
CTR預估特徵工程
特徵工程
專案資料格式

CTR預估的流程
資料—>預處理—>特徵提取—>模型訓練—>後處理
模型和特徵的關係
一句話概括這個問題,特徵決定了上界,而模型決定了接近上界的程度。
資料預處理
首先要進行的是label匹配,由於我們拿到的資料為展示日誌和點選日誌,我們需要做的是將拿到的資料進行join操作,資料join完成之後我們,得到我們想要的訓練資料。資料的預處理主要就是資訊的組合,將其他檔案的相關資訊,組合到一個檔案中,形成我們的訓練資料。join的程式碼如下
#! /bin/bash
sort -t $'\t' -k "$2,$2" $1 >t1
sort -t $'\t' 如果資料較多,我們一般對資料進行負取樣。負取樣就是採集label為0的日誌,保留正樣本,如果樣本數量不均衡,處理方法有,保留所有正樣本,同時向下負取樣,或者保留所有正樣本且複製多次,同時向下負取樣,使得比例大約為1:10左右。
資料特徵
這裡的特徵一般都三類,使用者特徵,廣告特徵和上下文特徵
| 標題 | 特徵 |
|---|---|
| 使用者特徵 | userid、gender、age |
| 廣告特徵 | adid、titleid、advertedierid、keywordid、decription |
| 上下文特徵 | depth、position |
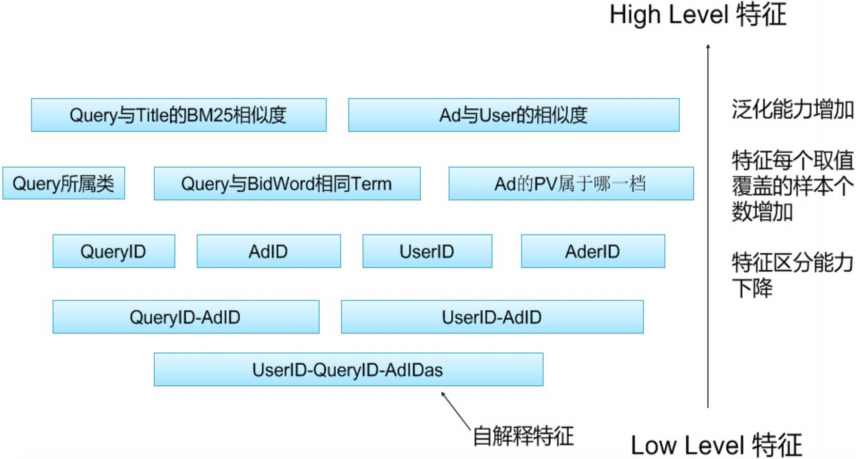
以上的這些特徵按照,不同的能力,還可以有不同的劃分方法,High Level特徵和Low Level特徵。
High Level特徵:指的是泛化能力比較強的特徵
Low Level特徵:指的是子解釋性比較強的特徵
具體的關係如下圖所示:
這裡的特徵還可以按照刻畫能力和覆蓋度進行劃分
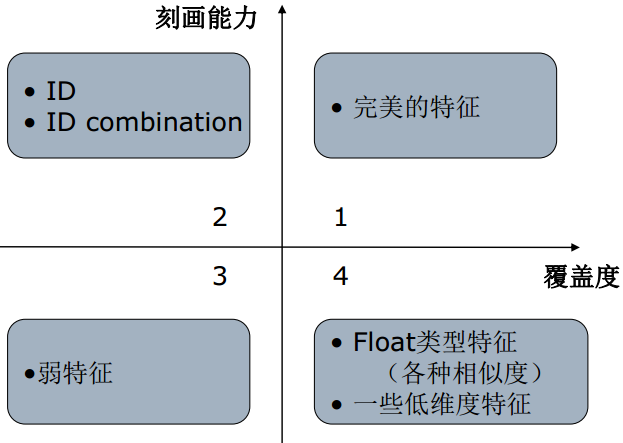
當然,我們最想要的就是在第一象限的完美特徵,但是這種特徵一般比較少,二三象限的特徵比較多,而第四象限的特徵的影響就比較微弱了。
資料特徵處理方法
One Hot Encoding
One-Hot編碼,又稱為一位有效編碼,主要是採用位狀態暫存器來對個狀態進行編碼,每個狀態都由他獨立的暫存器位,並且在任意時候只有一位有效。在實際的機器學習的應用任務中,特徵有時候並不總是連續值,有可能是一些分類值,如性別可分為“male”和“female”。在機器學習任務中,對於這樣的特徵,通常我們需要對其進行特徵數字化,舉例說明,我們有如下屬性:
性別:[“male”,”female”]
廣告id:[11,22,33,44,55,66]
位置:[1,2,3,4,5,6]
對以一個樣本[“feamle”,44,4],可以採用序列化的方式[1,3,3],但是這樣不能直接在演算法中使用。
One Hot Encoding的編碼思想是,”female”對應[0,1],廣告id44對應的是[0,0,0,1,0,0],位置4對應的是[0,0,0,1,0,0],則完整的特徵數字化的結果為:
[0,1,0,0,0,1,0,0,0,0,0,1,0,0]
具體的程式碼實現,有兩種方法,一種是通過加入字首,形成唯一的編號,一種是通過Hash函式的方法,雖然Hash函式的方法,在資料量比較大的時候會有一些衝突,但是這對最後的影響結果不是很大。
加入字首的特徵處理
def processIdFeature(prefix,id):
global feature_map
global feature_index
str = prefix + "_" + id
if str in feature_map:
return feature_map[str]
else:
feature_index = feature_index + 1
feature_map[str] = feature_index
return feature_indexHash函式的方法
def hashFeature(prefix,id):
str = prefix + "_" + id
return hash(str) % HASH_SIZE離散化
為什麼要使用離散化的方法?
假設特徵在[0,1]之間,預測是有非線性關係
等值離散
等值劃分是將特徵按照值域進行均分,每一段內的取值等同處理。
等量離散
等量劃分是根據樣本總數進行均分,每段等量個樣本劃分為1段。
特徵組合
特徵組合的目的,主要有兩種
| 特徵組合 | 目的 |
|---|---|
| AUC之間進行組合 | 提高表達關係的能力 |
| AUC內部進行組合 | 提高自解釋的能力 |