
Python推薦演算法案例(3)——基於協同推薦的電影推薦
阿新 • • 發佈:2019-01-21
上一節是根據物品item的描述屬性進行基於內容的推薦基於內容的電影推薦,本節中還是以電影推薦為例,講解基於內容的協同推薦演算法。
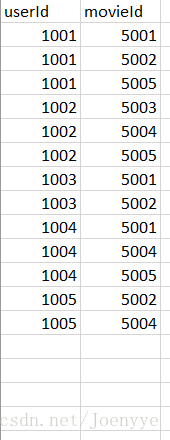
python程式碼如下
import pandas as pd
useritemdata=pd.read_csv('C:/Users/Ray/Desktop/recommand/ml01/ratings.csv')
useritemdata.head()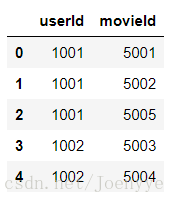
itemlist=list(set(useritemdata['movieId'].tolist()))
# print(itemlist)usercount=len(set(useritemdata['userId'].tolist())) print(usercount)
5
itemAffinity=pd.DataFrame(columns=('item1','item2','score'))
rowcount=0for ind1 in range(len(itemlist)): item1users=useritemdata[useritemdata.movieId==itemlist[ind1]]['userId'].tolist() # print(itemlist[ind1],item1users) for ind2 in range(ind1,len(itemlist)): if (ind1==ind2): continue item2users=useritemdata[useritemdata.movieId==itemlist[ind2]]['userId'].tolist() # print(itemlist[ind2],item2users) commentusers=len(set(item1users).intersection(set(item2users))) score=commentusers/usercount itemAffinity.loc[rowcount]=[itemlist[ind1],itemlist[ind2],score] rowcount+=1 itemAffinity.loc[rowcount]=[itemlist[ind2],itemlist[ind1],score] rowcount+=1 itemAffinity.head()

def getrecommendation(searchitem):
recolist=itemAffinity[itemAffinity.item1==searchitem][['item2','score']].sort_values('score',ascending=[0])
return recolistsearchitem=5001
recolist=getrecommendation(searchitem)
print('recommendations for movieid'+str(searchitem)+'\n',recolist.head(5))