的優化困難等問題。
引數效率。表2 的結果表明DenseNet比常見的網路(特別是ResNet)的引數效率更高。使用 bottleneck結構並且在過渡層使用降維操作的 DenseNet-BC的引數利用率極其高。例如,我們的 250層模型只有 15.3 M的引數量,但是它的效能卻遠超其他引數量超過 30M的模型,像 FractalNets和 寬 ResNet。我們也將L=100,k=12的 DenseNet-BC效能與 1001層 pre-activation的 ResNet進行了比較(如,在C10+的誤差 4.51%VS4.62%, 在C100+的誤差:22.27%VS22.71%)。這兩個網路在C10+資料上的訓練loss和測試誤差如圖4(右圖)。1001層的深度ResNet收斂到一個更低的loss,但卻有相似的測試誤差。我們會在接下來對這個內容進行更深入的探討。
 過擬合(Overfitting)。更高效的利用引數的一個作用是DenseNets不容易發生過擬合。在不使用資料增強的資料集上,我們發現到 DenseNet結構和之前的工作相比較,其改進還是很明顯的。在C10上,誤差降了 29%,從 7.33%降到了 5.19%。在C100上,降了大約 30%,從 28.2%降到了 19.64%。通過實驗,我們發現一個潛在的過擬合現象:在C10上,通過將 k 從 12 增加到 24,模型的引數量增加了 4倍,而誤差卻從 5.77% 增加到 5.83%,DenseNet-BC 的 bottleneck 和 compression層似乎是應對這種現象的一種有效措施。
過擬合(Overfitting)。更高效的利用引數的一個作用是DenseNets不容易發生過擬合。在不使用資料增強的資料集上,我們發現到 DenseNet結構和之前的工作相比較,其改進還是很明顯的。在C10上,誤差降了 29%,從 7.33%降到了 5.19%。在C100上,降了大約 30%,從 28.2%降到了 19.64%。通過實驗,我們發現一個潛在的過擬合現象:在C10上,通過將 k 從 12 增加到 24,模型的引數量增加了 4倍,而誤差卻從 5.77% 增加到 5.83%,DenseNet-BC 的 bottleneck 和 compression層似乎是應對這種現象的一種有效措施。



4.4 ImageNet 分類結果
我們在ImageNet分類任務上測試了不同深度和增長速率的 DenseNet-BC 的誤差,並且和ResNet結構的效能進行了比較。為了對這兩種結構有一個公平的比較,我們排除了其他所有的因素,如資料預處理方式,優化器設定。我們僅僅將 DenseNet-BC 網路替代ResNet模型,而保留ResNet的其他實驗引數不變。
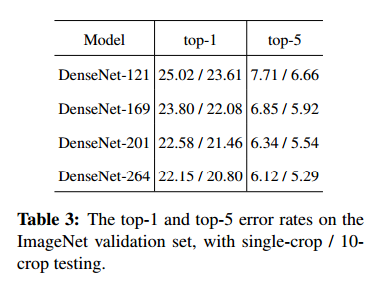
我們記錄了DenseNets在ImageNet上 single-crop 和 10-crop的驗證誤差,如表3所示。
DenseNets 和 ResNets Single-crop的top-1 驗證誤差如圖3所示,其中左圖以引數量為變數,右圖以 FLOPs為變數。

如圖3所示,與ResNets相比,在相同效能的前提下 DenseNets引數量和計算量更小。例如,擁有 20M 引數的 DenseNet-201 的誤差率和擁有超過 40M 引數的 101-ResNet 誤差率相近。從圖3的右圖也可以看到類似的結果:和ResNet-50 計算量接近的 DenseNet 大約是 ResNet-101 計算量的兩倍。
圖3是DenseNet-BC 和 ResNet在ImageNet資料集上的對比,左邊的那個圖是引數複雜度和錯誤率的對比,你可以在相同錯誤率下看引數複雜度,也可以在相同引數複雜度下看錯誤率,提升還是很明顯的,右邊是flops(可以理解為計算複雜度)和錯誤率率的對比,同樣有效果。
值得注意的是,我們是修改和ResNets對應的超引數而不是DenseNets的。我們相信還可以通過修改更多的超引數來優化DenseNet在ImageNet上的效能。

圖4也很重要,左邊的圖表示不同型別DenseNet的引數和 error 對比。中間的圖表示 DenseNet-BC和ResNet在引數和error的對比,相同 error 下,DenseNet-BC的引數複雜度要小很多。右邊的圖也是表達 DenseNet-BC-100 只需要很少的引數就能達到和 ResNet-1001相同的結果。


5,討論
從表面來看,DenseNets和ResNets很像:方程(2)和方程(1)的不同主要在輸入 Hl(*) (進行拼接而不是求和)。然而,這個小的改變卻是給這兩種網路結構的效能帶來了很大的差異。
模型簡化性(Model Compactness)。將輸入進行連線的直接結果是,DenseNets 每一層學到的特徵圖都可以被以後的任一層利用。該方式有助於網路特徵的重複利用,也因此得到了更簡化的模型。
圖4左邊的兩張圖展示了實驗的結果,左圖比較了所有 DenseNets的引數效率,中圖對DenseNets 和 ResNets 的引數效率進行了比較。我們在 C10+ 資料上訓練了不同深度的多個小模型,並繪製出準確率。和一些流行的網路(如AlexNet, VGG)相比,pre-activation 的 ResNets 的準確率明顯高於其他網路。之後,我們將 DenseNets (k=12)與這網路進行了比較。DenseNet的訓練集同上節。
如圖4,DenseNet-BC 是引數效率最高的一個 DenseNet 版本。此外,DenseNet-BC 僅僅用了大概 ResNets 1/3 的引數量就獲得了相近的準確率(中圖)。該結果與圖3的結果相一致。如圖4右圖,僅有 0.8M 引數量的 DenseNet-BC 和有 10.2M引數的 101-ResNets 準確率相近。

隱含的深度監督(implicit deep supervision)。稠密卷積網路可以提升準確率的一個解釋是,由於更短的連線,每一層都可以從損失函式中獲得監督資訊。可以將 DenseNets 理解為一種“深度監督”(Deep supervision)。深度監督的好處已經在之前的深度監督網路(DSN)中說明,該網路在每一隱含層都加了分類器,迫使中間層也學習判斷特徵(discriminative features)。
DenseNet和深度監督網路相似:網路最後的分類器通過最多兩個或三個過度層為所有層提供監督資訊。然而,DenseNets的損失含數字和梯度不是很複雜,這是因為所有層之間共享了損失函式。


隨機 VS 確定連線。稠密卷積網路與殘差網路的隨機深度正則化(stochastic depth regularzaion)之間有著有趣的關係。在隨機深度中,殘差網路隨機丟掉一些層,直接將周圍的層進行連線。因為池化層沒有丟掉,所以該網路和DenseNet有著相似的連線模式:以一定的小概率對相同池化層之間的任意兩層進行直接連線——如果中間層隨機丟掉的話。儘管這兩個方法在根本上是完全不一樣的,但是 DenseNet 關於隨機深度的解釋會給該正則化的成功提供依據。
總結一下:DenseNet和stochastic depth的關係,在 stochastic depth中,residual中的layers在訓練過程中會被隨機drop掉,其實這就會使得相鄰層之間直接連線,這和DenseNet是很像的。

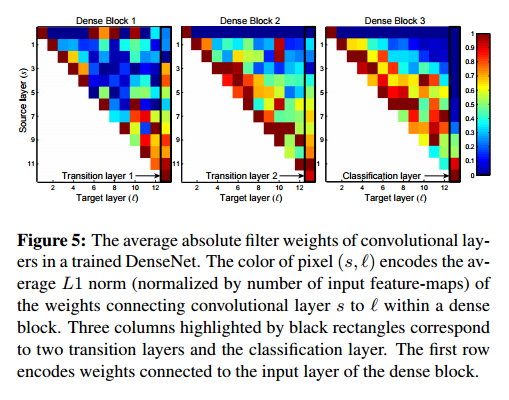
 特徵重複利用。根據設計來看,DenseNets 允許每一層獲得之前所有層(儘管一些是通過過渡層)的特徵圖。我們做了一個實驗來判斷是否訓練的網路可以重複利用這個機會。我們首先在 C10+ 資料上訓練了 L=40, k=12 的 DenseNet。對於每個 block的每個卷積層 l,我們計算其與 s 層連線的平均權重。三個 dense block 的熱度圖如圖 5 所示。平均權重表示卷積層與它之前層的依賴關係。位置(l, s)處的一個紅點表示層 l 充分利用了前 s 層產生的特徵圖。由圖中可以得到以下結論:
特徵重複利用。根據設計來看,DenseNets 允許每一層獲得之前所有層(儘管一些是通過過渡層)的特徵圖。我們做了一個實驗來判斷是否訓練的網路可以重複利用這個機會。我們首先在 C10+ 資料上訓練了 L=40, k=12 的 DenseNet。對於每個 block的每個卷積層 l,我們計算其與 s 層連線的平均權重。三個 dense block 的熱度圖如圖 5 所示。平均權重表示卷積層與它之前層的依賴關係。位置(l, s)處的一個紅點表示層 l 充分利用了前 s 層產生的特徵圖。由圖中可以得到以下結論:
- 1,在同一個 block 中,所有層都將他的權重傳遞給其他層作為輸入。這表明早期層提取的特徵可以被同一個 dense block 下深層所利用
- 2,過渡層的權重也可以傳遞給之前 dense block 的所有層,也就是說 DenseNet 的資訊可以以很少的間接方式從第一層流向最後一層
- 3,第二個和第三個 dense block 內的所有層分配最少的權重給過渡層的輸出,表明過渡層輸出很多冗餘特徵。這和 DenseNet-BC 強大的結果有關係
- 4,儘管最後的分類器也使用通過整個 dense block 的權重,但似乎更關注最後的特徵圖,表明網路的最後也會產生一些高層次的特徵。


6,結論
我們提出了一個新的卷積網路結構,稱之為稠密卷積網路(DenseNet)。它將兩個相同特徵圖尺寸的任意層進行連線。這樣我們就可以很自然的設計上百層的網路,還不會出現優化困難的問題。在我們的實驗中,隨著引數量的增加,DenseNets的準確率也隨之提高,而且也沒有出現交叉表現或過擬合的現象。通過超引數的調整,該結構在很多比賽的資料上都獲得了不錯的結果。此外,DenseNets有更少的引數和計算量。因為我們只是在實驗中調整了對於殘差網路的超引數,所以我們相信通過調整更多的超引數和學習率,DenseNets的準確率還會有更大的提升。
遵循這個簡單的連線規則,DenseNet可以很自然地將自身對映(identity mappings),深度監督(deep supervision)和深度多樣化(diversified depth) 結合在一起。根據我們的實驗來看,該結構通過對網路特徵的重複利用,可以學習到更簡單,準確率更高的模型。由於簡化了內部表徵和降低了特徵冗餘,DenseNets可能是目前計算機視覺領域中在卷積網路方面非常不錯的特徵提取器。在以後的工作中我們計劃研究 DenseNets下的特徵遷移工作。
&n