
神經網路優化(overfitting 解決辦法)
1:增大訓練集
2:early-stoping(http://deeplearning.net/tutorial/gettingstarted.html#early-stopping)
3:Regulization
4:Droppot
三:



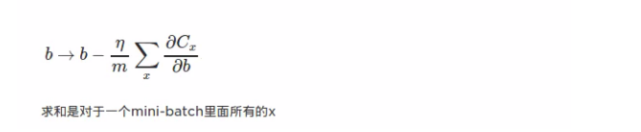



四:
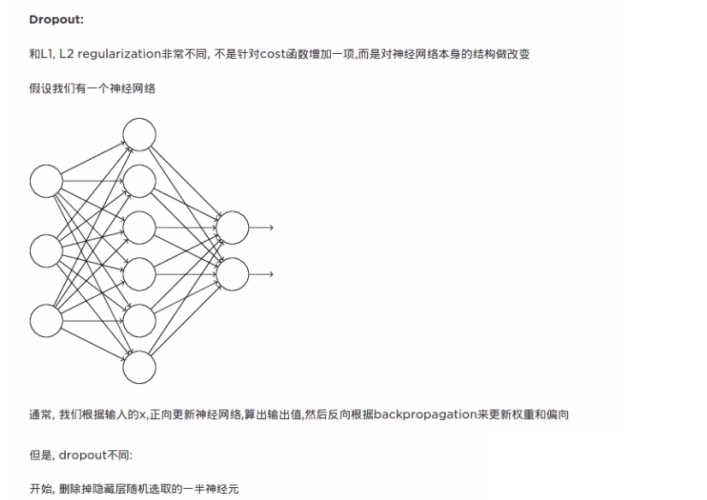
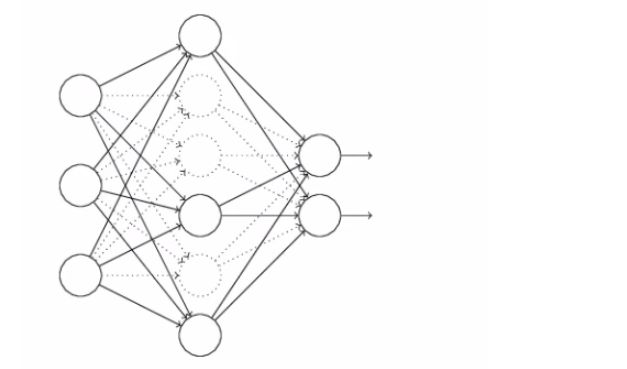

相關推薦
神經網路優化(overfitting 解決辦法)
1:增大訓練集 2:early-stoping(http://deeplearning.net/tutorial/gettingstarted.html#early-stopping) 3:Regul
神經網路優化(初始化權重)
使隱藏層飽和了, 跟之前我們說的輸出層飽和問題相似, 對於輸出層,我們用改進的cost函式,比如cross-entropy, 但是對
神經網路優化(二) - 滑動平均
1 滑動平均概述 滑動平均(也稱為 影子值 ):記錄了每一個引數一段時間內過往值的平均,增加了模型的泛化性。 滑動平均通常針對所有引數進行優化:W 和 b, 簡單地理解,滑動平均像是給引數加了一個影子,引數變化,影子緩慢追隨。 滑動平均的表示公式為 影子 = 衰減率 * 影子 + ( 1 - 衰減率
神經網路優化(二) - 搭建神經網路八股
為提高程式的可複用性,搭建模組化的神經網路八股 1 前向傳播 前向傳播就是設計、搭建從輸入(引數 x ) 到輸出(返回值為預測或分類結果 y )的完整網路結構,實現前向傳播過程,一般將其放在 forward.py 檔案中 前向傳播需要定義三個函式(實際上第一個函式是框架,第二、三個函式是賦初值過程)
機器學習與深度學習系列連載: 第二部分 深度學習(十五)迴圈神經網路 3(Gated RNN - GRU)
迴圈神經網路 3(Gated RNN - GRU) LSTM 是1997年就提出來的模型,為了簡化LSTM的複雜度,在2014年 Cho et al. 提出了 Gated Recurrent Units (GRU)。接下來,我們在LSTM的基礎上,介紹一下GRU。 主要思路是: •
機器學習與深度學習系列連載: 第二部分 深度學習(十四)迴圈神經網路 2(Gated RNN - LSTM )
迴圈神經網路 2(Gated RNN - LSTM ) simple RNN 具有梯度消失或者梯度爆炸的特點,所以,在實際應用中,帶有門限的RNN模型變種(Gated RNN)起著至關重要的作用,下面我們來進行介紹: LSTM (Long Short-term Memory )
VS2008 簡體中文正式版序列號(到期解決辦法)
1、VS2008簡體中文正式版序列號 1.Visual Studio 2008 Professional Edition: XMQ2Y-4T3V6-XJ48Y-D3K2V-6C4WT 2.Visual Studio 2008 Team Test Load
MATLAB神經網路工具箱(程式碼簡單實現)
根據網上搜素的關於MATLAB神經網路工具箱的GUI操作,結合書上的程式碼來跑了一遍,發現程式碼是引用了神經網路工具箱來做工作 %% 該程式碼為基於BP神經網路的預測算 %% 清空環境變數 clc clear %% 訓練資料預測資料提取及歸一化 %下載輸
《神經網路和深度學習》之神經網路基礎(第三週)課後作業——一個隱藏層的平面資料分類
由於沒有找到課後練習,所有練習文章均參考點選開啟連結,我已經將所有程式碼都實現過一遍了,沒有錯誤,感謝博主歡迎來到第三週的課程,在這一週的任務裡,你將建立一個只有一個隱含層的神經網路。相比於之前你實現的邏輯迴歸有很大的不同。你將會學習一下內容:用一個隱含層的神經網路實現一個二
機器學習演算法篇--卷積神經網路基礎(Convolutional Neural Network)
假設輸入影象為如圖 中右側的 5 × 5 矩陣,其對應的卷積核為一個 3 × 3 的矩陣。同時,假定卷積操作時每做一次卷積,卷積核移動一個畫素位置,即卷積步長 為1。第一次卷積操作從影象 (0, 0) 畫素開始,由卷積核中引數與對應位置影象像 素逐位相乘後累加作為一次卷積操作結果,即 1×1+2×0+3×1
Ubuntu14.04 Wifi 連線不穩定、掉線重連問題(終極解決辦法)
Ubuntu14.04 Wifi 連線不穩定、上不了網、掉線問題(終極解決辦法) 這可能是我寫的最短的一篇部落格。 用Ubuntu系統的人知道,有線連線比較穩定;一般桌上型電腦不帶網絡卡,自己某寶購買的無線網絡卡插上去後能連線wifi,但是過一分鐘就掉線了,
scikit-leran學習筆記(3)---神經網路模型(有監督的)
1.Multi-layer Perceptron 多層感知機 MLP是一個監督學習演算法,圖1是帶一個隱藏層的MLP模型 左邊層是輸入層,由神經元集合{xi|x1,x2,…,xm},代表輸入特徵,隱藏層的每個神經元將前一層的的值通過線性加權求
解決JSON返回的時間帶字元T的問題(前端解決辦法)
function showArticleList(id){ var myUrl = "../api/Articles"; $.ajax({ type: 'GET', url: myUrl, data: { page: iIndex,
卷積神經網路實戰(視覺化部分)——使用keras識別貓咪
更多深度文章,請關注雲端計算頻道:https://yq.aliyun.com/cloud 作者介紹:Erik Reppel,coinbase公司程式設計師 作者部落格:https://hackernoon.com/@erikreppel 作者twitter:http
機器學習:神經網路-多層前饋神經網路淺析(附程式碼實現)
M-P神經元模型神經網路中最基本的組成成分:神經元模型。如下圖是一個典型的“M-P神經元模型”:上圖中,神經元接收到n個其他神經元傳遞過來的輸入訊號,這些訊號通過權重的連線進行傳遞,神經元接收到的總輸入值與神經元的閾值進行比較,並通過“啟用函式”處理產生神經元輸出。常用S函式
Keras結合Keras後端搭建個性化神經網路模型(不用原生Tensorflow)
Keras是基於Tensorflow等底層張量處理庫的高階API庫。它幫我們實現了一系列經典的神經網路層(全連線層、卷積層、迴圈層等),以及簡潔的迭代模型的介面,讓我們能在模型層面寫程式碼,從而不用仔細考慮模型各層張量之間的資料流動。 但是,當我們有了全新的想法,想要個性化模型層的實現,Keras的高
誰擋了我的神經網路?(二)—— 優化演算法
誰擋了我的神經網路?(二)—— 優化演算法 這一系列文章介紹了在神經網路的設計和訓練過程中,可能提升網路效果的一些小技巧。前文介紹了在訓練過程中的一系列經驗,這篇文章將重點關注其中的優化演算法部分。更新於2018.11.1。 文章目錄 誰擋了我的神經網路?(
改善深層神經網路——優化演算法(6)
目錄 1.Mini-batch gradient descent 前我們介紹的神經網路訓練過程是對所有m個樣本,稱為batch,通過向量化計算方式,同時進行的。如果m很大,例如達到百萬數量級,訓練速度往往會很慢,因為每次迭代都要對所
神經網路優化演算法二(正則化、滑動平均模型)
1、神經網路進一步優化——過擬合與正則化 過擬合,指的是當一個模型過為複雜後,它可以很好的“記憶”每一個訓練資料中隨機噪音的部分而忘了要去“學習”訓練資料中通用的趨勢。舉一個極端的例子,如果一個模型中的引數比訓練資料的總數還多,那麼只要訓練資料不衝突,這個模型完全可以記住所有訓練資料
神經網路優化演算法一(梯度下降、學習率設定)
1、梯度下降法 梯度下降演算法主要用於優化單個引數的取值,而反向傳播演算法給出了一個高效的方式在所有的引數上使用梯度下降演算法,從而使得神經網路模型在訓練資料上的損失函式儘可能小。反向傳播演算法是訓練神經網路的核心演算法,它可以根據定義好的損失函式優化神經網路中引數的取值,從而使神經網路的模型在