
Action Recognition with Fisher Vectors(idt source codes)
Original url:
http://www.bo-yang.net/2014/04/30/fisher-vector-in-action-recognition
This is a summary of doing human action recognition using Fisher Vector with (Improved) Dense Trjectory Features(DTF, http://lear.inrialpes.fr/~wang/improved_trajectories) and STIP features(http://crcv.ucf.edu/ICCV13-Action-Workshop/download.html) on UCF 101
dataset(
You can find my Matlab code from my GitHub Channel:
Dense Trajectory Features
For some details of DTF, please refer to my previous post.
Pipeline
The pipeline of integrating DTF/STIP features and Fisher vectors is shown in Figure 1. The first step is subsampling a fixed number of STIP/DTF features(in my implementation, 1000) from each video clip in training list, which will be used to do PCA and train Gaussian Mixture Models(GMMs).
After getting the PCA coefficients and GMM parameters, treat UCF 101 video clips action by action. For each action, first load all train videos in this action(positive videos), and then randomly load the same number of video clips not in this action(negative videos). All of the loaded videos are multiplied with the saved PCA coefficients in order to reduce dimensions and rotate matrices. Fisher vectors are computed for each loaded video clip. Finally a binary SVM model is trained with both the positive and negative Fisher vectors.
When dealing with the test videos, similar process is adopted. The only difference is that the Fisher vectors are used for SVM classification, which is based on the SVM model trained with training videos.
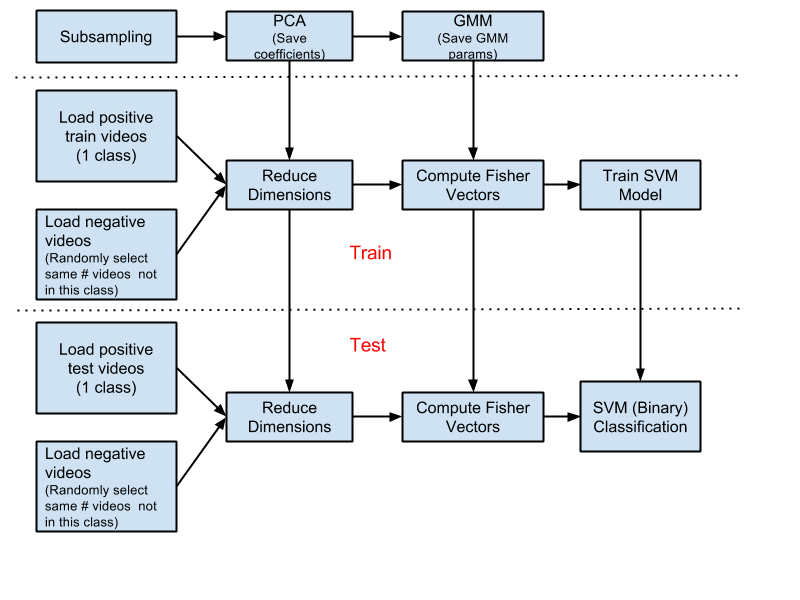 .
.
To well utilize the STIP or DTF features, features(HOG, HOF, MBH, etc.) are treated separately and they are only combined(simple concatenation) after computing Fisher vectors before linear SVM classification.
Pre-processing
STIP Features
The offcial STIP features are stored in class, which means that all the STIP info of all video clips in each class are mixed together in a file. To extract STIP features for each video, I wrote a script mk_stip_data to separate STIP features for each video clip. And all the following operations are based on each video clip.
DTF Features
Since the DTF features are “dense”(which means a lot of data), it took me 4~5 days to exact the (improved) DTF features of UCF 101 clips with the dedault parameters on a modern Linux desktop(I used 10 threads for extraction in paralle). The installation of DTF tools was also a very tricky task.
To save space, all the DTF features were compressed using script gzip_dtf_files. For UCF101, it would cost about 500GB after compression. And the required space would be doubled if no compression. If you don’t want to save the DTF features, you can call the DTF tools in Matlab and discard the extracted features.
Fisher Vector
The Fisher Vector (FV) representation of visual features is an extension of the popular bag-of-visual words (BOV)[1]. Both of them are based on an intermediate representation, the visual vocabulary built in the low level feature space. A probability density function (in most cases a Gaussian Mixture Model) is used to model the visual vocabulary, and we can compute the gradient of the log likelihood with respect to the parameters of the model to represent an image or video. The Fisher Vector is the concatenation of these partial derivatives and describes in which direction the parameters of the model should be modified to best fit the data. This representation has the advantage to give similar or even better classification performance than BOV obtained with supervised visual vocabularies.
Following is the algorithm of computing Fisher vectors from features(actually I implemented this algorithm in Matlab, and if you are interested, please refer here):
 .
.
During the subsampling of STIP features, I randomly chose 1000 HOG or HOF features from each training video clip. For some videos, if the total number of features were less than 1000, I would use all of their features. All the subsampled features are square rooted after L1 normalization.
After that, the dimensions of the subsampled features were reduced to half of their original dimensions by doing PCA. At this step, the coefficients of PCA were recorded, which would be used in later. The GMMs were trained with the half-sized features, and the parameters of GMMs(i.e. weight, mean and covariance) were stored for the following process. In my program, the GMM code implemented by Oxford Visual Geometry Group(VGG) is used, which eventually call VLFeat. In my code, 256 Gaussians were used.
When computing the Gaussians, sometimes value Inf will be returned. For the Inf entries, a very large number(in my code, 1e30) is assigned instead to make the subsequent computation smoother. Before the L2 and power normalization, the unexpected NaN entries are replaced by a large number(in my implementation, 123456).
SVM Classification
Binary SVM classification(LIBSVM) is used in my implementation. For each action, positive video clips are labeled as 1 while negative videos are as labeled -1 during training and test. In my code, SVM cost is set to 100. The option of SVM training is:
-t 0 -s 0 -q -c 100 -b 1.
Results
The action recognition accuracy of all the 101 actions was 77.95% when using above pipeline and STIP features. And the confusion matrix is shown in Figure 3.
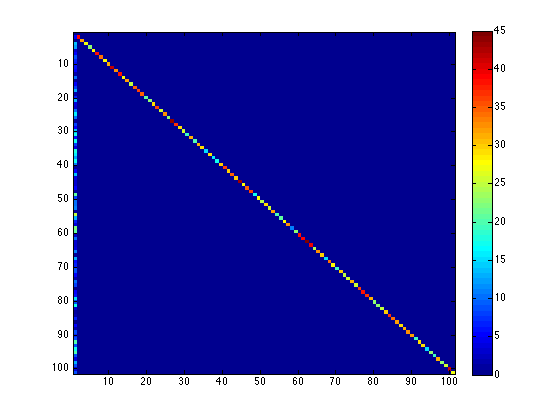
The mean accurary of the fist 10 actions with DTF features was 90.6%, while the STIP was only 84.32%. The mean accuracy of the whole UCF 101 data(train/test list 1) was around 85% using DTF features, about 8% higher than using BOV representations(internal test). And the best result I got with the ISA neural network on UCF 101 was only 58% in November, 2013.
Conclusion
It is obvious that Fisher vector can lead to better results than Bag-of-visual words in action recognition. Compared to other low-level visual features, DTF features have more advantages in action recognition. However, in the long run I still believe deep learning methods - when deep neural networks could be trained with millions of vidios[5], they would learn more info from scratch and achieve state-of-the-art accuracy.
References
- Gabriela Csurka, Florent Perronnin, Fisher Vectors: Beyond Bag-of-Visual-Words Image Representations , Communications in Computer and Information Science Volume 229, 2011, pp 28-42.
- Chih-Chung Chang and Chih-Jen Lin. Libsvm: A library for support vector machines. ACM Trans. Intell. Syst. Technol., 2(3):27:1–27:27, May 2011.
- Heng Wang and Cordelia Schmid. Action Recognition with Improved Trajectories. In ICCV 2013 - IEEE International Conference on Computer Vision, Sydney, Australia, December 2013. IEEE.
- Jorge Sanchez, Florent Perronnin, Thomas Mensink, and Jakob Verbeek. Image Classification with the Fisher Vector: Theory and Practice. International Journal of Computer Vision, 105(3):222–245, December 2013.
- Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, and Li Fei-Fei. Large-scale video classification with convolutional neural networks. In CVPR, 2014.
相關推薦
Action Recognition with Fisher Vectors(idt source codes)
Original url: http://www.bo-yang.net/2014/04/30/fisher-vector-in-action-recognition This is a summary of doing human action recognitio
Learning hierarchical spatio-temporal features for action recognition with ISA
Reading papers_16(Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis)
讀書筆記25:Temporal Hallucinating for Action Recognition with Few Still Images(CVPR2018)
openaccess.thecvf.com/content_cvpr_2018/papers/Wang_Temporal_Hallucinating_for_CVPR_2018_paper.pdf 摘要首先介紹背景,從靜態圖片中進行動作識別最近被深度學習方法促進,但是成功的
【論文閱讀】Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition
【論文閱讀】Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition 這是2017ICCV workshop的一篇文章,這篇文章只是提出了一個3D-ResNets網路,與之前介紹的
【bug】使用spring+struts2註解開發,提示” There is no Action mapped for namespace [/] and action name [xxxxx.action] associated with context path []”
there 提示 就是 技術分享 文件夾路徑 iat class bubuko ring 使用註解開發,通過spring管理struts2容器,配置文件沒有問題,前臺路徑無誤 錯誤提示: There is no Action mapped for namespace [/]
Local Generic Representation for Face Recognition with Single Sample per Person (ACCV, 2014)
任務 strac iat 挑戰 dataset 進行 通用 trac present Abstract: 1. 每個類別單個樣本的人臉識別(face recognition with single sample per person, SSPP)是一個非常有挑戰性的任務,因
【USE】《An End-to-End System for Automatic Urinary Particle Recognition with CNN》
Urine Sediment Examination(USE) JMOS-2018 目錄 目錄 1 Background and Motivation 2 Innovation
視訊行為識別閱讀[2]Temporal Segment Networks: Towards Good Practices for Deep Action Recognition[2016]
[2]Temporal Segment Networks: Towards Good Practices for Deep Action Recognition[2016](TSN網路) 概括: 為了解決長序列的視訊行為識別問題,將長序列切分成短序列並從中隨機選擇部分,作為雙流網路的
Optical Flow Guided Feature A Fast and Robust Motion Representation for Video Action Recognition論文解讀
Optical Flow Guided Feature A Fast and Robust Motion Representation for Video Action Recognition論文解讀 1. Abstract 2. 論文解讀 3
《2018-Deep Progressive Reinforcement Learning for Skeleton-based Action Recognition》
動機 這篇文章開篇就指出,我們的模型是要從人體動作的序列中選取出最informative的那些幀,而丟棄掉用處不大的部分。但是由於對於不同的視訊序列,挑出最有代表性的幀的方法是不同的,因此,本文提出用深度增強學習來將幀的選擇模擬為一個不斷進步的progressive proces
【CV論文閱讀】Two stream convolutional Networks for action recognition in Vedios
論文的三個貢獻 (1)提出了two-stream結構的CNN,由空間和時間兩個維度的網路組成。 (2)使用多幀的密集光流場作為訓練輸入,可以提取動作的資訊。 (3)利用了多工訓練的方法把兩個資料集聯合起來。 Two stream結構 視屏可以分成空間與時間兩個部
視訊動作識別--Two-Stream Convolutional Networks for Action Recognition in Videos
Two-Stream Convolutional Networks for Action Recognition in Videos NIPS2014http://www.robots.ox.ac.uk/~vgg/software/two_stream_action/ 本文針對視訊中的動作分類問
24.Two-Stream Convolutional Networks for Action Recognition in Videos
Two-Stream Convolutional Networks for Action Recognition in Videos 用於視訊中動作識別的雙流卷積網路 摘要 我們研究了經過區別訓練的深度卷積網路(ConvNets)的體系結構,用於視訊中的動作識別。挑戰在於從靜止幀和幀間的
Compressed Video Action Recognition論文筆記
Compressed Video Action Recognition論文筆記 這是一篇2018年的CVPR論文。做了關鍵內容的記錄。對於細節要去論文中認真找。 摘要:訓練一個穩定的視訊表示比學習深度影象表示更加具有挑戰性。由於原始視訊的尺寸巨大,時間資訊大量冗餘,那些真正有用的訊號通常被大
讀書筆記25:2D/3D Pose Estimation and Action Recognition using Multitask Deep Learning(CVPR2018)
摘要:首先指出背景,即action recognition和human pose estimation是兩個緊密相連的領域,但是總是被分開處理。然後自然地引出本文的模型,本文的模型就針對這個現狀,提出了一個multitask framework,既能從靜態image中進行
讀書筆記32:PoTion: Pose MoTion Representation for Action Recognition(CVPR2018)
摘要首先介紹背景,很多一流的動作識別方法都依賴於two-stream的架構,一個處理appearance,另一個處理motion。接著介紹本文工作,本王呢認為將這兩個合起來考慮比較好,引入了一個新的representation,可以將semantic keypoints的
譯:Two-Stream Convolutional Networks for Action Recognition in Videos.md
摘要:我們研究了用於訓練視訊中行為識別的深度卷積網路架構。這個挑戰是捕捉靜態幀中的外觀和連續幀間的運動的互補資訊。我們也旨在推廣這個在資料驅動的學習框架中表現得最好的手工特徵。 本文一共做出了3個貢獻: 首先,本文提出了一個two-stream卷積網路架構,這
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
本文是deepmind出品,目的,就一個,放出個關於視訊方面的訓練集kinetics,一個四百個類,每個類有至少四百個clips,每個clips十秒鐘,屬於從youtube上剪下的視訊,然後對比了幾種現在存在的用於行為識別的幾種框架,具體如下圖: 其中,a,b
Optical Flow Guided Feature: A Fast and Robust Motion Representation for Video Action Recognition 翻譯
光流引導特徵:視訊動作識別的快速魯棒運動表示
論文筆記 | A Closer Look at Spatiotemporal Convolutions for Action Recognition
( 這篇博文為原創,如需轉載本文請email我: [email protected], 並註明來源連結,THX!) 本文主要分享了一篇來自CVPR 2018的論文,A Closer Look at Spatiotemporal Convolutions for Action Rec