
兩種常見的快取淘汰演算法LFU&LRU
1. LFU
1.1. 原理
LFU(Least Frequently Used)演算法根據資料的歷史訪問頻率來淘汰資料,其核心思想是“如果資料過去被訪問多次,那麼將來被訪問的頻率也更高”。
1.2. 實現
LFU的每個資料塊都有一個引用計數,所有資料塊按照引用計數排序,具有相同引用計數的資料塊則按照時間排序。
具體實現如下:
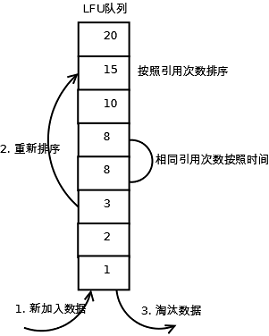
1. 新加入資料插入到佇列尾部(因為引用計數為1);
2. 佇列中的資料被訪問後,引用計數增加,佇列重新排序;
3. 當需要淘汰資料時,將已經排序的列表最後的資料塊刪除。
1.3. 分析
l 命中率
一般情況下,LFU效率要優於LRU,且能夠避免週期性或者偶發性的操作導致快取命中率下降的問題。但LFU需要記錄資料的歷史訪問記錄,一旦資料訪問模式改變,LFU需要更長時間來適用新的訪問模式,即:LFU存在歷史資料影響將來資料的“快取汙染
l 複雜度
需要維護一個佇列記錄所有資料的訪問記錄,每個資料都需要維護引用計數。
l 代價
需要記錄所有資料的訪問記錄,記憶體消耗較高;需要基於引用計數排序,效能消耗較高。
2. LRU
2.1. 原理
LRU(Least recently used,最近最少使用)演算法根據資料的歷史訪問記錄來進行淘汰資料,其核心思想是“如果資料最近被訪問過,那麼將來被訪問的機率也更高”。
2.2. 實現
最常見的實現是使用一個連結串列儲存快取資料,詳細演算法實現如下:
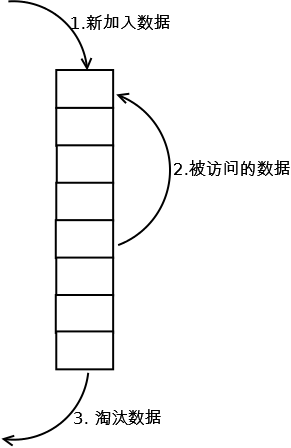
1. 新資料插入到連結串列頭部;
2. 每當快取命中(即快取資料被訪問),則將資料移到連結串列頭部;
3. 當連結串列滿的時候,將連結串列尾部的資料丟棄。
2.3. 分析
【命中率】
當存在熱點資料時,LRU的效率很好,但偶發性的、週期性的批量操作會導致LRU命中率急劇下降,快取汙染情況比較嚴重。
【複雜度】
實現簡單。
【代價】
命中時需要遍歷連結串列,找到命中的資料塊索引,然後需要將資料移到頭部。
3. LRU-K
3.1. 原理
LRU-K中的K代表最近使用的次數,因此LRU可以認為是LRU-1。LRU-K的主要目的是為了解決LRU演算法“快取汙染”的問題,其核心思想是將“最近使用過1次”的判斷標準擴充套件為“最近使用過K次”。
3.2. 實現
相比LRU,LRU-K需要多維護一個佇列,用於記錄所有快取資料被訪問的歷史。只有當資料的訪問次數達到K次的時候,才將資料放入快取。當需要淘汰資料時,LRU-K會淘汰第K次訪問時間距當前時間最大的資料。詳細實現如下:
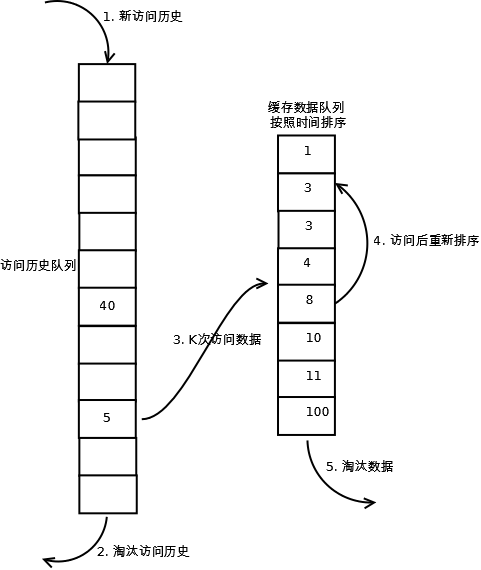
1. 資料第一次被訪問,加入到訪問歷史列表;
2. 如果資料在訪問歷史列表裡後沒有達到K次訪問,則按照一定規則(FIFO,LRU)淘汰;
3. 當訪問歷史佇列中的資料訪問次數達到K次後,將資料索引從歷史佇列刪除,將資料移到快取佇列中,並快取此資料,快取佇列重新按照時間排序;
4. 快取資料佇列中被再次訪問後,重新排序;
5. 需要淘汰資料時,淘汰快取佇列中排在末尾的資料,即:淘汰“倒數第K次訪問離現在最久”的資料。
LRU-K具有LRU的優點,同時能夠避免LRU的缺點,實際應用中LRU-2是綜合各種因素後最優的選擇,LRU-3或者更大的K值命中率會高,但適應性差,需要大量的資料訪問才能將歷史訪問記錄清除掉。
3.3. 分析
【命中率】
LRU-K降低了“快取汙染”帶來的問題,命中率比LRU要高。
【複雜度】
LRU-K佇列是一個優先順序佇列,演算法複雜度和代價比較高。
【代價】
由於LRU-K還需要記錄那些被訪問過、但還沒有放入快取的物件,因此記憶體消耗會比LRU要多;當資料量很大的時候,記憶體消耗會比較可觀。
LRU-K需要基於時間進行排序(可以需要淘汰時再排序,也可以即時排序),CPU消耗比LRU要高。