
RNN啟用函式、Encoder-Decoder、Seq2Seq、Attention
RNN中為什麼使用使用tanh啟用,不用sigmoid、Relu
Sigmoid函式的導數範圍是(0,0.25], Tanh函式的導數是(0,1]。
由於RNN中會執行很多累乘,小於1的小數累乘會導致梯度越來越接近於0,出現梯度消失現象。
Tanh與Sigmoid相比,梯度更大,收斂速度更快並且出現梯度消失的情況要優於Sigmoid。
另一點是Sigmoid的輸出均大於0,不是零對稱的,這會導致偏移現象,因為每一層的輸入都是大於零的。 關於原點對稱的資料輸入,訓練效果更好。
RNN為什麼不用Relu?
這其實是一個偽命題,發明Relu函式的初衷就是為了克服Tanh函式在RNN中的梯度消失現象。
但是由於Relu的導數不是0就是1,恆為1的導數容易導致梯度爆炸,不過梯度爆炸不用慌,通過簡單的梯度截斷機制就可以得到優化。
Relu啟用函式是RNN中避免梯度消失現象的一個重要方法。
為什麼Relu用在RNN中會梯度爆炸,在普通CNN中不會?
Relu在RNN中會導致非常大的輸出值,由於每個神經元(設係數為w)的輸出都會作為輸入傳給下一個時刻本神經元,這就導致會對係數矩陣w執行累乘,如果w中由一個特徵值大於1,那麼非常不幸,若干次累乘之後數值就會很龐大,在前向傳播時候導致溢位,後向傳播導致梯度爆炸(當然可做截斷優化)。
而在CNN中,不存在係數矩陣w的累乘,每一層的係數w都是獨立的,互不相同,有大於1的,有小於1的,所以在很大程度上可以抵消,而不至於讓最終的數值很大。
Encoder-Decoder模型
首先需要強調Encoder和Decoder都是RNN(LSTM)模型,都有迴圈輸入(自己的輸出作為下次的輸入)。
Encoder部分的輸入是序列(一句話)經過word embedding(詞嵌入)方法處理過的詞向量表示和上一個時間點本Encoder輸出的結果, 輸出的是當前時間點的中間編碼c。
(word embedding詞嵌入是一種用低維向量表示高維向量的一種方式,可以保證在語義上相近的詞編碼後距離相近)
Decoder部分的輸入是 Encoder部分輸出的中間編碼和上一個時間點本Decoder輸出的預測結果(一句話)的word embedding詞向量。

(圖來自 知乎 盛源車)
上圖加了Attention,生成結果的時候會用到Encoder的隱層輸出,如果不加Attention,則結果完全依賴與Decoder的輸出(Decoder輸入是Encoder的輸出)
Encoder-Decoder模型中怎麼體現出前一個時間序列對後一個時間序列影響?
每一個時間點的序列經過Encoder編碼之後(加Attention或不加),再由Decoder解碼輸出序列結果,這個結果一方面作為“翻譯”輸出,一方面再作為輸入(經過word embedding詞嵌入表示),和下一個時間點的編碼序列一起,送給Decoder解碼翻譯,得到“翻譯”輸出。 以此體現了上一個時間點序列對下一個時間點序列的影響作用。
實際上,當前時間點的輸出,是當前輸入和之前所有時間點上的輸出共同作用的結果。
Seq2Seq
seq2seq 是一個Encoder–Decoder 結構的網路,它的輸入是一個序列,輸出也是一個序列, Encoder 中將一個可變長度的訊號序列變為固定長度的向量表達,Decoder 將這個固定長度的向量變成可變長度的目標的訊號序列。
Attention機制
傳統Encoder-Decoder結構中,Encoder把所有的輸入序列不管多長多短都編碼成一個固定長度的語義特徵c再解碼,這就導致了兩個問題,一是對長輸入序列而言的資訊丟失,二是丟失了序列原有的結構化資訊,忽略了序列資料之間的相互關係資訊,這兩者導致準確度降低。
那麼加入了Attention機制的Encoder-Decoder結構生成的語義向量c是定長的嗎?答案或許大概是定長的。
Attention機制的機制不是“針對不同長度的輸入得到不同長度的中間編碼”,而是讓Decoder的每一個時刻在輸出上所依賴的中間編碼c裡邊的元素的權重不同,即當前輸出(LSTM是時間依賴關係,下一個時刻的輸出受上一個時刻輸出的影響,所以生成如一句話時LSTM的輸出必然是從前到後,一個字(詞)一個字(詞)的生成的,這一點比較關鍵)更應該更多關注固定長度中間編碼c中的哪幾個元素。這樣就相當於LSTM的每一個時刻的解碼輸出的輸入的那個中間編碼c是不一樣的(c本身一樣,c中元素權重不一樣)。
Attention加入的位置
再看一下具有Attention結構的Encoder-Decoder模型總體結構:
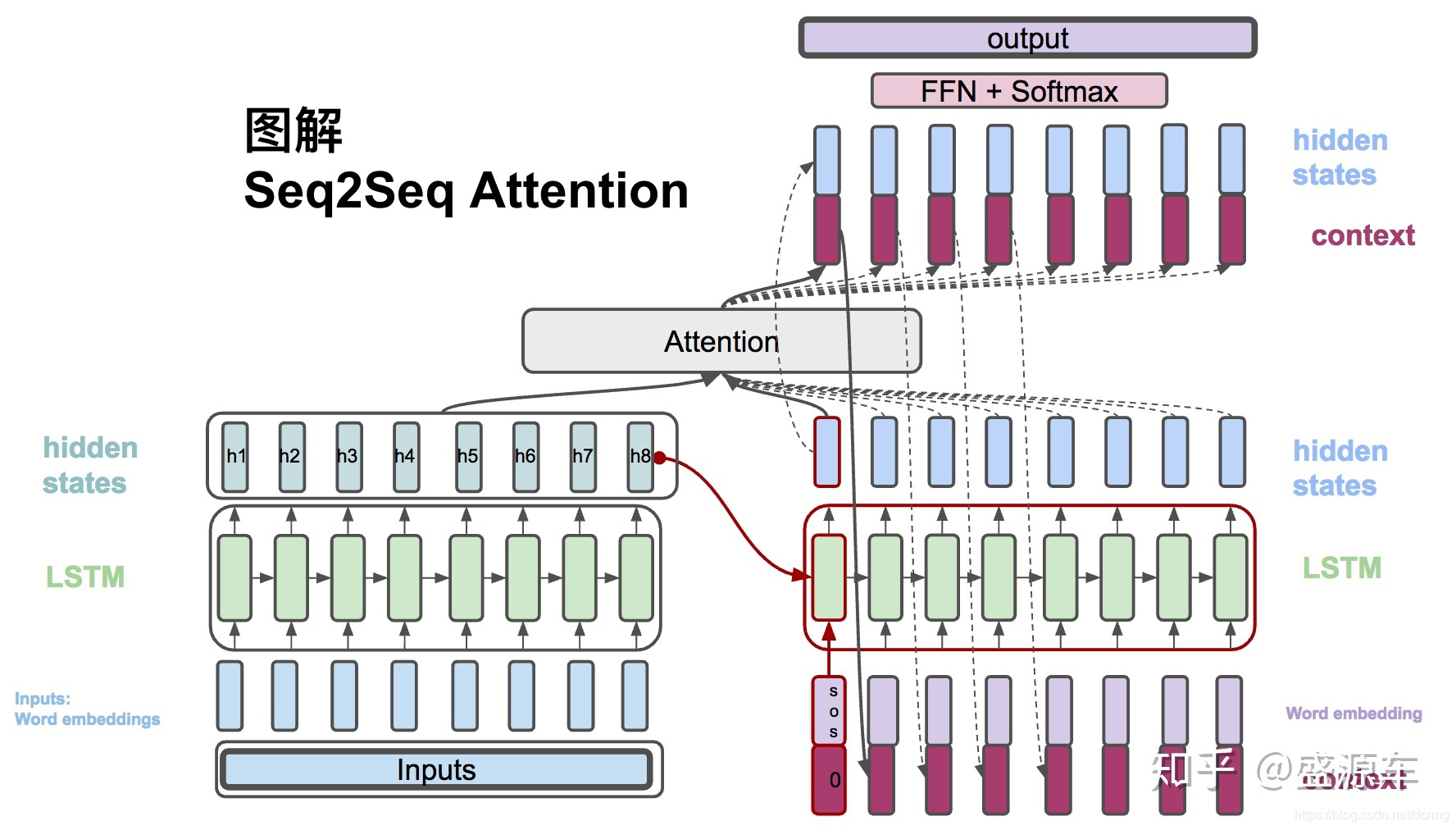
假設Decoder中有兩層的LSTM,則Attention加入的位置是在兩層LSTM隱層之間,Attention和第一層LSTM的輸出一起給到第二層SLTM。
所以Attention是加在Decoder的中間結果上的。
Attention具體操作
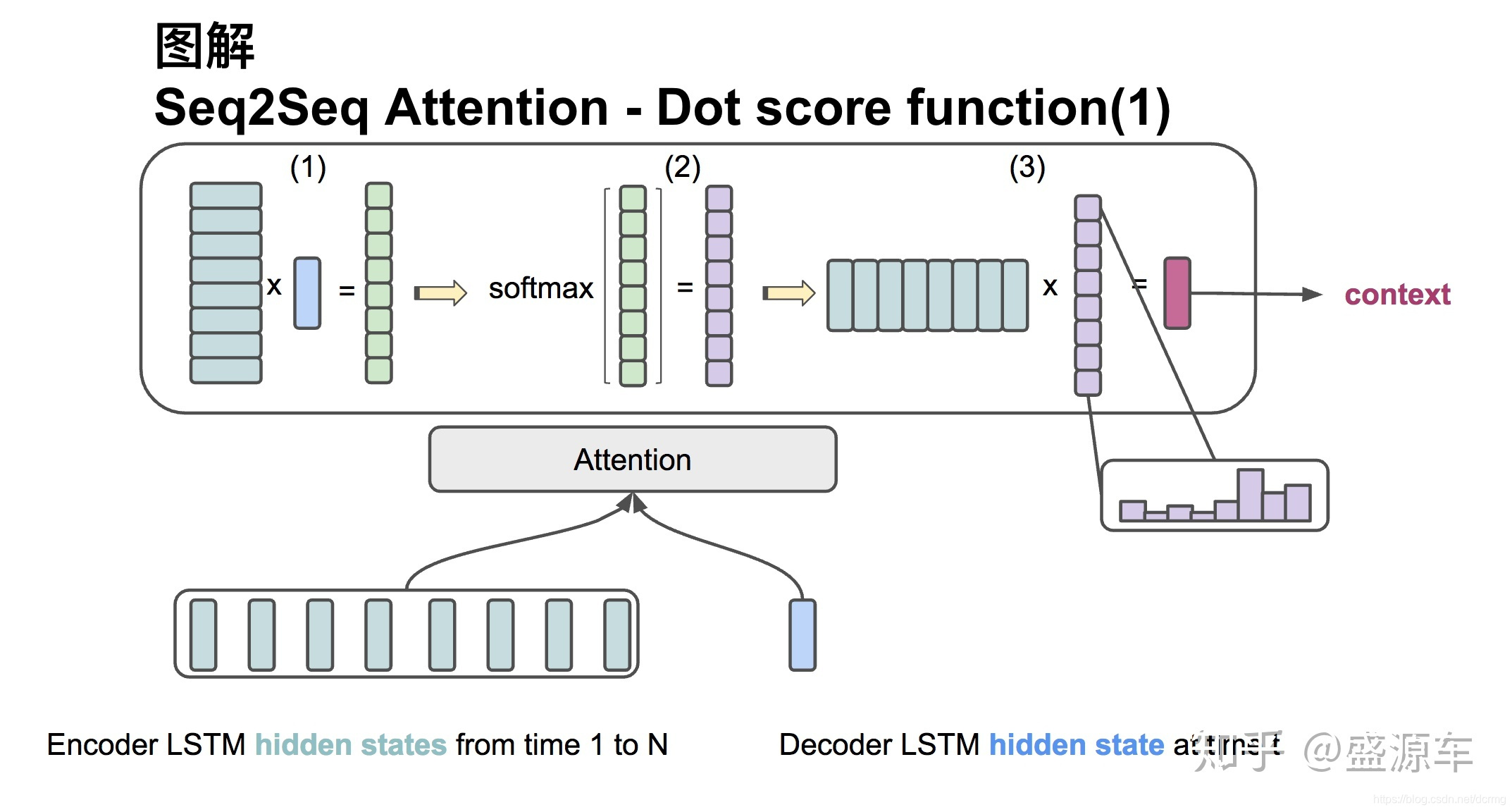
(圖來自 知乎 盛源車)
上圖中最下邊一排最右側的藍色方框是Decoder隱層中某一時刻的中間輸出。
具有不同權重的編碼序列c分別與Decoder隱層中第一個時刻到最後一個時刻的隱層輸出相乘,再經過一個softmax等操作再還原回來同等維度大小的隱層輸出。從前時刻到最後時刻依次執行。是每一個元素都和Attention相乘,而不是整體乘一次(前後關聯,有前輸出才有後邊的輸出,不可能一次輸出)。
Attention中對每個元素權重係數的確定
Attention如何確定中間編碼c中1~j個元素分別對於輸出序列Decoder隱藏層中1~i個元素的權重值aij?
在Attention模組中維護一個求權重值aij的函式,這個函式可以有不同的實現方法,它的輸出需要經過Softmax進行歸一化得到符合概率分佈取值區間的注意力分配概率分佈數值aij。
既然已經知道Attention中編碼序列c中哪個(幾個)元素對於解碼序列某一時刻來說最重要,為什麼不直接根據重要性直接輸出結果?
為了給網路一次改過自新的機會。 一是計算出來的“最重要”的結論不一定正確,二是編解碼需要兼顧整體上的表達,只關注最重要的有可能絕對翻譯是對的,但是語義上卻不通順。