
複雜背景的驗證碼識別破解 以Discuz的動畫驗證碼為例。
阿新 • • 發佈:2019-01-21
對於比較複雜的驗證碼,比如DZ論壇最新的驗證碼,處理起來相對麻煩一些,但是原理還是和普通的識別一樣的,無非多了個背景處理的方案,看如下對DZ論壇的驗證碼的識別的思路
首先我們要去除它的背景,對於這樣稍微複雜的背景,用過去的方法很難做到,上圖的例子還不是很明顯,我發現很多圖片背景色和字母色近似,而且字母顏色是不斷變化的,背景也是不斷變化的
那我初始的想法是找到圖片中使用顏色最多的方法,於是我們用HSL表示各點顏色,接著進行統計,得到最大的幾個峰值,這裡便是圖片中幾個最豐富的顏色的L值得累加值
其餘的都可以認為是噪音,我們對每個峰值進行分割,得到如下圖片
你看這樣就把單個顏色圖片分割出來了,接下來就是找到圖片中除去黑色和白色後的圖片
然後進行灰化處理,閥值處理,降噪,得到
接著根據邊界檢測出來的最左側x位置,來排序字母順序
接下來的事情就輕車熟路了,把圖片轉成標準模板,通過少量學習就達到了95%以上的識別率
c:15 j:8 8:7 t:9 9:4 x:7 4:6 2:4 h:7 f:8 e:18 b:5 y:3 k:4 w:3 g:5 3:5 7:6 r:2 m:3 q:4 v:2 p:3 6:2
以上資料表示 c學習15次 j學習8次…
 電腦程式設計入門
電腦程式設計入門
 創意園區出租
創意園區出租
 遊戲製作學習
遊戲製作學習
只要字元不粘連,大部分驗證碼干擾技術都是可以有辦法,所以為什麼google驗證碼看起來很簡單,但是沒有人能夠很好的破解它得原因。
補充,
rise在留言中發現有一些字元加入雜點的問題,由於這種驗證碼不是很普遍,稍微做了研究
CY3E 這個圖片3字中有雜點,其他沒有,按照文章中介紹的辦法,怎麼知道這個3不是像其他顏色雜點一樣的圖片呢?
我覺得需要加入一個步驟,就是對每次過濾顏色生成出來的圖片,進行填充
找到3的雜點原圖:
然後我們進行演算法填充
這個圖片與其他全部是雜點的圖片之間的差別進行過濾,我考慮可以通過以下方法:
1、連貫點的寬度
2、連貫點的個數
這樣剩下的就只剩下CY3E的過濾後的圖片
至於字元傾斜的問題,我覺得完全可以在機器學習過程中,我們自己旋轉正在學習的圖片一定角度,例如從-10到+10度,只不過這樣的學習庫會大一些,但是就10個數字的驗證碼來說,這點效能損失應該可以忽略不計。

首先我們要去除它的背景,對於這樣稍微複雜的背景,用過去的方法很難做到,上圖的例子還不是很明顯,我發現很多圖片背景色和字母色近似,而且字母顏色是不斷變化的,背景也是不斷變化的





那我初始的想法是找到圖片中使用顏色最多的方法,於是我們用HSL表示各點顏色,接著進行統計,得到最大的幾個峰值,這裡便是圖片中幾個最豐富的顏色的L值得累加值
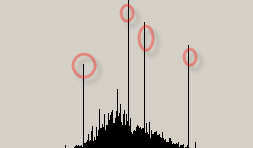
其餘的都可以認為是噪音,我們對每個峰值進行分割,得到如下圖片

你看這樣就把單個顏色圖片分割出來了,接下來就是找到圖片中除去黑色和白色後的圖片

然後進行灰化處理,閥值處理,降噪,得到

接著根據邊界檢測出來的最左側x位置,來排序字母順序

接下來的事情就輕車熟路了,把圖片轉成標準模板,通過少量學習就達到了95%以上的識別率
c:15 j:8 8:7 t:9 9:4 x:7 4:6 2:4 h:7 f:8 e:18 b:5 y:3 k:4 w:3 g:5 3:5 7:6 r:2 m:3 q:4 v:2 p:3 6:2
以上資料表示 c學習15次 j學習8次…

只要字元不粘連,大部分驗證碼干擾技術都是可以有辦法,所以為什麼google驗證碼看起來很簡單,但是沒有人能夠很好的破解它得原因。
補充,
rise在留言中發現有一些字元加入雜點的問題,由於這種驗證碼不是很普遍,稍微做了研究

CY3E 這個圖片3字中有雜點,其他沒有,按照文章中介紹的辦法,怎麼知道這個3不是像其他顏色雜點一樣的圖片呢?

我覺得需要加入一個步驟,就是對每次過濾顏色生成出來的圖片,進行填充
找到3的雜點原圖:

然後我們進行演算法填充
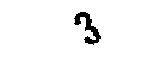
這個圖片與其他全部是雜點的圖片之間的差別進行過濾,我考慮可以通過以下方法:
1、連貫點的寬度
2、連貫點的個數
這樣剩下的就只剩下CY3E的過濾後的圖片
至於字元傾斜的問題,我覺得完全可以在機器學習過程中,我們自己旋轉正在學習的圖片一定角度,例如從-10到+10度,只不過這樣的學習庫會大一些,但是就10個數字的驗證碼來說,這點效能損失應該可以忽略不計。