
快取淘汰演算法-LRU演算法
轉載自:http://flychao88.iteye.com/blog/1977653
1. LRU
1.1. 原理
LRU(Least recently used,最近最少使用)演算法根據資料的歷史訪問記錄來進行淘汰資料,其核心思想是“如果資料最近被訪問過,那麼將來被訪問的機率也更高”。
1.2. 實現
最常見的實現是使用一個連結串列儲存快取資料,詳細演算法實現如下:
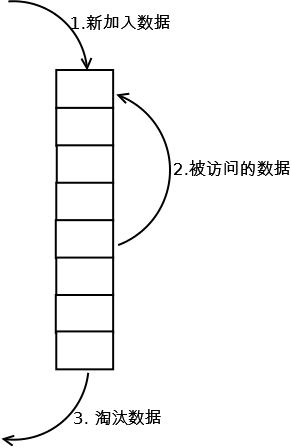
1. 新資料插入到連結串列頭部;
2. 每當快取命中(即快取資料被訪問),則將資料移到連結串列頭部;
3. 當連結串列滿的時候,將連結串列尾部的資料丟棄。
1.3. 分析
【命中率】
當存在熱點資料時,LRU的效率很好,但偶發性的、週期性的批量操作會導致LRU命中率急劇下降,快取汙染情況比較嚴重。
【複雜度】
實現簡單。
【代價】
命中時需要遍歷連結串列,找到命中的資料塊索引,然後需要將資料移到頭部。
2. LRU-K
2.1. 原理
LRU-K中的K代表最近使用的次數,因此LRU可以認為是LRU-1。LRU-K的主要目的是為了解決LRU演算法“快取汙染”的問題,其核心思想是將“最近使用過1次”的判斷標準擴充套件為“最近使用過K次”。
2.2. 實現
相比LRU,LRU-K需要多維護一個佇列,用於記錄所有快取資料被訪問的歷史。只有當資料的訪問次數達到K次的時候,才將資料放入快取。當需要淘汰資料時,LRU-K會淘汰第K次訪問時間距當前時間最大的資料。詳細實現如下:
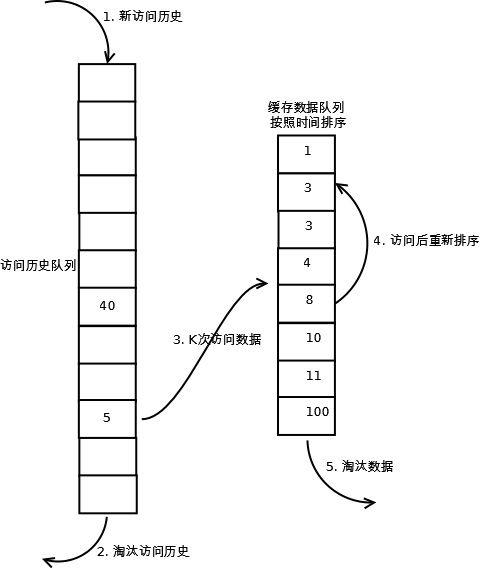
1. 資料第一次被訪問,加入到訪問歷史列表;
2. 如果資料在訪問歷史列表裡後沒有達到K次訪問,則按照一定規則(FIFO,LRU)淘汰;
3. 當訪問歷史佇列中的資料訪問次數達到K次後,將資料索引從歷史佇列刪除,將資料移到快取佇列中,並快取此資料,快取佇列重新按照時間排序;
4. 快取資料佇列中被再次訪問後,重新排序;
5. 需要淘汰資料時,淘汰快取佇列中排在末尾的資料,即:淘汰“倒數第K次訪問離現在最久”的資料。
LRU-K具有LRU的優點,同時能夠避免LRU的缺點,實際應用中LRU-2是綜合各種因素後最優的選擇,LRU-3或者更大的K值命中率會高,但適應性差,需要大量的資料訪問才能將歷史訪問記錄清除掉。
2.3. 分析
【命中率】
LRU-K降低了“快取汙染”帶來的問題,命中率比LRU要高。
【複雜度】
LRU-K佇列是一個優先順序佇列,演算法複雜度和代價比較高。
【代價】
由於LRU-K還需要記錄那些被訪問過、但還沒有放入快取的物件,因此記憶體消耗會比LRU要多;當資料量很大的時候,記憶體消耗會比較可觀。
LRU-K需要基於時間進行排序(可以需要淘汰時再排序,也可以即時排序),CPU消耗比LRU要高。
3. Two queues(2Q)
3.1. 原理
Two queues(以下使用2Q代替)演算法類似於LRU-2,不同點在於2Q將LRU-2演算法中的訪問歷史佇列(注意這不是快取資料的)改為一個FIFO快取佇列,即:2Q演算法有兩個快取佇列,一個是FIFO佇列,一個是LRU佇列。
3.2. 實現
當資料第一次訪問時,2Q演算法將資料快取在FIFO佇列裡面,當資料第二次被訪問時,則將資料從FIFO佇列移到LRU佇列裡面,兩個佇列各自按照自己的方法淘汰資料。詳細實現如下:
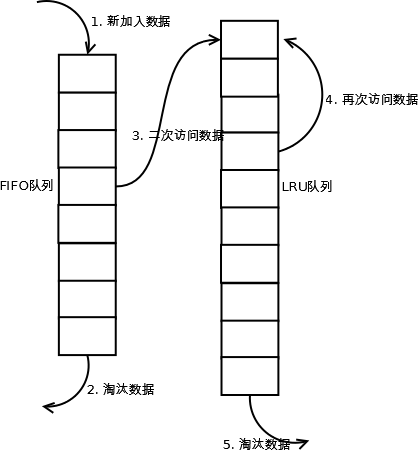
1. 新訪問的資料插入到FIFO佇列;
2. 如果資料在FIFO佇列中一直沒有被再次訪問,則最終按照FIFO規則淘汰;
3. 如果資料在FIFO佇列中被再次訪問,則將資料移到LRU佇列頭部;
4. 如果資料在LRU佇列再次被訪問,則將資料移到LRU佇列頭部;
5. LRU佇列淘汰末尾的資料。
注:上圖中FIFO佇列比LRU佇列短,但並不代表這是演算法要求,實際應用中兩者比例沒有硬性規定。
3.3. 分析
【命中率】
2Q演算法的命中率要高於LRU。
【複雜度】
需要兩個佇列,但兩個佇列本身都比較簡單。
【代價】
FIFO和LRU的代價之和。
2Q演算法和LRU-2演算法命中率類似,記憶體消耗也比較接近,但對於最後快取的資料來說,2Q會減少一次從原始儲存讀取資料或者計算資料的操作。
4. Multi Queue(MQ)
4.1. 原理
MQ演算法根據訪問頻率將資料劃分為多個佇列,不同的佇列具有不同的訪問優先順序,其核心思想是:優先快取訪問次數多的資料。
4.2. 實現
MQ演算法將快取劃分為多個LRU佇列,每個佇列對應不同的訪問優先順序。訪問優先順序是根據訪問次數計算出來的,例如
詳細的演算法結構圖如下,Q0,Q1....Qk代表不同的優先順序佇列,Q-history代表從快取中淘汰資料,但記錄了資料的索引和引用次數的佇列:

如上圖,演算法詳細描述如下:
1. 新插入的資料放入Q0;
2. 每個佇列按照LRU管理資料;
3. 當資料的訪問次數達到一定次數,需要提升優先順序時,將資料從當前佇列刪除,加入到高一級佇列的頭部;
4. 為了防止高優先順序資料永遠不被淘汰,當資料在指定的時間裡訪問沒有被訪問時,需要降低優先順序,將資料從當前佇列刪除,加入到低一級的佇列頭部;
5. 需要淘汰資料時,從最低一級佇列開始按照LRU淘汰;每個佇列淘汰資料時,將資料從快取中刪除,將資料索引加入Q-history頭部;
6. 如果資料在Q-history中被重新訪問,則重新計算其優先順序,移到目標佇列的頭部;
7. Q-history按照LRU淘汰資料的索引。
4.3. 分析
【命中率】
MQ降低了“快取汙染”帶來的問題,命中率比LRU要高。
【複雜度】
MQ需要維護多個佇列,且需要維護每個資料的訪問時間,複雜度比LRU高。
【代價】
MQ需要記錄每個資料的訪問時間,需要定時掃描所有佇列,代價比LRU要高。
注:雖然MQ的佇列看起來數量比較多,但由於所有佇列之和受限於快取容量的大小,因此這裡多個佇列長度之和和一個LRU佇列是一樣的,因此佇列掃描效能也相近。
5. LRU類演算法對比
由於不同的訪問模型導致命中率變化較大,此處對比僅基於理論定性分析,不做定量分析。
|
對比點 |
對比 |
|
命中率 |
LRU-2 > MQ(2) > 2Q > LRU |
|
複雜度 |
LRU-2 > MQ(2) > 2Q > LRU |
|
代價 |
LRU-2 > MQ(2) > 2Q > LRU |
實際應用中需要根據業務的需求和對資料的訪問情況進行選擇,並不是命中率越高越好。例如:雖然LRU看起來命中率會低一些,且存在”快取汙染“的問題,但由於其簡單和代價小,實際應用中反而應用更多。
java中最簡單的LRU演算法實現,就是利用jdk的LinkedHashMap,覆寫其中的removeEldestEntry(Map.Entry)方法即可
如果你去看LinkedHashMap的原始碼可知,LRU演算法是通過雙向連結串列來實現,當某個位置被命中,通過調整連結串列的指向將該位置調整到頭位置,新加入的內容直接放在連結串列頭,如此一來,最近被命中的內容就向連結串列頭移動,需要替換時,連結串列最後的位置就是最近最少使用的位置。import java.util.ArrayList;
import java.util.Collection;
import java.util.LinkedHashMap;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
import java.util.Map;
/**
* 類說明:利用LinkedHashMap實現簡單的快取, 必須實現removeEldestEntry方法,具體參見JDK文件
*
* @author dennis
*
* @param <K>
* @param <V>
*/
public class LRULinkedHashMap<K, V> extends LinkedHashMap<K, V> {
private final int maxCapacity;
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
private final Lock lock = new ReentrantLock();
public LRULinkedHashMap(int maxCapacity) {
super(maxCapacity, DEFAULT_LOAD_FACTOR, true);
this.maxCapacity = maxCapacity;
}
@Override
protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) {
return size() > maxCapacity;
}
@Override
public boolean containsKey(Object key) {
try {
lock.lock();
return super.containsKey(key);
} finally {
lock.unlock();
}
}
@Override
public V get(Object key) {
try {
lock.lock();
return super.get(key);
} finally {
lock.unlock();
}
}
@Override
public V put(K key, V value) {
try {
lock.lock();
return super.put(key, value);
} finally {
lock.unlock();
}
}
public int size() {
try {
lock.lock();
return super.size();
} finally {
lock.unlock();
}
}
public void clear() {
try {
lock.lock();
super.clear();
} finally {
lock.unlock();
}
}
public Collection<Map.Entry<K, V>> getAll() {
try {
lock.lock();
return new ArrayList<Map.Entry<K, V>>(super.entrySet());
} finally {
lock.unlock();
}
}
} 基於雙鏈表 的LRU實現:
傳統意義的LRU演算法是為每一個Cache物件設定一個計數器,每次Cache命中則給計數器+1,而Cache用完,需要淘汰舊內容,放置新內容時,就檢視所有的計數器,並將最少使用的內容替換掉。
它的弊端很明顯,如果Cache的數量少,問題不會很大, 但是如果Cache的空間過大,達到10W或者100W以上,一旦需要淘汰,則需要遍歷所有計算器,其效能與資源消耗是巨大的。效率也就非常的慢了。
它的原理: 將Cache的所有位置都用雙連表連線起來,當一個位置被命中之後,就將通過調整連結串列的指向,將該位置調整到連結串列頭的位置,新加入的Cache直接加到連結串列頭中。
這樣,在多次進行Cache操作後,最近被命中的,就會被向連結串列頭方向移動,而沒有命中的,而想連結串列後面移動,連結串列尾則表示最近最少使用的Cache。
當需要替換內容時候,連結串列的最後位置就是最少被命中的位置,我們只需要淘汰連結串列最後的部分即可。
上面說了這麼多的理論, 下面用程式碼來實現一個LRU策略的快取。
我們用一個物件來表示Cache,並實現雙鏈表,
Java程式碼- public class LRUCache {
- /**
- * 連結串列節點
- * @author Administrator
- *
- */
- class CacheNode {
- ……
- }
- private int cacheSize;//快取大小
- private Hashtable nodes;//快取容器
- private int currentSize;//當前快取物件數量
- private CacheNode first;//(實現雙鏈表)連結串列頭
- private CacheNode last;//(實現雙鏈表)連結串列尾
- }
下面給出完整的實現,這個類也被Tomcat所使用( org.apache.tomcat.util.collections.LRUCache),但是在tomcat6.x版本中,已經被棄用,使用另外其他的快取類來替代它。
Java程式碼- public class LRUCache {
- /**
- * 連結串列節點
- * @author Administrator
- *
- */
- class CacheNode {
- CacheNode prev;//前一節點
- CacheNode next;//後一節點
- Object value;//值
- Object key;//鍵
- CacheNode() {
- }
- }
- public LRUCache(int i) {
- currentSize = 0;
- cacheSize = i;
- nodes = new Hashtable(i);//快取容器
- }
- /**
- * 獲取快取中物件
- * @param key
- * @return
- */
- public Object get(Object key) {
- CacheNode node = (CacheNode) nodes.get(key);
- if (node != null) {
- moveToHead(node);
- return node.value;
- } else {
- return null;
- }
- }
- /**
- * 新增快取
- * @param key
- * @param value
- */
- public void put(Object key, Object value) {
- CacheNode node = (CacheNode) nodes.get(key);
- if (node == null) {
- //快取容器是否已經超過大小.
- if (currentSize >= cacheSize) {
- if (last != null)//將最少使用的刪除
- nodes.remove(last.key);
- removeLast();
- } else {
- currentSize++;
- }
- node = new CacheNode();
- }
- node.value = value;
- node.key = key;
- //將最新使用的節點放到連結串列頭,表示最新使用的.
- moveToHead(node);
- nodes.put(key, node);
- }
- /**
- * 將快取刪除
- * @param key
- * @return
- */
- public Object remove(Object key) {
- CacheNode node = (CacheNode) nodes.get(key);
- if (node != null) {
- if (node.prev != null) {
- node.prev.next = node.next;
- }
- if (node.next != null) {
- node.next.prev = node.prev;
- }
- if (last == node)
- last = node.prev;
- if (first == node)
- first = node.next;
- }
- return node;
- }
- public void clear() {
- first = null;
- last = null;
- }
- /**
- * 刪除連結串列尾部節點
- * 表示 刪除最少使用的快取物件
- */
- private void removeLast() {
- //連結串列尾不為空,則將連結串列尾指向null. 刪除連表尾(刪除最少使用的快取物件)
- if (last != null) {
- if (last.prev != null)
- last.prev.next = null;
- else
- first = null;
- last = last.prev;
- }
- }
- /**
- * 移動到連結串列頭,表示這個節點是最新使用過的
- * @param node
- */
- private void moveToHead(CacheNode node) {
- if (node == first)
- return;
- if (node.prev != null)
- node.prev.next = node.next;
- if (node.next != null)
- node.next.prev = node.prev;
- if (last == node)
- last = node.prev;
- if (first != null) {
- node.next = first;
- first.prev = node;
- }
- first = node;
- node.prev = null;
- if (last == null)
- last = first;
- }
- private int cacheSize;
- private Hashtable nodes;//快取容器
- private int currentSize;
- private CacheNode first;//連結串列頭
- private CacheNode last;//連結串列尾
- }
C實現參照:https://www.cnblogs.com/python27/p/LRUCache.html
/**
* LRU Cache Implementation using DoubleLinkList & hashtable
* Copyright 2015 python27
* 2015/06/26
*/
#include <iostream>
#include <string>
#include <map>
#include <list>
#include <deque>
#include <cassert>
#include <cstdio>
#include <cstdlib>
using namespace std;
struct CacheNode
{
int key;
int value;
CacheNode* prev;
CacheNode* next;
CacheNode(int k, int v) : key(k), value(v), prev(NULL), next(NULL)
{}
CacheNode():key(0), value(0), prev(NULL), next(NULL)
{}
};
class LRUCache
{
public:
LRUCache(int capacity);
int Get(int key);
void Put(int key, int value);
public:
void PrintList() const;
private:
void InsertNodeFront(CacheNode* p);
void DeleteNode(CacheNode* p);
private:
map<int, CacheNode*> m_hashtable; // hash table
CacheNode* m_head; // double link list head
CacheNode* m_tail; // double link list tail
int m_capacity; // capacity of link list
int m_size; // current size of link list
};
void LRUCache::PrintList() const
{
CacheNode* p = m_head;
for (p = m_head; p != NULL; p = p->next)
{
printf("(%d, %d)->", p->key, p->value);
}
printf("\n");
printf("size = %d\n", m_size);
printf("capacity = %d\n", m_capacity);
}
LRUCache::LRUCache(int capacity)
{
m_capacity = capacity;
m_size = 0;
m_head = NULL;
m_tail = NULL;
}
// insert node into head pointed by p
void LRUCache::InsertNodeFront(CacheNode* p)
{
if (p == NULL) return;
if (m_head == NULL)
{
m_head = p;
m_tail = p;