
快取淘汰演算法之LRU
1. LRU
1.1. 原理
LRU(Least recently used,最近最少使用)演算法根據資料的歷史訪問記錄來進行淘汰資料,其核心思想是“如果資料最近被訪問過,那麼將來被訪問的機率也更高”。
1.2. 實現
最常見的實現是使用一個連結串列儲存快取資料,詳細演算法實現如下:
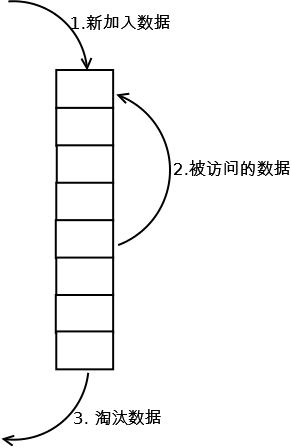
1. 新資料插入到連結串列頭部;
2. 每當快取命中(即快取資料被訪問),則將資料移到連結串列頭部;
3. 當連結串列滿的時候,將連結串列尾部的資料丟棄。
1.3. 分析
【命中率】
當存在熱點資料時,LRU的效率很好,但偶發性的、週期性的批量操作會導致LRU命中率急劇下降,快取汙染情況比較嚴重。
【複雜度】
實現簡單。
【代價】
命中時需要遍歷連結串列,找到命中的資料塊索引,然後需要將資料移到頭部。
2. LRU-K
2.1. 原理
LRU-K中的K代表最近使用的次數,因此LRU可以認為是LRU-1。LRU-K的主要目的是為了解決LRU演算法“快取汙染”的問題,其核心思想是將“最近使用過1次”的判斷標準擴充套件為“最近使用過K次”。
2.2. 實現
相比LRU,LRU-K需要多維護一個佇列,用於記錄所有快取資料被訪問的歷史。只有當資料的訪問次數達到K次的時候,才將資料放入快取。當需要淘汰資料時,LRU-K會淘汰第K次訪問時間距當前時間最大的資料。詳細實現如下:
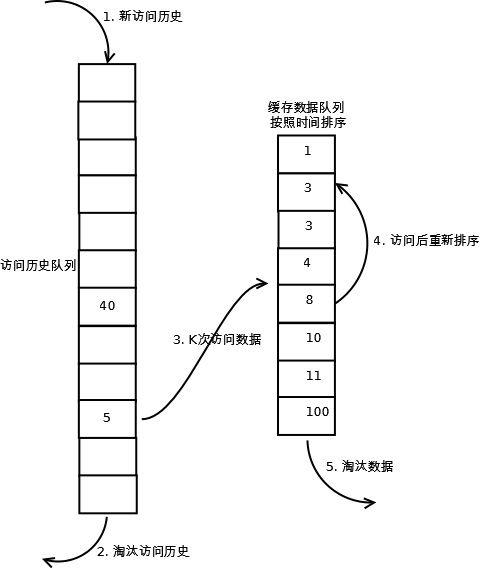
1. 資料第一次被訪問,加入到訪問歷史列表;
2. 如果資料在訪問歷史列表裡後沒有達到K次訪問,則按照一定規則(FIFO,LRU)淘汰;
3. 當訪問歷史佇列中的資料訪問次數達到K次後,將資料索引從歷史佇列刪除,將資料移到快取佇列中,並快取此資料,快取佇列重新按照時間排序;
4. 快取資料佇列中被再次訪問後,重新排序;
5. 需要淘汰資料時,淘汰快取佇列中排在末尾的資料,即:淘汰“倒數第K次訪問離現在最久”的資料。
LRU-K具有LRU的優點,同時能夠避免LRU的缺點,實際應用中LRU-2是綜合各種因素後最優的選擇,LRU-3或者更大的K值命中率會高,但適應性差,需要大量的資料訪問才能將歷史訪問記錄清除掉。
2.3. 分析
【命中率】
LRU-K降低了“快取汙染”帶來的問題,命中率比LRU要高。
【複雜度】
LRU-K佇列是一個優先順序佇列,演算法複雜度和代價比較高。
【代價】
由於LRU-K還需要記錄那些被訪問過、但還沒有放入快取的物件,因此記憶體消耗會比LRU要多;當資料量很大的時候,記憶體消耗會比較可觀。
LRU-K需要基於時間進行排序(可以需要淘汰時再排序,也可以即時排序),CPU消耗比LRU要高。
3. Two queues(2Q)
3.1. 原理
Two queues(以下使用2Q代替)演算法類似於LRU-2,不同點在於2Q將LRU-2演算法中的訪問歷史佇列(注意這不是快取資料的)改為一個FIFO快取佇列,即:2Q演算法有兩個快取佇列,一個是FIFO佇列,一個是LRU佇列。
3.2. 實現
當資料第一次訪問時,2Q演算法將資料快取在FIFO佇列裡面,當資料第二次被訪問時,則將資料從FIFO佇列移到LRU佇列裡面,兩個佇列各自按照自己的方法淘汰資料。詳細實現如下:
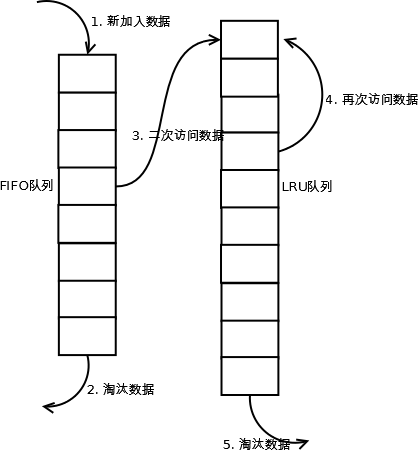
1. 新訪問的資料插入到FIFO佇列;
2. 如果資料在FIFO佇列中一直沒有被再次訪問,則最終按照FIFO規則淘汰;
3. 如果資料在FIFO佇列中被再次訪問,則將資料移到LRU佇列頭部;
4. 如果資料在LRU佇列再次被訪問,則將資料移到LRU佇列頭部;
5. LRU佇列淘汰末尾的資料。
注:上圖中FIFO佇列比LRU佇列短,但並不代表這是演算法要求,實際應用中兩者比例沒有硬性規定。
3.3. 分析
【命中率】
2Q演算法的命中率要高於LRU。
【複雜度】
需要兩個佇列,但兩個佇列本身都比較簡單。
【代價】
FIFO和LRU的代價之和。
2Q演算法和LRU-2演算法命中率類似,記憶體消耗也比較接近,但對於最後快取的資料來說,2Q會減少一次從原始儲存讀取資料或者計算資料的操作。
4. Multi Queue(MQ)
4.1. 原理
MQ演算法根據訪問頻率將資料劃分為多個佇列,不同的佇列具有不同的訪問優先順序,其核心思想是:優先快取訪問次數多的資料。
4.2. 實現
MQ演算法將快取劃分為多個LRU佇列,每個佇列對應不同的訪問優先順序。訪問優先順序是根據訪問次數計算出來的,例如
詳細的演算法結構圖如下,Q0,Q1....Qk代表不同的優先順序佇列,Q-history代表從快取中淘汰資料,但記錄了資料的索引和引用次數的佇列:
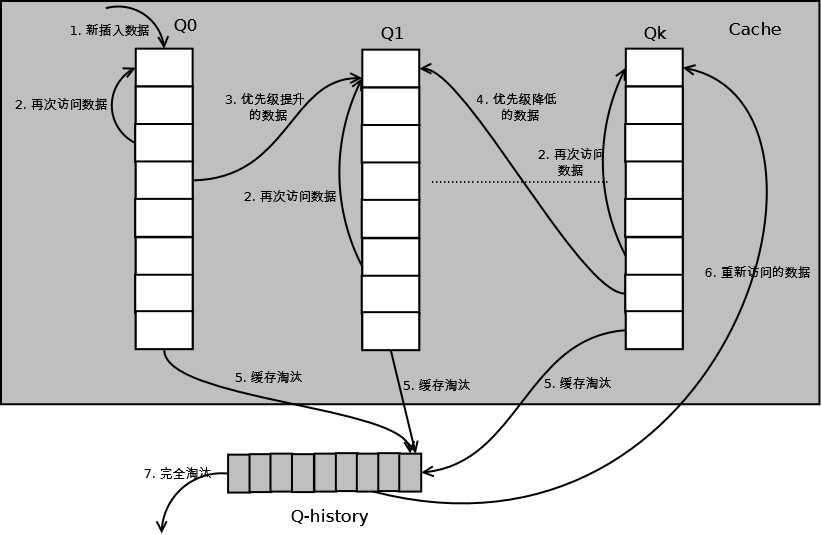
如上圖,演算法詳細描述如下:
1. 新插入的資料放入Q0;
2. 每個佇列按照LRU管理資料;
3. 當資料的訪問次數達到一定次數,需要提升優先順序時,將資料從當前佇列刪除,加入到高一級佇列的頭部;
4. 為了防止高優先順序資料永遠不被淘汰,當資料在指定的時間裡訪問沒有被訪問時,需要降低優先順序,將資料從當前佇列刪除,加入到低一級的佇列頭部;
5. 需要淘汰資料時,從最低一級佇列開始按照LRU淘汰;每個佇列淘汰資料時,將資料從快取中刪除,將資料索引加入Q-history頭部;
6. 如果資料在Q-history中被重新訪問,則重新計算其優先順序,移到目標佇列的頭部;
7. Q-history按照LRU淘汰資料的索引。
4.3. 分析
【命中率】
MQ降低了“快取汙染”帶來的問題,命中率比LRU要高。
【複雜度】
MQ需要維護多個佇列,且需要維護每個資料的訪問時間,複雜度比LRU高。
【代價】
MQ需要記錄每個資料的訪問時間,需要定時掃描所有佇列,代價比LRU要高。
注:雖然MQ的佇列看起來數量比較多,但由於所有佇列之和受限於快取容量的大小,因此這裡多個佇列長度之和和一個LRU佇列是一樣的,因此佇列掃描效能也相近。
5. LRU類演算法對比
由於不同的訪問模型導致命中率變化較大,此處對比僅基於理論定性分析,不做定量分析。
|
對比點 |
對比 |
|
命中率 |
LRU-2 > MQ(2) > 2Q > LRU |
|
複雜度 |
LRU-2 > MQ(2) > 2Q > LRU |
|
代價 |
LRU-2 > MQ(2) > 2Q > LRU |
實際應用中需要根據業務的需求和對資料的訪問情況進行選擇,並不是命中率越高越好。例如:雖然LRU看起來命中率會低一些,且存在”快取汙染“的問題,但由於其簡單和代價小,實際應用中反而應用更多。
java中最簡單的LRU演算法實現,就是利用jdk的LinkedHashMap,覆寫其中的removeEldestEntry(Map.Entry)方法即可
如果你去看LinkedHashMap的原始碼可知,LRU演算法是通過雙向連結串列來實現,當某個位置被命中,通過調整連結串列的指向將該位置調整到頭位置,新加入的內容直接放在連結串列頭,如此一來,最近被命中的內容就向連結串列頭移動,需要替換時,連結串列最後的位置就是最近最少使用的位置。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
相關推薦快取淘汰演算法之LRU1. LRU 1.1. 原理 LRU(Least recently used,最近最少使用)演算法根據資料的歷史訪問記錄來進行淘汰資料,其核心思想是“如果資料最近被訪問過,那麼將來被訪問的機率也更高”。 1.2. 實現 最常見的實現 快取淘汰演算法(LRU演算法)LRU是Least Recently Used 的縮寫,翻譯過來就是“最近最少使用”,LRU快取就是使用這種原理實現,簡單的說就是快取一定量的資料,當超過設定的閾值時就把一些過期的資料刪除掉,比如我們快取10000條資料,當資料小於10000時可以隨意新增,當超 兩種常見的快取淘汰演算法LFU&LRU1. LFU 1.1. 原理 LFU(Least Frequently Used)演算法根據資料的歷史訪問頻率來淘汰資料,其核心思想是“如果資料過去被訪問多次,那麼將來被訪問的頻率也更高”。 1.2. 實現 LFU的每個資料塊都有一個引用計數,所有資料 演算法 - 06 | 連結串列(上):如何實現LRU快取淘汰演算法?連結串列的一個景點應用場景 --- LRU快取淘汰演算法 1. 快取 什麼是快取 快取是一種提高資料讀取效能的技術,在硬體設計、軟體開發中都有著非常廣泛的應用,比如常見的CPU快取、資料庫快取、瀏覽器快取等等。 快取淘汰策略 快取大小有限,當快取被用滿是,那些資料應該被清理出去,那些資料被 Chapter 6 連結串列(上):如何實現LRU快取淘汰演算法?快取淘汰策略: 一、什麼是連結串列? 1.和陣列一樣,連結串列也是一種線性表。 2.從記憶體結構來看,連結串列的記憶體結構是不連續的記憶體空間,是將一組零散的記憶體塊串聯起來,從而進行資料儲存的資料結構。 3.連結串列中的每一個記憶體塊被稱為節點Node。節點除了儲存資料外,還需記錄鏈 連結串列(上):如何實現LRU快取淘汰演算法?本文是學習演算法的筆記,《資料結構與演算法之美》,極客時間的課程 連結串列(Linked list) 快取技術是一種提高資料讀取效能的技術,應用廣泛。快取的大小有限,當快取被用滿的時候,哪些資料應該被保留?這需要快取淘汰策略來決定。 常見的策略有三種: 先進先出策略FIFO( 快取淘汰演算法LRU及JAVA實現一、基本概念 命中:訪問快取是通過key get到對應value 回源: miss了,未命中導致回讀源資料 淘汰:快取滿了,那麼就會按照某一種策略,把快取中的舊物件踢出,而把新的物件加入快取池。(只有5個儲存單元,來了第6個元素。則考慮誰出隊) 淘汰策略:即快取演算法 06-連結串列(上)如何實現LRU快取淘汰演算法今天我們來聊聊“連結串列(Linked list)”這個資料結構。學習連結串列有什麼用呢?為了回答這個問題,我們先來討論一個經典的連結串列應用場景,那就是 LRU 快取淘汰演算法。 快取是一種提高資料讀取效能的技術,在硬體設計、軟體開發中都有著非常廣泛的應用,比 算法系列-連結串列:如何實現LRU快取淘汰演算法整理自極客時間-資料結構與演算法之美。原文內容更完整具體,且有音訊。購買地址: 開篇語 今天我們來聊聊“連結串列(Linked list)經典的應用場景,那就是 LRU 快取淘汰演算法。 快取是一種提高資料讀取效能的技術,在硬體設計、軟體開發中都有著非常廣泛的應用, 看動畫理解「連結串列」實現LRU快取淘汰演算法前幾節學習了「連結串列」、「時間與空間複雜度」的概念,本節將結合「迴圈連結串列」、「雙向連結串列」與 「用空間換時間的設計思想」來設計一個很有意思的快取淘汰策略:LRU快取淘汰演算法。 迴圈連結串列的概念 如上圖所示:單鏈表的尾結點指標指向空地址,表示這就是最後的結點了。而迴圈連結串列的 LFU & LRU-K 等常用快取淘汰演算法對比上篇文章介紹了最常用的LRU演算法及實現,本篇總結常用快取淘汰演算法,歸總對比。 一、LFU (Least Frequently Used):最近最低使用頻次被淘汰 實現:通過count記錄快取資料的使用次數,資料塊按照引用計數排序,計數相同則按照時間排序。 1. 新 兩種常見的快取淘汰演算法LFU&LRU1. LFU 1.1. 原理 LFU(Least Frequently Used)演算法根據資料的歷史訪問頻率來淘汰資料,其核心思想是“如果資料過去被訪問多次,那麼將來被訪問的頻率也更高”。 1.2. 實現 常用快取淘汰演算法(LFU、LRU、ARC、FIFO、MRU)https://www.jianshu.com/p/908e4b671de0 Java技術棧 2017.12.17 07:33* 字數 822 閱讀 1426評論 0喜歡 10 QQ用得起來越少了,現在就加入300+技術微信群,下方公眾號回覆"微信群"即可加入。 基於最少使用頻次的LRU,LFU快取淘汰演算法概念分析 LFU(Least Frequently Used)即最近最不常用.看名字就知道是個基於訪問頻次的一種演算法。以前寫過幾篇關於用python實現lru演算法的模組,有興趣的朋友可以看看。 LRU是基於時間的,會將時間上最不常訪問的資料給淘汰,在 如何實現LRU快取淘汰演算法快取是一種提高資料讀取效能的技術,比如常見的cpu快取以及瀏覽器快取!但是快取的大小有限,當快取用滿的時候,哪些資料應該被清理出去,哪些資料應該被保留? 解決方案:FIFO--->先進先出 LFU---> 最少使用 LRU-->最近最少使用 LRU快取淘汰演算法分析與實現概述 記錄一下LRU快取淘汰演算法的實現。 原理 LRU(Least recently used,最近最少使用)快取演算法根據資料最近被訪問的情況來進行淘汰資料,其核心思想是“如果資料最近被訪問過,那麼將來被訪問的機率也更高”。 介紹 下圖中,介紹 快取淘汰演算法-LRU演算法轉載自:http://flychao88.iteye.com/blog/1977653 1. LRU 1.1. 原理 LRU(Least recently used,最近最少使用)演算法根據資料的歷史訪問記錄來進行淘汰資料,其核心思想是“如果資料最近被訪問過,那麼將 聊聊快取淘汰演算法-LRU 實現原理前言 我們常用快取提升資料查詢速度,由於快取容量有限,當快取容量到達上限,就需要刪除部分資料挪出空間,這樣新資料才可以新增進來。快取資料不能隨機刪除,一般情況下我們需要根據某種演算法刪除快取資料。常用淘汰演算法有 LRU,LFU,FIFO,這篇文章我們聊聊 LRU 演算法。 LRU 簡介 LRU 是 Leas 詳解工程師不可不會的LRU快取淘汰演算法大家好,歡迎大家來到演算法資料結構專題,今天我們和大家聊一個非常常用的演算法,叫做LRU。 LRU的英文全稱是Least Recently Used,也即最不經常使用。我們看著好像挺迷糊的,其實這個含義要結合快取一起使用。對於工程而言,快取是非常非常重要的機制,尤其是在當下的網際網路應用環境當中,起到的作用非 緩存淘汰策略之LRUrec 算法 訪問 表頭 ont 策略 ima 想是 recently LRU(Least recently used,最近最少使用)算法根據數據的歷史訪問記錄來進行淘汰數據,其核心思想是“如果數據最近被訪問過,那麽將來被訪問的幾率也更高”。 1. 新數據插入到鏈表頭部; |