
自動網路搜尋(NAS)在語義分割上的應用(一)
【摘要】本文簡單介紹了NAS的發展現況和在語義分割中的應用,並且詳細解讀了兩篇流行的work:DARTS和Auto-DeepLab。
自動網路搜尋
多數神經網路結構都是基於一些成熟的backbone,如ResNet, MobileNet,稍作改進構建而成來完成不同任務。正因如此,深度神經網路總被詬病為black-box,因為hyparameter是基於實驗求得而並非通過嚴謹的數學推導。所以,很多DNN研究人員將大量時間花在修改模型和實驗“調參”上面,而忽略novelty本身。許多教授戲稱這種現象為“graduate student descent”。
近兩年,學術界興起了“自動網路搜尋”取代人工設計網路結構。2016年,Google Brain公開了他們的研究成果NASNet【1】,這是第一個用自動網路搜尋Neural Architecture Seach (NAS)完成的神經網路,為深度學習打開了新局面。NASNet是由一系列operation(如depth separable conv, max pooling等)疊加而成。至於怎樣選擇operation,作者用強化學習(RL)的方法,用一個controller網路隨機組合operations生成模組,通過評估選擇最優模組組成網路結構。Google提供的雲上服務Cloud AutoML正是基於NAS方法,根據使用者上傳的資料自動搜尋神經網路再將結果輸出。迄今為止,國內外很多工業界和學術界的AI Lab都有NAS相關工作:Google Brain提出了NasNet, MNasNet和Nas-FPN,Google提出MobileNetv3,Auto-DeepLab和Dense Prediction Cell(DPC);MIT Han Song團隊提出ProxylessNet;Facebook提出FbNet;Baidu提出SETN;騰訊提出FPNAS;小米提出FairNAS;京東AI提出CAS;華為諾亞有提出P-DARTS等。通過各大實驗室對NAS的研究成果,似乎可以看出自動網路搜尋將會成為趨勢。
接下來我們簡單介紹一下NAS的流程,詳細內容可參考【2】。NAS的架構主要包含三部分:搜尋空間Search Space,搜尋策略Search Strategy和評估機制Performance Estimation(如下圖)。
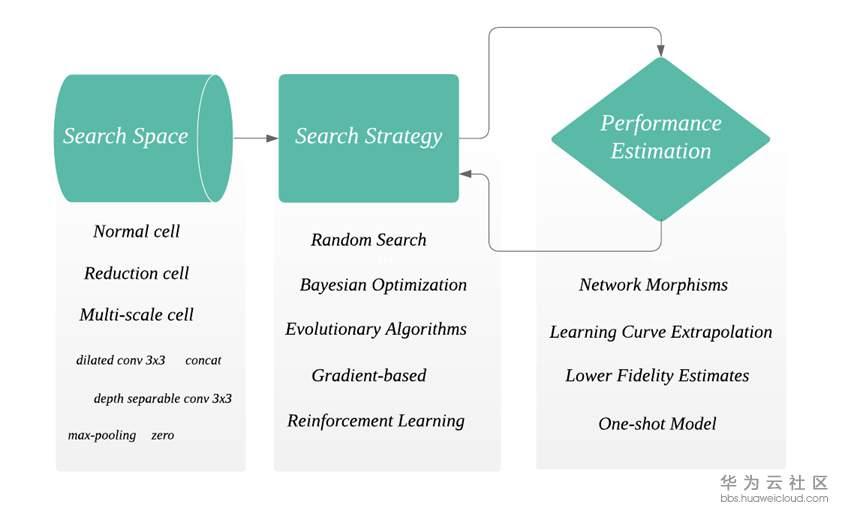
- 首先搜尋空間會定義一些模組(cell),operations(例如dilated conv 3x3),和巨集觀網路結構。cell是由若干個operation組合而成。通常來說,NAS會自動搜尋出一些可以重複的cell,將cell按照設定的巨集觀網路結構堆疊起來形成network。Zoph et al.提出了兩種cell,normal cell和reduction cell【3】。Reduction cell有改變spatial resolution的功能。這兩種cell在現有的演算法中最為常見。此外還有來自CAS網路【4】的multi-scale cell,作用和ASPP類似可用作decoder。至於對巨集觀網路結構的設定,早期的工作會採用chained-structured,或者帶分支結構multi-branch例如ResNet和DenseNet帶有skip和shortcut。
- 搜尋策略在NAS中至關重要,因為它決定了下一步要選擇哪一個cell或者operation組成網路結構。搜尋的目的就是讓現有的網路結構在unseen data上得到最好的效果。如前文提到,第一篇工作NASNet中用到了強化學習作為搜尋策略。雖然實驗結果尚可,但強化學習耗時過長並且需要大量GPU資源。NASNet就是用幾百個GPU搜尋了幾天才完成,這對於資源少的研究人員來說不可能完成。繼NASNet之後早期的工作多是基於RL完成搜尋。隨著其他方法的研究,如random search, Bayesian optimization, Gradient-based, evolution algorithms,搜尋時間在下降並且GPU使用量也在減少,使得NAS得以普及。感謝https://github.com/D-X-Y/Awesome-NAS 提供了搜尋策略的調研。
- 由於一個神經網路通常有幾十甚至上百層,結構也很複雜,一個及時並有效的反饋對於減少搜尋時間很有幫助。最簡單的方法是把訓練資料分成兩部分,train data用來訓練網路結構,validation data用來評估當前搜尋到的網路結構。一般來說,一個好的評估機制要兼具速度和準確度,舉個例子,train data少則網路結構訓練不到位,train data多則搜尋時間過長。來自Freiburg大學的Elsken團隊發表了關於NAS的調研,裡面對於評估方法講的很詳細,請挪步【2】。
自動網路搜尋在語義分割上的應用
相比於目標檢測,語義分割可以更好的解析影象,因為影象上的每一個pixel都會被分類。所以語義分割可以完成目標檢測無法完成的任務,如自動駕駛的全景分割,醫療影象診斷,衛星圖分割,背景摳圖和AR換裝等。過去的五年繼FCN之後,很多神經網路在公開資料集上都有不錯的成績。隨著AI產品落地,對神經網路效能的要求更為嚴格:在保證accuracy的前提下,在有限制的硬體資源執行並且提升inference速度。這為設計神經網路增加了很大難度。所以NAS是一個很好的選擇,它可以避免通過大量調參實驗來決定最優網路結構。在語義分割之前,NAS在影象分類和目標檢測上均有成功的應用。我們總結了近兩年比較流行的NAS在語義分割上的工作。多數的語義分割的網路都是encoder-decoder結構,在這裡我們對比了實際搜尋的部分,搜尋效能耗時和方法。由於每一個work都在不同實驗環境下進行,所以實驗結果沒有直接進行對比。
(1)第一篇將NAS應用於語義分割的工作來自Google DeepLab團隊,作者是Liang-Chieh Chen等一眾大佬。DeepLabv3+的準確度已經達到一定高度,繼而DeepLab團隊將研究方向轉移到了NAS上面。基於和DeepLab同樣的encoder-decoder結構, 在【5】工作中,作者將encoder結構固定,試圖搜尋出一個更小的 ASPP,用到的搜尋策略是random search。在Cityscapes達到82.7% mIoU,在PASCAL VOC 12上達到87.9%,結果尚可但搜尋時間過慢,用370個GPU搜尋一週才得到網路,這也限制了該方法的普及。
(2)同樣來自DeepLab團隊,Auto-DeepLab【6】相比之前的工作在搜尋效率上有顯著的提升。這都歸功於它gradient-based的搜尋策略DARTS【9】。與上一篇相反,Auto-DeepLab的目標是搜尋encoder,而decoder則採用ASPP。從實驗結果來看,Auto-DeepLab的準確度和DeepLabv3+相差不多,但是FLOPs和引數數量卻是DeepLabv3+的一半。後文我們會具體介紹DARTS和Auto-DeepLab。
(3)Customizable Architecture Search (CAS)【4】是來自京東AI Lab的工作。在搜尋空間定義了三種cell,分別是normal cell,reduction cell和新提出的multi-scale cell。其中multi-scale cell是ASPP 的功能類似,所以CAS的搜尋區間是針對全部網路。在搜尋策略上依然採用DARTS。值得一提的是,在搜尋網路的時候,CAS不僅考慮accuracy,還考慮了每個模組的GPU time,CPU time,FLOPs和引數數量。這些屬性對於實時任務至關重要。所以CAS在Cityscapes上的準確度是72.3%,雖然沒有很高,但是在TitanXP GPU的速度fps達到108。
(4)來自Adeleide大學的Vladimir Nekrasov團隊在light weight模型上面做了大量工作,而最近也將研究重心轉到了NAS上面。在【7】中,作者採用RL的搜尋策略搜尋decoder。眾所周知RL非常耗時,所以作者採用知識蒸餾策略和Polyak Averaging方法結合提升搜尋速度,而這正是本文的major contribution。
(5)最後一篇來自商湯釋出在Artix的文章,採用圖神經網路GCN作為搜尋策略,試圖尋找cell之間最優的連線方式【8】。和CAS類似,在本文中每個模組的效能如latency也在搜尋評估時考慮進去。在Cityscape上GAS達到73.3%mIoU,在TitanXP GPU的速度是102fps。
簡單總結一下上述工作,我們可以發現NAS在語義分割上的應用還算成功,並且很多團隊已經在NAS上進行研究探索。尤其在DARTS類似的高效搜尋策略提出後,個人研究者和小團隊也可以構建自己的NAS網路,而不受制於GPU資源。
DARTS: Differentiable Architecture Search
通常來說搜尋空間是一個離散的空間,在DARTS中【9】,作者將搜尋空間定義成一個連續空間,這樣一來搜尋到的每一個cell都是可導的,可以用stochastic gradient descent來優化。所以DARTS相比RL並不需要大量GPU資源和搜尋時間。在實驗中,DARTS成功用在了CNN模型的影象分類和RNN模型的language modelling任務上。感恩作者提供了原始碼 https://github.com/quark0/darts ,它可以為我們搭建自己NAS模型提供很好的基礎。
正如前文中提到,多數的NAS網路會搜尋不同型別的可重複的cell,然後將cell連線起來構成神經網路。這個cell通常用directed acyclic graph(DAG)表示。一個DAG cell包含N個有順序的node,每一個node可以看成在它前面所有node的結合(就像feature map一樣是一個latent representation)。從node i 到node j的連線是某一種operation記作o(i,j). 每一個cell都有兩個input node和一個output node。下圖中是一個DARTS展示的reduction cell。我們可以看到cell k 有兩個input nodes 分別是c_{k-1}和c_{k-2} (來自cell k-1和cell k-2的output node),cell k包含了4個immediate nodes和一個output node c_{k} 。o(i,j)是邊緣上的max_pool_3x3,max_pool等。理論上從一個node到相鄰的node可以有很多種operation,所以搜尋最優網路結構也可以看成是選擇每一個邊上最佳的operation。
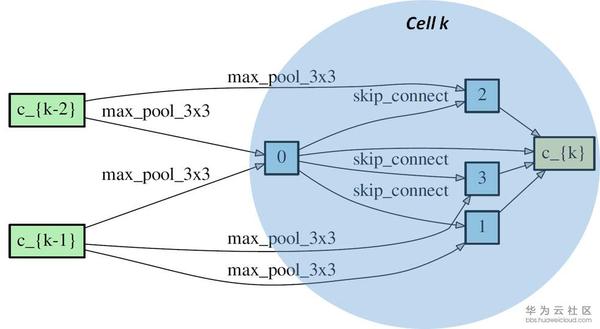
DARTS將每對node之間的每一個operation都賦予一個weight,最優解可以用softmax求得,也就是說有最大probability的path代表最優operation,這也是DARTS的核心部分。DARTS在搜尋空間中定義了兩種cell,reduction cell和normal cell。巨集觀網路結構是固定的,作者採用了簡單的chained-structured,將reduction cell放在了網路結構的1/3和2/3處。所以說在搜尋的過程中,cell內部不斷更新而巨集觀結構沒有變化。我們定義operation的引數為W,將cell中operation的weight記為Alpha。根據論文和source code,我們總結了DARTS的搜尋流程如下圖。
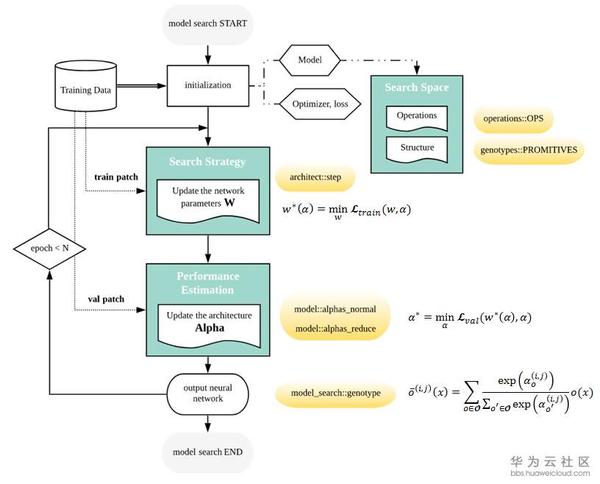
網路搜尋的第一步是對模型結構,optimizer,loss進行初始化。文中定義了幾種operation,程式碼中的定義在operation.OPS, 兩種cell在程式碼中的定義是genotypes.PROMITIVES. 引數Alpha在程式碼中定義為arch_parameters()={alphas.normal, alphas.reduce}. 在搜尋過程中,train data被分成兩部分,train patch用來訓練網路引數W而validation patch用來評估搜尋到的網路結構。在程式碼中,搜尋過程的核心部分在architect.step()。網路搜尋的目標函式就是讓validation在現有網路的loss最小,文章中公式(3)給出了objective:
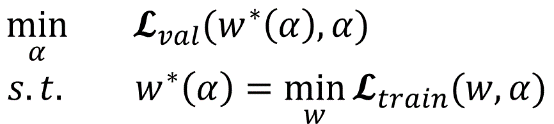
為了減少搜尋時間,每一輪只用一個training patch去更新引數W計算train loss。在計算Alpha的時候涉及到二階求導,稍微複雜一點,但是論文和程式碼都給了詳細解釋,這裡不贅述,程式碼中architect._hession_vector_product是求二階導的實現。在更新W和Alpha之後,最優operation通過softmax來計算。文中保留了top-k probability的operation。W和Alpha不斷計算更新直到搜尋過程結束。
文中進行了大量實驗,我們這裡只介紹一下在CIFAR-10資料上面進行的影象分類任務。作者將DARTS與傳統人工設計的網路DenseNet,和幾個其他常見的NAS網路進行對比,如AmoeNet和ENet都是常被提及的。DARTS在準確度上優於其他所有演算法,並且在搜尋速度上明顯比RL快很多。由於結構簡單效果好,而且不需要大量GPU和搜尋時間,DARTS已經被大量引用。
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
基於DARTS的結構,Google DeepLab團隊提出了Auto-DeepLab並發表在2019年CVPR上。在tensorflow deeplab官網上公佈了nas backbone並且給出了可以訓練的模型結構,但是搜尋過程並沒有公開。於是我們訓練了給出的nas網路結構,在沒有任何pre-training的情況下與deeplab v3+進行對比。程式碼參考 https://github.com/tensorflow/models/tree/master/research/deeplab 。
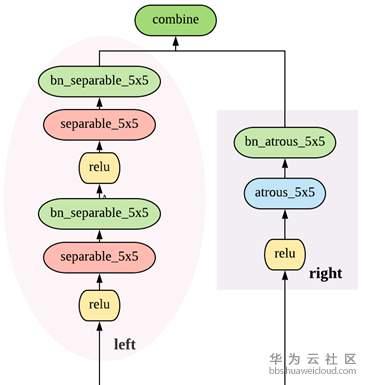
在DARTS中,巨集觀網路結構是提前定義的,而在Auto-DeepLab中巨集觀網路結構也是搜尋的一部分。繼承自DeepLab v3+的encoder-decoder結構,Auto-DeepLab的目的是搜尋Encoder代替現有的xception65,MobileNet等backbone,decoder採用ASPP。在搜尋空間中定義了reduction cell,normal cell和一些operation。Reduction cell用來改變spatial resolution,使其變大兩倍,或不變,或變小兩倍。為了保證feature map的精度,Auto-DeepLab規定最多downsampling 32倍 (s=32)。下圖定義了巨集觀網路結構(左)和cell內部的結構(右)。
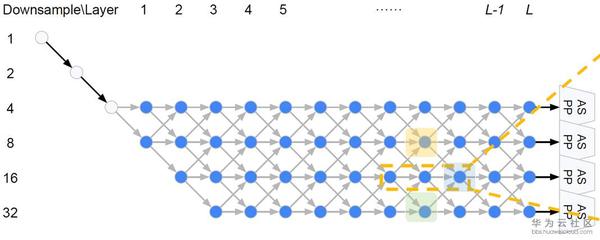
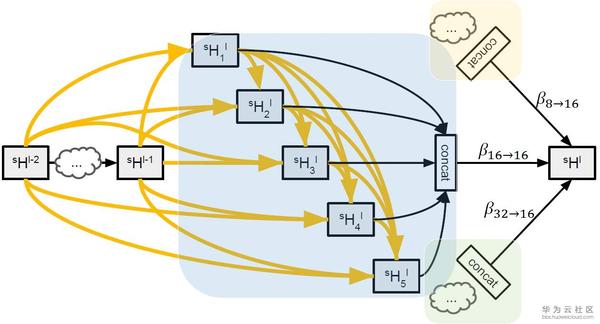
Auto-DeepLab定義了12個cell,而上圖(左)中前面兩個白色的node是固定的兩層為了縮小spatial resolution。如圖左灰色箭頭所示,正式搜尋之後,每一個cell的位置都有多種cell型別可以選擇:可以來自於當前cell相同的spatial resolution的cell,也可以是比當前cell的spatial resolution大一倍或小一倍的cell。作者將這些空間路徑(灰色箭頭表示的路徑)也賦予一個weight,記作Beta。如圖右,每一個cell的輸出都是由相鄰spatial resolution的cell結合而成,而Beta的值可以理解成不同路徑的probability。為了更直觀,我們把圖右的三個cell分別用藍色,黃色和綠色標註,對應圖左的三個cell。與DARTS類似,我們將operation的parameters記作W,將cell內部operation的權重記作Alpha。所以搜尋最優網路結構,即迭代計算並更新W,Alpha和Beta。文中給出每一個cell的實際輸出為:
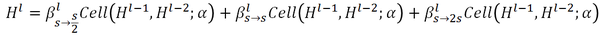
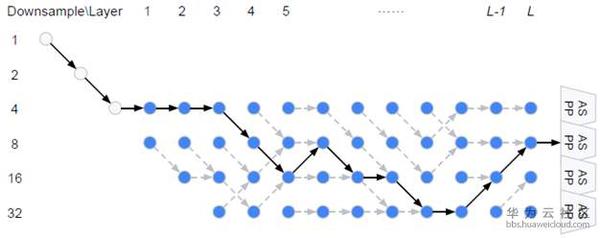
從上面公式可以看出,W和{Alpha,Beta}要分別計算和更新。所有的weight都是非負數。Alpha的計算方式依然是ArgMax,而計算Beta用了經典的貪心演算法Viterbi演算法。下圖給出的巨集觀網路結構是基於Cityscapes搜尋到的結果,對應程式碼中的backbone是[0,0,0,1,2,1,2,2,3,3,2,1], 數字代表downsample倍數。在模型中,每一個cell中的node由兩個路徑組成,如圖右。
文中用了三組開源資料PASCAL VOC 12, Cityscapes和ADE20k做了對比實驗。具體實驗引數設定和對比演算法在論文中有詳細說明,這裡只對比和Deeplab v3+。Cityscapes訓練資料尺寸是[769x769],而PASCAL VOC 12和ADE20k訓練資料尺寸是[513x513]。一般來說,Auto-DeepLab和DeepLabv3+準確度相差無幾,但是速度上要快2.33倍,並且Auto-DeepLab可以從零開始訓練。

除了文中給出的實驗結果以外,我們在PASCAL VOC 12資料上從零開始訓練了Auto-DeepLab,用程式碼中給出的模型結構,並且與DeepLabv3+(xception65)進行結果對比。但是並不是所有結果都能復現,分析原因大概是這樣:首先,上文中給出的模型結構是用Cityscapes資料集搜尋得到,也許在PASCAL VOC 12上並不是最優解;其次沒有用ImageNet做pre-training,訓練環境也不同。我們在下面表格中對比了FLOPs, 引數數量, 在K80 GPU上面的fps和mIoU。

下圖中直觀對比了ground truth(第二列),deeplabv3+(第三列)和Auto-DeepLab-S(第四列)的分割結果。與上面的mIoU一致,DeepLabv3+的分割結果要比Auto-DeepLab更精準一些,尤其是在邊緣。對於簡單的影象案例,兩者分割結果相差無幾,但是在較難的情況下,Auto-DeepLab會有很大誤差(在第三個案例中,Auto-DeepLab將女孩識別成狗)。

總結
本文簡單介紹了NAS的發展現況和在語義分割中的應用,並且詳細解讀了兩篇流行的work:DARTS和Auto-DeepLab。從整體實驗結果來看,還不能看出NAS的方法比傳統的模型有壓倒性優勢,尤其在準確度上。但是NAS給深度學習注入了新鮮的血液,為研究者提供了一種新的思路,並且還有很大的提升空間和待開發領域。也許人工設計網路結構將會被自動網路搜尋取代。
翻譯或有誤差,請參考原文https://medium.com/@majingting2014/neural-architecture-search-on-semantic-segmentation-1801ee48d6c4
對這塊比較關注的同學可以移步繼續閱讀《自動網路搜尋(NAS)在語義分割上的應用(二)》
References
[1] Zoph, Barret, and Quoc V. Le. "Neural architecture search with reinforcement learning." The International Conference on Learning Representations (ICLR) (2017)
[2] Elsken, Thomas, Jan Hendrik Metzen, and Frank Hutter. "Neural Architecture Search: A Survey." Journal of Machine Learning Research 20.55 (2019): 1-21.
[3] Zoph, Barret, et al. "Learning transferable architectures for scalable image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR). 2018.
[4] Zhang, Yiheng, et al. "Customizable Architecture Search for Semantic Segmentation." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2019.
[5] Chen, Liang-Chieh, et al. "Searching for efficient multi-scale architectures for dense image prediction." Advances in Neural Information Processing Systems (NIPS). 2018.
[6] Liu, Chenxi, et al. "Auto-deeplab: Hierarchical neural architecture search for semantic image segmentation." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2019.
[7] Nekrasov, Vladimir, et al. "Fast neural architecture search of compact semantic segmentation models via auxiliary cells." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2019.
[8] Lin, Peiwen, et al. "Graph-guided Architecture Search for Real-time Semantic Segmentation." arXiv preprint arXiv:1909.06793 (2019).
[9] Liu, Hanxiao, Karen Simonyan, and Yiming Yang. "Darts: Differentiable architecture search." The International Conference on Learning Representations (ICLR) (2019).
點選關注,第一時間瞭解華為雲新鮮技術~

相關推薦
自動網路搜尋(NAS)在語義分割上的應用(二)
前言: 本文將介紹如何基於ProxylessNAS搜尋semantic segmentation模型,最終搜尋得到的模型結構可在CPU上達到36 fps的測試結果,展示自動網路搜尋(NAS)在語義分割上的應用。 隨著自動網路搜尋(Neural Architecture Search)技術的
自動網路搜尋(NAS)在語義分割上的應用(一)
【摘要】本文簡單介紹了NAS的發展現況和在語義分割中的應用,並且詳細解讀了兩篇流行的work:DARTS和Auto-DeepLab。 自動網路搜尋 多數神經網路結構都是基於一些成熟的backbone,如ResNet, MobileNet,稍作改進構建而成來完成不同任務。正因如此,深度神經網路總被詬病為blac
影象語義分割文章彙總(附論文連結和公開程式碼)
吶,我也是做影象分割的啦,最近看到有大佬整理了影象分割方面最新的論文,覺得很有幫助,就轉載過來了,感覺又有很多要學的內容了。 Semantic Segmentation Adaptive Affinity Field for Sem
基於深度學習的影象語義分割演算法綜述(截止20180715)
這篇文章講述卷積神經網路在影象語義分割(semantic image segmentation)的應用。影象分割這項計算機視覺任務需要判定一張圖片中特定區域的所屬類別。 這個影象裡有什麼?它在影象中哪個位置? 更具體地說,影象語義分割的目標是將影象的每個畫素所
語義分割學習筆記(三)——SegNet Upsample層解析
1 引數設定 message UpsampleParameter { // DEPRECATED. No need to specify upsampling scale factors when // exact output shape is given by
語義分割演算法總結(一)
注: 在本文中經常會提到輸出資料的維度,為了防止讀者產生錯誤的理解,在本文的開頭做一下說明。 如上圖,原始影象大小為5*5,經過一次卷積後,影象變為3*3。那就是5*5的輸入,經過一個卷積層後,輸出的維度變為3*3,再經過一個卷積層,輸出的維度變為1*1
FCN語義分割訓練資料(以siftflow和voc2012資料集為例)
截至目前,現已經跑通了siftflow-fcn32s,voc-fcn32s,並製作好了自己的資料集,現在就等大批資料的到來,進而針對資料進行引數fine-tuning,現對我訓練的訓練流程和訓練過程中遇到的問題,做出總結和記錄,從而對以後的學習作鋪墊。 通過這篇分析語義分割
影象語義分割程式碼實現(1)
針對《影象語義分割(1)- FCN》介紹的FCN演算法,以官方的程式碼為基礎,在 SIFT-Flow 資料集上做訓練和測試。 介紹瞭如何製作自己的訓練資料 資料準備 1) 首先 clone 官方工程 git clone https://g
android 大檔案分割上傳(分塊上傳)
由於android自身的原因,對大檔案(如視訊檔案)的操作很容易造成OOM,即:Dalvik堆記憶體溢位,利用檔案分割將大檔案分割為小檔案可以解決問題。檔案分割後分多次請求服務。//檔案分割上傳 public void cutFileUpload(String
使用全卷積神經網路FCN,進行影象語義分割詳解(附程式碼實現)
一.導論 在影象語義分割領域,困擾了電腦科學家很多年的一個問題則是我們如何才能將我們感興趣的物件和不感興趣的物件分別分割開來呢?比如我們有一隻小貓的圖片,怎樣才能夠通過計算機自己對影象進行識別達到將小貓和圖片當中的背景互相分割開來的效果呢?如下圖所示: 而在2015年
分布式緩存技術redis學習系列(三)——redis高級應用(主從、事務與鎖、持久化)
master ica not ood www working can 出了 owin 上文《詳細講解redis數據結構(內存模型)以及常用命令》介紹了redis的數據類型以及常用命令,本文我們來學習下redis的一些高級特性。 回到頂部 安全性設置 設置客戶端操作秘密
重修課程day47(前端二之html二和css一)
100% 標簽 用戶 免費註冊 127.0.0.1 表單標簽 ges 愛好 order 一 列表標簽 ul標簽:無序列表 ol標簽:有序列表 li標簽:寫在ul和ol標簽裏面的 dl標簽:定義列表 dt標簽和dd標簽:都寫在dl裏面的 <!DOCTYP
從有狀態應用(Session)到無狀態應用(JWT),以及 SSO 和 OAuth2
從有狀態應用(Session)到無狀態應用(JWT),以及 SSO 和 OAuth2 不管用哪種方式認證使用者,都可能被中間人攻擊竊取 SessionID 或 Token,從而發生 CSRF 攻擊。解決方式就是全站 HTTPS。現在 Let’s Encrypt 已經支援免費的萬用字元 HTT
python例題(while、for迴圈的典型例題 一)
一、先了解一些python內部模組: 1、生成隨機數(隨機引數): (1)利用集合set可變的的性質轉化為隨機的列表。 set1 = {1
MTCNN演算法提速應用(ARM測試結果評估) MTCNN演算法提速應用(ARM測試結果評估)
原 MTCNN演算法提速應用(ARM測試結果評估) 置頂 2017年11月02日 10:48:05 samylee 閱讀數:11584
大資料學習筆記(Map Reduce在叢集上的執行架構)
MR1.X執行架構 JobTracter 核心,主,單點 排程所有的作業 監控整個叢集的資源負載 TaskTracter 從,自身節點資源管理 和JobTracter心跳,彙報資源,獲取Task Client 作業為單位 最終提交作業到JobTracker
Python父子關係——繼承(反恐精英案例,應用與練習)!
繼承描述的是一種類間關係,一個類A從另一個類B獲取成員資訊,稱類A繼承自類B。 提供成員資訊的類稱父類(基類),獲取成員資訊的類稱子類(派生類)。 1.2 繼承的作用 子類可以使用父類的成員(成員變數,成員方法) 1.3 繼承的語法格式 class 類名(父類名): pass
JavaWeb學習(十)Session的基本應用(1)
一、Session簡單介紹 在WEB開發中,伺服器可以為每個使用者瀏覽器建立一個會話(session物件),注意:一個瀏覽器獨佔一個session物件(預設情況下)。因此,在需要保護使用者資料時,伺服器程式可以把使用者資料寫到使用者瀏覽器獨佔的session中,當用戶使
NLP ---分詞詳解(常見的五種分詞技術一)
上一節我們簡單的介紹了分詞的起源,本節將介紹五種分詞效果比較好的分詞方法,他們都是基於統計的,分別為:N最短路徑法、基於詞的n元語法模型的分詞方法、由字夠詞的漢語分詞方法、基於詞感知機演算法的漢語分詞方法、基於字的生成模型和區分式模型相結合的漢語分詞方法。下面我們就一一的介紹他們: N最短路
Recsys2018 總結 (推薦系統最新技術、應用和方向)32篇論文解讀
本文對10月2-7號在加拿大渥太華舉辦的Recsys的32篇論文做了整理和歸納,總結出了目前推薦系統最新技術應用和方向。並對每一篇文章做了粗略的講解。 我打算從以下四個方面來講述這32篇論文。 首先呢,我會概述一下大會論文反映的一些情況。 然後分析一下