視訊行為識別閱讀[2]Temporal Segment Networks: Towards Good Practices for Deep Action Recognition[2016]
[2]Temporal Segment Networks: Towards Good Practices for Deep Action Recognition[2016](TSN網路)
概括:
為了解決長序列的視訊行為識別問題,將長序列切分成短序列並從中隨機選擇部分,作為雙流網路的輸入,採用多個這樣的雙流網路,最後將各個子網路的得分值進行均值融合得到最終結果。
#####介紹:
(1)對於長序列的學習能力在理解視訊行為上具有重要意義,但是主流的雙流法和C3D通常只是聚焦於表面或者是短時間序列的學習(C3D的輸入是連續的16幀,而雙流法是依靠前後兩幀計算出來的光流)。Long-term temporal convolutions for action recognition.[2016]、Beyond short snippets: Deep networks for video classification.[CVPR2015]、Long-term recurrent convolutional networks for visual recognition and description[CVPR2015]等文章通過預定義的取樣間隔進行稠密時序取樣解決這種問題,但是卻增大了計算量。
(2)卷積神經網路訓練需要大量的資料,否則容易過擬合,公開資料集UCF101和HMDB51在尺寸和多樣性上不足。在影象識別中非常深的網路,例如Very deep convolutional networks for large-scale image recognition. [[ICLR2015]和Batch normalization: Accelerating deep network training by reducing internal covariate shift.[ICMl2015],在視訊行為識別中可能存在較高的過擬合風險。
(3)連續視訊幀具有高度冗餘性(相鄰動作間的相似性極大)。TSN在長的視訊序列上均勻的抽取短的序列,然後在聚合這些資訊,這樣TSN能夠模擬長的視訊。
(4)為了釋放該網路的潛力,使用了非常深的網路Batch normalization: Accelerating deep network training by reducing internal covariate shift.[ICMl2015]和Very deep convolutional networks for large-scale image recognition. [[ICLR2015],探索了一些方法去使用少量的樣本就可以進行訓練。例如:資料增強、 跨模態預訓練、 正則化。
You lead, we exceed: Labor-free video concept learning by jointly exploiting web videos and images. In: CVPR
相關工作:
(卷積方法)除了經典的C3D和雙流以外,Human action recognition using factorized spatio-temporal convolutional networks.疊加RGB差分的視訊作為輸入。相似的採用長視訊(固定視訊輸入的長度在64到120,但是TSN由於稀疏取樣沒有這種限制)輸入的有Beyond short snippets: Deep networks for video classification. In: CVPR. (2015);Long-term temporal convolutions for action recognition. 2016;Long-term recurrent convolutional networks for visual recognition and description. In: CVPR. (2015) 。
(時序結構模型)原子時序模型(Temporal localization of actions with actoms. IEEE2013;人體骨骼模型
#####細節
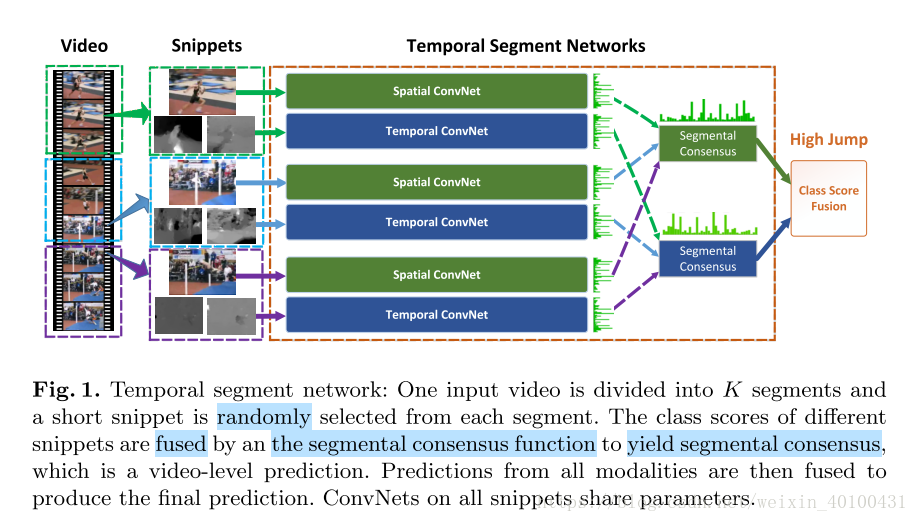
一個長視訊被分解成k個片段(相等間隔),從每一個片段中隨機選擇一幀,不同的片段得到的結果通過一致性函式產生最終結果(一個視訊級別的預測,一段視訊給出一個結果)
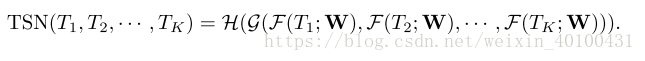
函式F表示對使用卷積網路作用於視訊片段T得到一個片段各個類別的得分值
函式G表示對整個各個片段的得分值進行一致性選擇,得到一致意見(最終選擇的是對各個類別的得分值直接求均值)
函式H將各個類別的得分值裝換成概率值(這裡使用的是softmax)
下面是損失函式的設計:
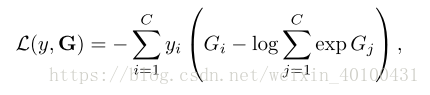
沒看懂,文章說是使用標準的交叉熵損失。這裡G是一個得分值,不應該先轉換成概率值嗎?然後括號裡面對其所有的類別進行exp後又進行相加?那麼,這樣不同的類別後面這部分就是一個常量了。
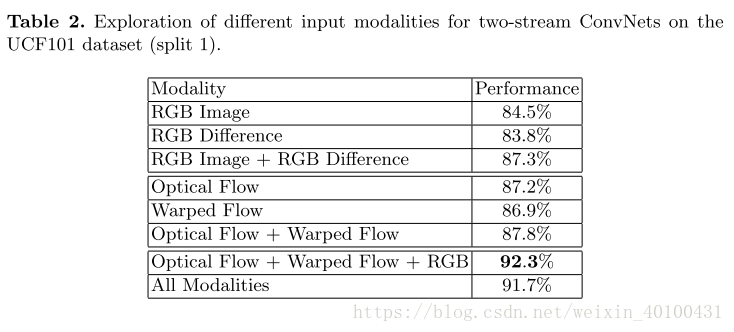
使用Batch normalization: Accelerating deep network training by reducing internal covariate shift.[ICMl2015](BN-Inception)作為網路架構的雙流法。在雙流法中,空間網路輸入都是RGB影象,而時序網路的輸入是光流或者堆疊光流場,作者在文章中提出探索了兩種額外的模式,RGB差分和扭曲光流場(wraped optical flow fields)。實驗表明,扭曲光流場更加專注於移動者本身,因此採用這種輸入。
測試的時候在雙流融合階段,使用加權平均的方式進行融合。
測試
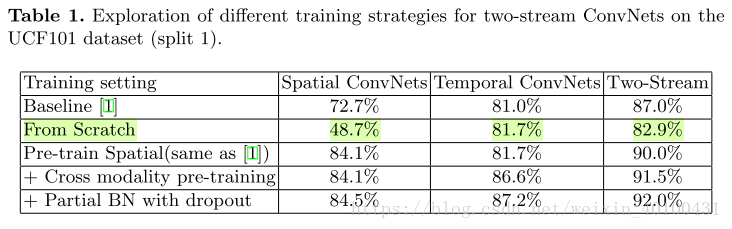
四種訓練模式,第一行:原始雙流網路;第二行,從頭開始;第三行:預訓練空間流;第四行:交叉模式預訓練;第五行:交叉預訓練和部分BN dropout相結合。