
統計學習(監督學習)框架總結
以下內容參考《統計學習方法》李航著,《Python機器學習及實踐》範淼、李超著
機器學習:監督學習——對事物未知表現的預測
無監督學習——對事物本身特性的分析
半監督學習,強化學習
無監督學習:資料降維——對事物的特性進行壓縮和篩選,如影象降維時保留最具有區分度的畫素組合
聚類——依賴於資料的相似性,把相似的資料樣本劃分為一個簇。不會預先知道簇的數量和每個簇的具體含義
統計學習:資料——>提取資料特徵——>抽象資料模型——>對資料預測分析
——————————————————————————————————————
模型————————策略————————演算法
假設空間——————評價準則——————模型選取
不同模型——————損失函式————— 解優化問題
(同一學習方法不同引數)
——————————————————————————————————————
學習模型:決策函式f(X),條件概率分佈P(Y|X)
優化目標:損失函式————>期望風險————>經驗風險——經驗風險最小化————>結構風險=經驗風險+正則化項
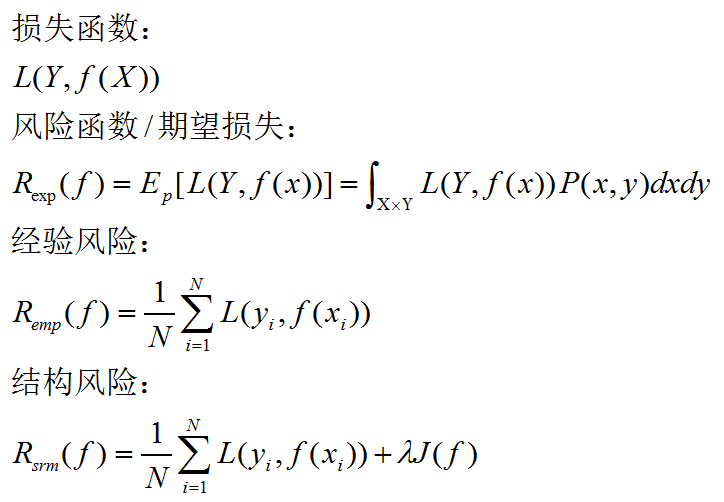
過擬合:
過分追求提高對訓練資料的預測能力,所選模型的複雜度比真實模型複雜度更高———學習模型包含的引數過多。
模型選擇:正則化,交叉驗證
正則化:結構風險最小化,在經驗風險上加上一個正則化項/罰項,正則化項是模型複雜度的單增函式
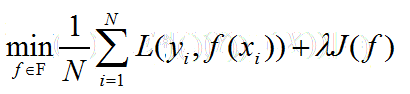
訓練集/測試集——>簡單交叉驗證
訓練集/測試集——>S折交叉驗證,留一交叉驗證(選擇“多次評測的平均測試誤差最小的”模型)
泛化能力
學到模型對未知資料預測的誤差,即為泛化誤差——學習方法的泛化能力,所學習到的模型的期望風險
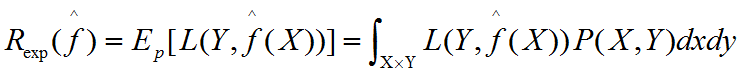
生成模型:由資料學習聯合概率分佈P(X,Y),然後求出條件概率分佈P(Y|X)作為預測模型,即生成模型P(Y|X)=P(X,Y)/P(X)————存在隱變數
典型的生成模型:樸素貝葉斯法,隱馬爾可夫模型
判別模型:由資料直接學習決策函式f(X)或者條件概率分佈P(Y|X)作為預測的模型。即對給定的輸入X,應該預測什麼樣的輸出Y。
典型的判別模型:k近鄰法,感知機,決策樹,邏輯斯蒂迴歸模型,最大熵模型,支援向量機,提升方法,條件隨機場
監督學習:分類問題,標註問題,迴歸問題
可用於分類問題的統計學習方法:k近鄰法,感知機,樸素貝葉斯法,決策樹,決策列表,邏輯斯蒂迴歸模型,支援向量機,提升方法,貝葉斯網路,神經網路,Winnow
可用於標註問題的統計學習方法:隱馬爾可夫模型,條件隨機場
相關推薦
統計學習(監督學習)框架總結
以下內容參考《統計學習方法》李航著,《Python機器學習及實踐》範淼、李超著 機器學習:監督學習——對事物未知表現的預測 無監督學習——對事物本身特性的分析 半監督學習,強化學習 無監督學習:
機器學習(1-1) 監督學習
收集 是否 分開 希望 專業 思想 技術分享 多個 無限 監督學習 在本視頻中,我將介紹一種也許是最常見的機器學習問題。即監督學習。後面將給出監督學習更正式的定義,現在最好以示例來說明什麽是監督學習。之後再給出正式的定義。 假設你想預測房價(無比需要啊!),之前,某學生已經
易百教程人工智能python修正-人工智能監督學習(回歸)
plot imp repr sin 人工智能 ima 多變量 修正 shel 回歸是最重要的統計和機器學習工具之一。 我們認為機器學習的旅程從回歸開始並不是錯的。 它可以被定義為使我們能夠根據數據做出決定的參數化技術,或者換言之,允許通過學習輸入和輸出變量之間的關系來基於數
人工智慧 深度學習(Deep learning)開源框架
Google開源了TensorFlow(GitHub),此舉在深度學習領域影響巨大,因為Google在人工智慧領域的研發成績斐然,有著雄厚的人才儲備,而且Google自己的Gmail和搜尋引擎都在使用自行研發的深度學習工具。 1、Caffe。源自加州伯克利分校的Caffe被廣泛應用,包括Pint
salesforce零基礎學習(九十)專案中的零碎知識點小總結(三)
本次的內容其實大部分人都遇到過,也知道解決方案。但是因為沒有牢記於心,導致問題再次出現還是花費了一點時間去排查了原因。在此記錄下來,好記性不如爛筆頭,爭取下次發現類似的現象可以直接就知道原因。廢話少說,進入正題。 我們在Goods__c表中有一個欄位型別為Picklist,欄位值有以下內容: 我們想要
非監督特徵學習與深度學習(十五)--------長短記憶(Long Short Term Memory,LSTM)
LSTM LSTM概述 長短記憶(Long Short Term Memory,LSTM)是一種 RNN 特殊的型別,可以學習長期依賴資訊,它引入了自迴圈的巧妙構思,以產生梯度長時間持續流動的路徑,解決RNN梯度消失或爆炸的問題。在手寫識別、
機器學習系列文章(監督學習):迴歸
在機器學習領域,最神奇的模型當屬迴歸模型,迴歸模型也是非專業人員一談機器學習就能無意涉及到的內容。在這裡,筆者先談談當前資訊學科被無良媒體誇大報道賺取點選率關注度的商業行為。不知何時起,國民自負的以為手裡拿著手機,包裡揹著筆記本就以為掌握了資訊時代發展的最前沿資訊。這種不理性
機器學習與深度學習系列連載: 第一部分 機器學習(十四)非監督度學習-1 Unsupervised Learning-1
非監督度學習-1 Unsupervised Learning-1(K-means,HAC,PCA) 非監督學習方法主要分為兩大類 Dimension Reduction (化繁為簡) Generation (無中生有) 目前我們僅專注化繁為簡,降維的方法,
機器學習與深度學習系列連載: 第一部分 機器學習(十五)非監督度學習-2 Unsupervised Learning-2(Neighbor Embedding)
臨近編碼 Neighbor Embedding 在非監督學習降維演算法中,高緯度的資料,在他附近的資料我們可以看做是低緯度的,例如地球是三維度的,但是地圖可以是二維的。 那我們就開始上演算法 1. Locally Linear Embedding (LLE) 我
機器學習與深度學習系列連載: 第一部分 機器學習(十七)非監督度學習-2 Unsupervised Learning-4(Generative Models)
生成模型 Generative Models 用非監督學習生成結構化資料,是非監督模型的一個重要分支,本節重點介紹三個演算法: Pixel RNN ,VAE 和GAN(以後會重點講解原理) 1. Pixel RNN RNN目前還沒有介紹,,以後會重點講解,大家
統計學習方法(5)整合學習(提升方法)
統計學習方法(4)整合學習(提升方法) 1、Bagging: 基於並行策略:基學習器之間不存在依賴關係,可同時生成。 基本思路: 利用自助取樣法對訓練集隨機取樣,重複進行 T 次; 基於每個取樣集訓練一個基學習器,並得到 T 個基學習器; 預測時,集體投票決策
吳恩達機器學習(十一)K-means(無監督學習、聚類演算法)
目錄 0. 前言 學習完吳恩達老師機器學習課程的無監督學習,簡單的做個筆記。文中部分描述屬於個人消化後的理解,僅供參考。 如果這篇文章對你有一點小小的幫助,請給個關注喔~我會非常開心
機器學習(十六)無監督學習、聚類和KMeans聚類
無監督學習、聚類 聚類是在樣本沒有標註的情況下,對樣本進行特徵提取並分類,屬於無監督學習的內容。有監督學習和無監督學習的區別就是需要分析處理的資料樣本是否事先已經標註。如下圖,左邊是有監督,右邊是無監督: 應用場景也有所不同。 無
機器學習筆記——無監督學習(unsupervised learning)
聚類 之前我們講到的都是監督學習,下面讓我們來看對於無監督學習我們應該如何進行分類呢?無監督學習對應的就是給定的樣本點我們不給輸出值來進行分類 K-means K-means是一種十分常用的演算法,它的過程就是對於給定的K個初始點,首先根據各個樣本點到其的距離進行分類,之後將這K個
Scikit-Learn機器學習之監督學習模型案例集-新聞/郵件文字內容分類(樸素貝葉斯演算法模型)
最簡單的辦法 下載'20news-bydate.pkz', 放到C:\\Users\[Current user]\scikit_learn_data 下邊就行. 2.1. 手動下載 檔案 存放到scikit_learn_data/20new
機器學習兩種方法——監督學習和無監督學習(通俗理解)
前言 機器學習分為:監督學習,無監督學習,半監督學習(也可以用hinton所說的強化學習)等。 在這裡,主要理解一下監督學習和無監督學習。 監督學習(supervised learning) 從給定的訓練資料集中學習出一個函式(模型引數),當新的資料到來時,可以根據這個函式
PythonWeb開發Django框架學習(十一)使用框架自帶Admin管理資料庫資料
上次說到了有關於Model類對於資料庫的資料的增刪改查操作還有一對多,多對多關係的對映操作等等。 這次呢來說一個django管理資料庫的網頁版幫手Admin管理,在我看來,這個和PHP的wamp整合開
監督學習、非監督學習、半監督學習(主動學習)
統計學習通常包括監督學習、非監督學習、半監督學習以及強化學習,在機器學習的領域中前三種研究的比較多的,也是運用的比較廣泛的技術。監督學習監督學習的任務是學習一個模型,使模型對給定的任意的一個輸入,對其都可以映射出一個預測結果。這裡模型就相當於我們數學中一個函式,輸入就相當於我
一個監督學習(極大似然分類)與非監督學習(K-means)的例子(matlab實現)
上遙感原理與應用的時候,老師給我們大致講了一下遙感影象的地物分類問題,大致瞭解了一下機器學習方法在遙感影像處理方面的應用問題。 下面將所做作業進行一個大致的總結: 資料 訓練集一共四種:building、road、vegetation、water,分別
機器學習系列之K-近鄰演算法(監督學習-分類問題)
''' @description : 演算法優點: a簡單、易於理解、易於實現、無需估計引數、無需訓練 演算法缺點: a懶惰演算法,對測試樣本分類時計算量大,記憶體開銷大 b必須制定k值,k值得選擇