
深度學習與文字分類總結
前面一段時間一直忙著參加知乎看山杯機器學習挑戰賽,現在比賽結束了想著總結一下最近的收穫。因為這是一個多標籤多類別的文字分類問題,而且題目非常適合用深度學習相關的知識去做,正好結合著這個競賽把之前一段時間的學習成果檢驗一下。接下來我會分成常用模型總結、多標籤/多類別專題、競賽實戰三部分進行介紹。
首先我們先來總結一下文字分類中常用的幾個深度學習模型,這裡可以參考brightsmart大神在github上面開源出來的程式碼,自己在做競賽的時候也進行了參考,收穫很大,下面我也會部分引用其程式碼來闡述。他給出了幾乎可以用於文字分類的所有基礎模型及相關程式碼實現(基於TensorFlow),是一份很棒的總結!接下來我們詳細的介紹一下每個模型的原理。
FastText
正好最近做商品分類的時候用到這個模型,瞭解了一下,是facebook在2016年提出來的模型,程式碼可以直接使用這裡的。這個模型其實算不上深度學習,他跟word2vec的模型極其相似,即輸入層是文字中的單詞,然後經過一個嵌入層將單詞轉化為詞向量,接下來對文字中所有的詞進行求平均的操作得到一個文字的向量,然後再經過一個輸出層對映到所有類別中,可以參考Bag of Tricks for Efficient Text Classification這篇論文,裡面還詳細論述瞭如何使用n-gram feature考慮單詞的順序關係,以及如何使用Hierarchical softmax機制加速softmax函式的計算速度。模型的原理圖如下所示:

- 這種模型的優點在於簡單,無論訓練還是預測的速度都很快,比其他深度學習模型高了幾個量級
- 缺點是模型過於簡單,準確度較低。(但是我聽說有人只用這個模型競賽裡就做到了0.4的準確度,很厲害)
這裡想說的是很多公司的實際場景裡面,他們的資料並不像我們平時跑實驗那麼完美,各種人工標註,資料量也很大等等,很多應用的資料量又小、又很雜亂、甚至還沒有標記==,所以那些深度學習的模型並不一定能派上很大的用場,反而這種簡單快速的模型用的很多。這裡也可以看一下其模型構建部分的程式碼,真的很簡單:

TextCNN
這個模型我們就不再贅述了,放張圖鎮樓。很經典想要了解的可以戳下面幾個連結:

TextRNN
這種模型與TextCNN很像,只不過是把上面的Conv+Pooling替換成了Bi-LSTM,最後將兩個方向上的輸出進行拼接再傳給輸出層即可。但是這種模型僅僅是對TextCNN應用到RNN上進行的一個小改動,效果並不是很好。因為RNN模型在訓練時速度很慢,所以並不推薦使用這種方法。
RCNN
這個模型是在Recurrent Convolutional Neural Network for Text Classification一文中提出的模型,架構如下圖所示: 
這種模型的想法是在word embedding的基礎上,求解每個單詞左邊和右邊上下文的表示,然後將三者融合在一起作為單詞的representation。在經過隱藏層、pooling層、輸出層得到文字的representation。採用了一種recurrent的方式替代CNN中的卷積層。這樣做的好處是,每個單詞最終的表示都不僅僅是一個單詞的表示這麼簡單,而是融合了其上下文資訊,可以更好地反映其含義,下面跟一個max-pooling層相當於取出對文字資訊貢獻較大的單詞及其組合,這樣我們就可以得到其分類。具體圖中的每個元素可以按照下面的公式計算:
cl和cr是上下文representation,等於前面一個詞的上下文表示與當前單詞的embedding分別乘以權重引數再組合起來。最終的單詞表示xi為cl、embed、cr三者的聯合。在接下來將其通過一層神經網路得到yi。



這種方法相比TextRNN而言,組合了單詞之間的上下文資訊,可以更好的得到文字中的長依賴關係。而且相比RNN來講,熟練速度更快,基本上可以與TextCNN達到相同的效果。也是一種十分優秀的文字分類模型。
Char CNN、Char RNN
這兩種模型都是從char級別開始進行文字分類的方法,在這之前我已經對兩種模型進行過分析和實現。可以參考我之前的幾篇文章進行了解,由於參賽的時間有限,所以在競賽過程中並未使用這兩種方法進行檢驗效果。原因是官方提供了詞向量和字元向量,但是據別的參賽選手反應使用字元向量效果普遍不好。而且官方給的語聊是經過脫敏處理的,並不適合使用char-cnn模型進行建模。
HAN
這是Hierarchical Attention Network for Document Classification論文中提出的模型,這部分內容可以參考我之前的兩篇文章,已經對模型和tf實現做了詳細的介紹:
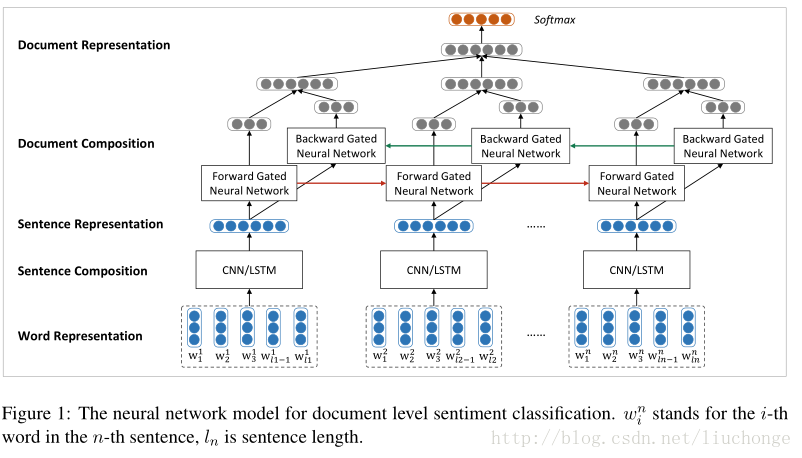
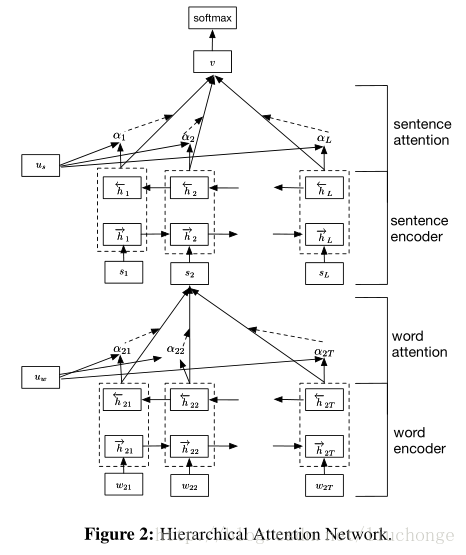
其基本思路就是將文字按層次分成單詞、句子、文字三層關係,然後分別用兩個Bi-LSTM模型去建模word-sentence、sentence-doc的模型。而且在每個模型中都引入了Attention機制來捕獲更長的依賴關係,從而得出不同詞/句子在構建句子/文字時的重要程度。這種模型相對來說效果在RNN模型中還是算不錯的,因為它綜合考慮了文字結構、詞句的重要性等因素。
Dynamic Memory Network
這個模型是“Ask Me Anything: Dynamic Memory Networks for Natural Language Processing”一文提出來的。他的思路是所有的NLP任務都可以歸為QA任務,也就是由輸入、問題、答案構成。所以DMN是構建了一個QA的模型,然後也可以用於分類、翻譯、序列資料等多重任務中。其模型主要有四部分組成:

這裡輸入是一段話,然後question相當於一種門控機制,會用Attention機制選擇性的將input中的資訊儲存在episodic memory當中。接下來episodic memory的輸出在經過answer模組產生問題的答案。具體的每個模組細節如下圖所示:

- 輸入模組的作用是將輸入的文字表示成向量,這裡採用RNN模型作為文字表示的模型。如果輸入是一句話就使用RNN的hidden state作為其representation,如果輸入是多句話,則在每句話後面新增識別符號,然後給每句話都生成一個representation,如圖中藍色的小條。
- question模組的作用是將question表示成向量,與輸入模組相似同樣使用RNN作為模型,將最終的hidden state作為輸出向量傳入episodic memory模組,作為其初始狀態。
- episodic memory模組通過迭代產生記憶。輸入模組產生的句子表示會根據question模組進行注意力機制的加權,按照問題針對性的選擇出相應的表示。記憶模組的兩條線分別代表帶著問題q第一次閱讀input的記憶,以及帶著問題q第二次閱讀的記憶。
- answer module是根據episodic memory的最後一個memory作為模型的初始狀態,這裡使用GRU進行建模。然後生成最終的答案
這部分的詳細介紹可以參考碼農場對這篇論文的筆記。
Entity Network
在看到brightmart的分享之前並未聽說過這個模型,後來查了一下,發現是2017年ICLR剛發的文章“Tracking the World State with Recurrent Entity Networks”,這些大牛們真的是緊跟業內最前沿==這篇論文等我之後有時間會專門去研究一下然後寫篇部落格來講,這裡先不說。放張模型的架構圖感受一下~~

Attention is all your need
這是谷歌今年剛發的論文,對標Facebook之前釋出的“Attention is all your need”。由於時間關係同樣還沒有仔細閱讀過,先寫在這佔個坑位吧,看之後什麼時候有時間實現一下。
總結
至此我們已經把主流的文字分類中會用到的深度學習模型說了個遍,從CNN到RNN,從seq2seq到Attention,我覺得這些模型各有優劣,在不同的任務上會有不同的表現效果。但是基本上來講如果追求簡單速度,可以使用fasttext,想要提升效果先可以試試textCNN和RCNN這兩種模型,在接下來可以試試HAN這類LSTM或者GRU的模型,剩下幾種也會有不錯的效果,可以根據自己的精力和專案要求判斷是否進行嘗試。因為有的並不是專門為了文字分類設計的,所以效果上可能更需要自己針對具體的任務進行調整。
但是其實深度學習裡面模型可能只是一部分,不同的模型肯定會取得不一樣的效果。但是更加重要的引數調整,因為按照具體的任務和資料不一樣,引數的選擇會給最終的效果帶來很大的差距。就單純地按照這次競賽來講,相同的單模型分數會在0.30-0.41範圍中波動,然而引數的選擇和調優卻是十分麻煩和困難的事情,所以很多人稱之為黑盒==是門學問,等之後競賽前排大神出了分享之後,我也會參考他們的經驗寫一下我對於這部分的理解。
上一篇部落格中我們已經總結了文字分類中常用的深度學習模型,因為知乎的本次競賽是多標籤的文字分類任務,這也是我第一次接觸多標籤分類,所以想單獨寫一篇部落格來記錄這方面的相關知識。
在這裡首先列出幾篇參考的文章:
-
基於神經網路的多標籤分類可以追溯到周志華在2006年發表的文章: Multi-Label Neural Networks with Applications to Functional Genomics and Text Categorization。其貢獻在於提出了BP-MLL(多標籤反向傳播)以及新的誤差函式:
-
然後是一篇基於周志華文章改進的論文:Large-scale Multi-label Text Classification Revisiting Neural Networks。這篇文章提出使用Adagrad,dropout等技術,此外還提出使用標準的交叉熵函式作為目標函式效果更好。
-
上面的文章還是使用普通的神經網路進行分類,接下來就出現了基於深度學習模型的方法。比如:Large Scale Multi-label Text Classification with Semantic Word Vectors。這篇文章很簡單,就是把TextCNN和GRU直接用到多標籤文字分類裡,最後根據一個閾值alpha來確定樣本是否屬於某個類別。
-
Improved Neural Network-based Multi-label Classification with Better Initialization Leveraging Label Co-occurrence。這篇文章提出了一種根據類別標籤之間的共現關係來初始化最後輸出層引數的方法。其也是基於TextCNN,不同之處是最後一個輸出層的權重不使用隨機初始化,而是根據標籤之間的共現關係進行初始化。據作者說這樣可以獲得標籤之間的關係,這樣有一種聚類的效果。相似的樣本會標記為相同的標籤。此外他還提出了損失函式的計算方法。具體的細節部分可以去看相關論文。
-
模型上的改進:Ensemble Application of Convolutional and Recurrent Neural Networks for Multi-label Text Categorization。這篇論文主要提出了一種CNN和RNN融合的機制,將CNN的輸出作為RNN的初始狀態然後進行類別的預測。架構圖如下所示:
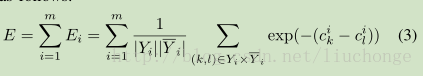



上面幾篇論文是我在做競賽的過程中閱讀的幾篇相關論文,每篇都會有一定的特點,但是實際的效果如何其實並不會像論文中提到的那樣,也有可能是自己調參跳的不好。但是論文裡面提到的創新點還是值得我們學習的。然後我們來總結一下多標籤文字分類相關的東西,這裡參考上面第三篇論文。首先來講,多標籤分類的演算法可以分成下面三種類型:
- multi-label classification:將標籤分成Y和Y的補集兩個分割槽
- label ranking:將標籤進行排序,排名靠前的就是預測為相關的類別
- multi-label ranking:上述二者的綜合,同時產生分割槽和rank。設定閾值函式進行判斷
此外,我們還可以使用Binary Relevance(BR)演算法,將多標籤問題轉化為L個二分類問題。訓練L個模型,每個模型處理一個類別,這樣做的好處是可以並行訓練L個模型,降低訓練複雜度,而且可以方便的增刪標籤數量。最終只需要把結果合併成一個輸出向量就可以了。但是也有一點的缺點,比如說由於分開訓練L個模型,所以忽視了標籤之間的相關性。而且噹噹資料集出現類別不均衡等現象時,效果也會變差。
上面說了幾種如何看待多標籤分類問題的思路和看法。其實就是將多標籤分類進行轉化。我感覺比較常用的應該是ranking和BR的方法。再反過來看這次知乎的競賽,其實我看了前幾名的解決方案,大都是隻用了深度學習模型的堆砌,比如說CNN,RNN然後再加上模型融合和資料增強的一些手段得到了比較好的分數。但是我之前也採訪過知乎機器學習團隊的負責人,他當時也明確的表明現在選手使用的方法還都是比較老派,沒有什麼十分大的創新點出來,而且幾乎沒怎麼利用標籤之間的關係等資訊。這裡我就說一下我在競賽裡面做過的幾種嘗試。
1,首先來分析一下知乎所提供的資料都有哪些特點,第一給了1999個標籤之間的父子關係,這樣我們就可以將其構成一張樹狀關係圖。
2,其次他給出了每個label的描述資訊,我覺得這個資訊是最重要的,因為這樣我們最簡單也可以計算樣本和1999個標籤之間的相似性然後排名取出前5個就可以粗略地進行類別標註。當然我們在結合深度學習的時候可以將其放在最後一層跟CNN的輸出進行結合計算。我當時採用的方法是,將樣本和1999個標籤的title分別經過CNN進行計算,然後再將得到的文字表示和標籤資訊進行一個相似性計算得到每個類別的相似性概率表示。但是這種方法的缺點在於速度太慢,我當時訓練了一天兩夜才跑了2個epoch(CPU),所以中途放棄了,至今也不知道效果如何==
3,使用上面第四篇文獻中所提出的方法,首先對資料進行預處理,得到所有訓練資料中所出現的標籤共現資訊,取共現次數最高的前N個標籤對作為初始化的依據。該模型的想法是通過這種自定義初始化網路權重的方法讓模型學習到這種標籤的共現資訊,從而更加準確地進行類別預測。
4,在查閱文獻的過程中,看到了一篇“Multi-Label Classification on Tree- and DAG-Structured Hierarchies”的論文,其提出將標籤資訊構建成有向無環圖或者樹狀的分層結構。但是該方法是基於傳統機器學習模型做的,由於競賽過程中時間有限,所以並未加以嘗試。此外,我還考慮是否可以將標籤資訊使用類似於word2vec中的分層softmax的機制進行處理。總之是儘量的把標籤之間的父子關係圖利用起來,以增強分類的準確度。這裡也不過是一些自己的想法罷了,還並未進行實踐,也希望有懂這方面知識的同學可以指點一二。
至此,關於多標籤文字分類相關的知識就暫時總結到這裡,其實也就是看的幾篇論文和知乎競賽中的一些思考。接下來抽時間把自己參加競賽的一些具體的程式碼等再整理出一篇部落格就將完結這個系列。