
CTR預估模型演變及學習筆記
【說在前面】本人部落格新手一枚,象牙塔的老白,職業場的小白。以下內容僅為個人見解,歡迎批評指正,不喜勿噴![握手][握手]
【再囉嗦一下】如果你對智慧推薦感興趣,歡迎先瀏覽我的另一篇隨筆:智慧推薦演算法演變及學習筆記
【最後再說一下】本文只對智慧推薦演算法中的CTR預估模型演變進行具體介紹!
一、傳統CTR預估模型演變
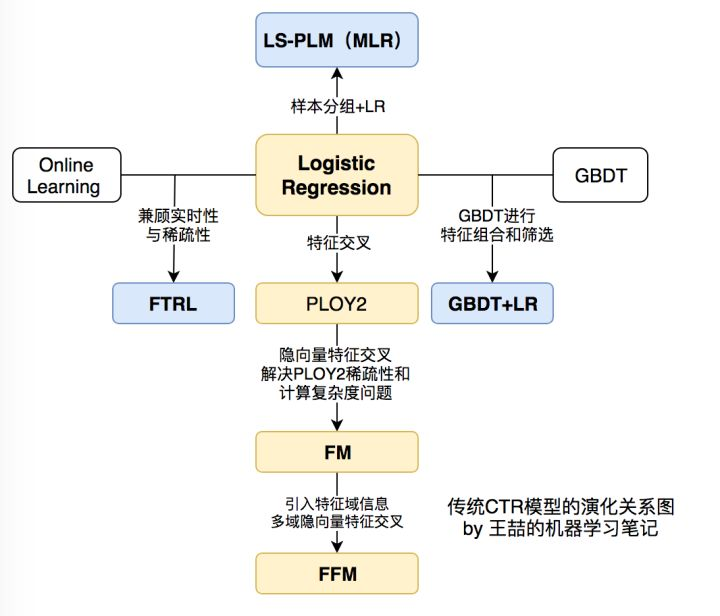
1. LR
即邏輯迴歸。LR模型先求得各特徵的加權和,再新增sigmoid函式。
- 使用各特徵的加權和,是為了考慮不同特徵的重要程度
- 使用sigmoid函式,是為了將值對映到 [0, 1] 區間
LR模型的優點在於:
- 易於並行化、模型簡單、訓練開銷小
- 可解釋性強、可拓展性強
LR模型的缺點在於:
- 只使用單一特徵,無法利用高維資訊,表達能力有限
- 特徵工程需要耗費大量的精力
2. POLY2
POLY2對所有特徵進行“暴力”組合(即兩兩交叉),並對所有的特徵組合賦予了權重。
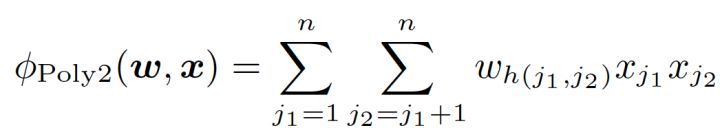
一定程度上解決了LR缺乏特徵組合的問題,但是“暴力行為”帶來了一些問題:
- 特徵維度爆炸,特徵資料過於稀疏,特徵權重不易收斂
3. FM
相比於POLY2,FM為每個特徵學習了一個隱權重向量 w。在特徵交叉時,使用兩個特徵隱向量w的內積作為交叉特徵的權重。

將原先n^2級別的權重數量降低到n*k(k為隱向量w的維度,n>>k),極大降低了訓練開銷。
4. FFM
在FM模型基礎上,FFM模型引入了Field-aware。在特徵交叉時,使用特徵在對方特徵域上的隱向量內積作為交叉特徵的權重。
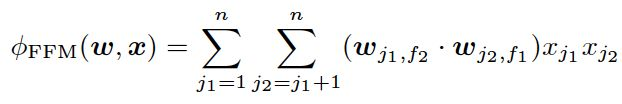
FFM模型的權重數量共n*k*f個,計算複雜度上升到k*n^2,遠遠大於FM模型的k*n。
5. GBDT/xgboost/lightgbm
直接使用機器學習演算法中的整合學習方法。
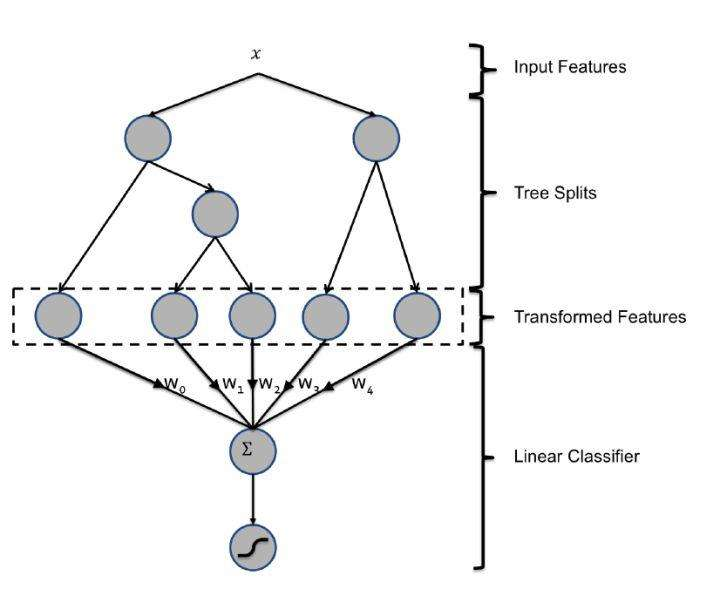
6. GBDT+LR/FM/FFM
利用GBDT自動進行特徵篩選和組合,進而生成新的離散特徵向量,再把該特徵向量當作LR模型的輸入。
7. MLR
在LR的基礎上採用分而治之的思路,先對樣本進行分片,再在樣本分片中應用LR進行CTR預估。
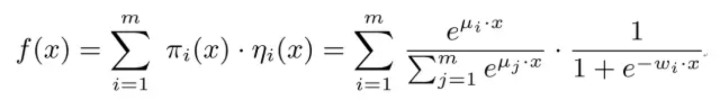
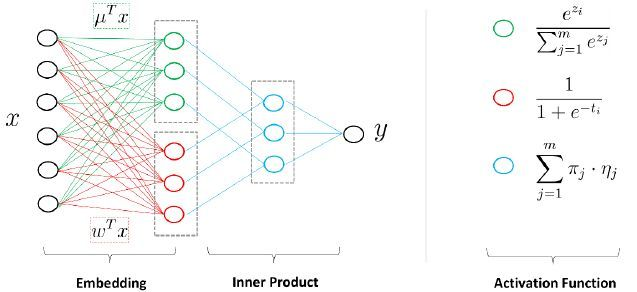
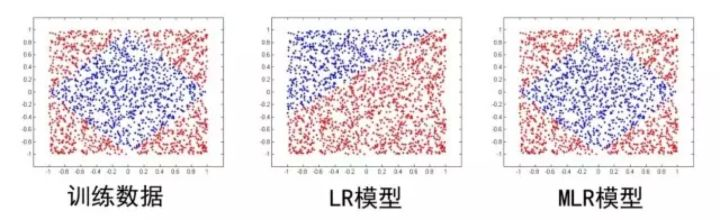
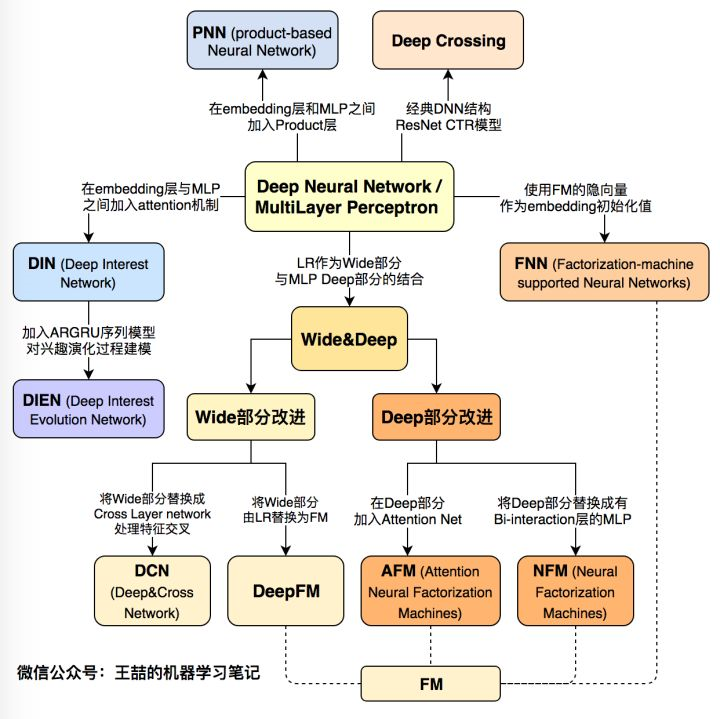
以上1-7部分可以總結為傳統的CTR預估模型演變,這裡分享一下大佬的關係圖譜:
二、引入深度學習的CTR預估模型演變
1. Deep Crossing
通過加入embedding層將稀疏特徵轉化為低維稠密特徵,用stacking層連線分段的特徵向量,再通過多層神經網路完成特徵組合/轉換。
跟經典DNN有所不同的是,Deep crossing採用的multilayer perceptron是由殘差網路組成的。
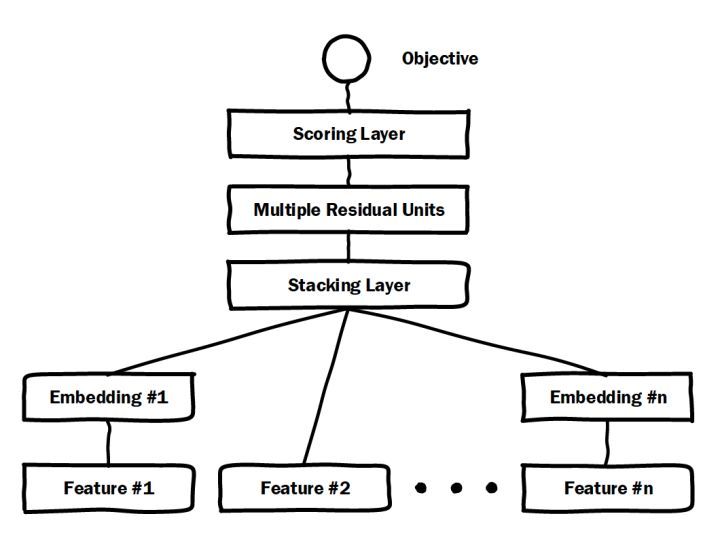
2. FNN
相比於Deep Crossing,FNN使用FM的隱層向量作為user和item的Embedding,從而避免了完全從隨機狀態訓練Embedding。
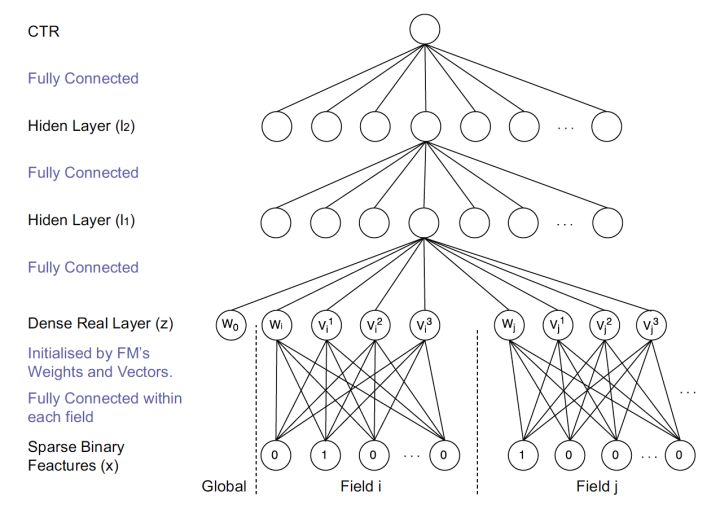
3. Wide & Deep
把單輸入層的Wide部分和經過多層感知機的Deep部分連線起來,一起輸入最終的輸出層。
- wide部分:高維特徵+特徵組合的LR
- deep部分:deep learning
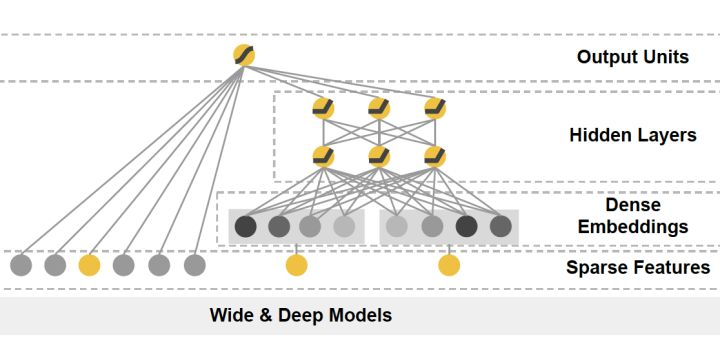
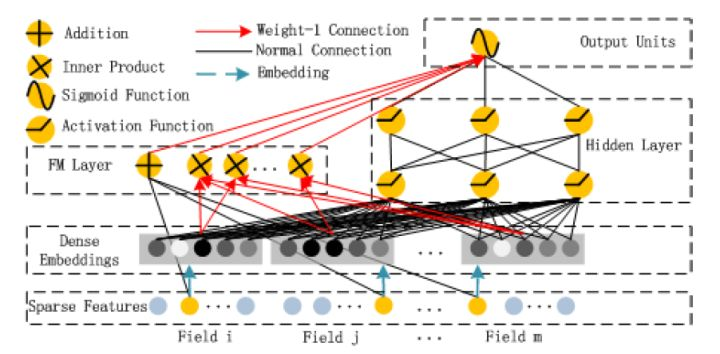
4. DeepFM
DeepFM對Wide & Deep的改進之處在於,用FM替換掉了原來的Wide部分,加強了淺層網路部分特徵組合的能力。
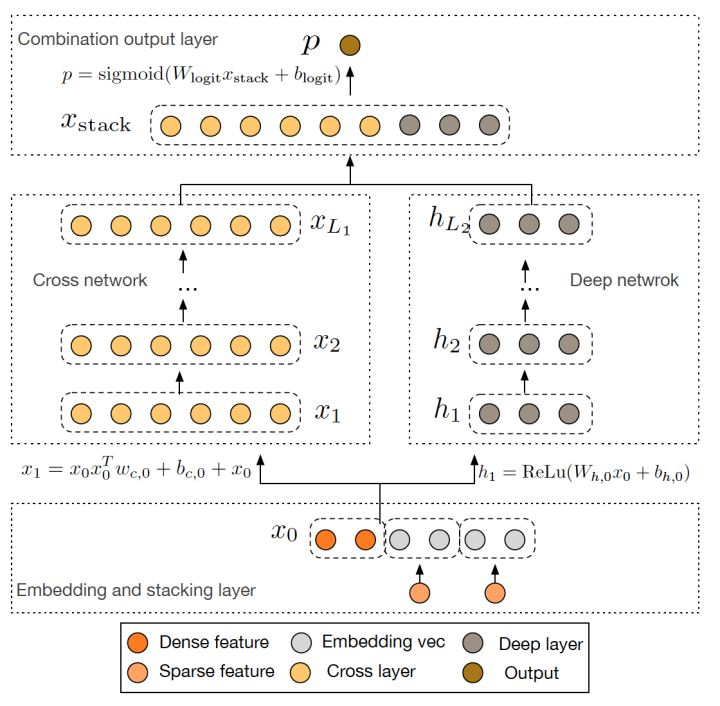
5. Deep & Cross (DCN)
使用Cross網路替代了原來的Wide部分。Cross網路使用多層cross layer對輸入向量進行特徵交叉,增加特徵之間的互動。
6. NFM
相對於DeepFM和DCN對於Wide&Deep Wide部分的改進,NFM可以看作是對Deep部分的改進。
NFM用一個帶Bi-interaction Pooling層的DNN替換了FM的特徵交叉部分。
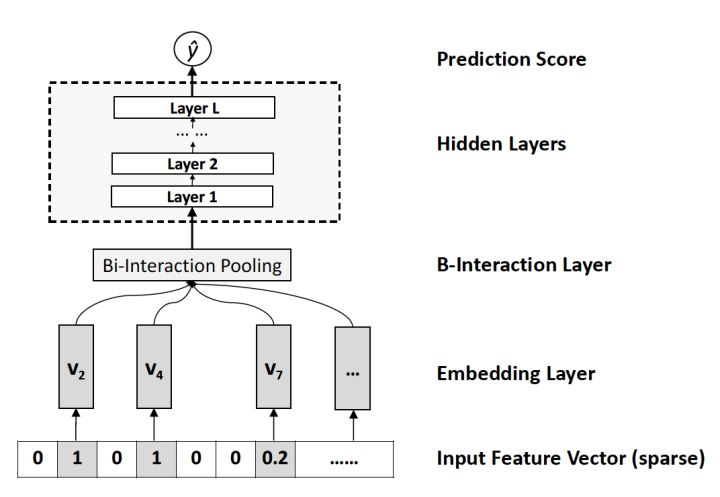
7. Deep Interest Network (DIN)
在模型的embedding layer和concatenate layer之間加入了attention unit,使模型能夠根據候選商品的不同,調整不同特徵的權重。

以上1-7部分可以總結為引入深度學習的CTR預估模型演變,這裡分享一下大佬的關係圖譜:
三、深度學習推薦模型的上線問題
對於深度學習推薦模型的離線訓練自然不是問題,一般可以採用比較成熟的離線並行訓練環境。
對於深度學習推薦模型的上線問題,其線上時效性至關重要。
1. “特徵實時性”
這裡分享一下大佬畫的智慧推薦系統主流技術架構圖,博主認知有限,就不展開介紹了。

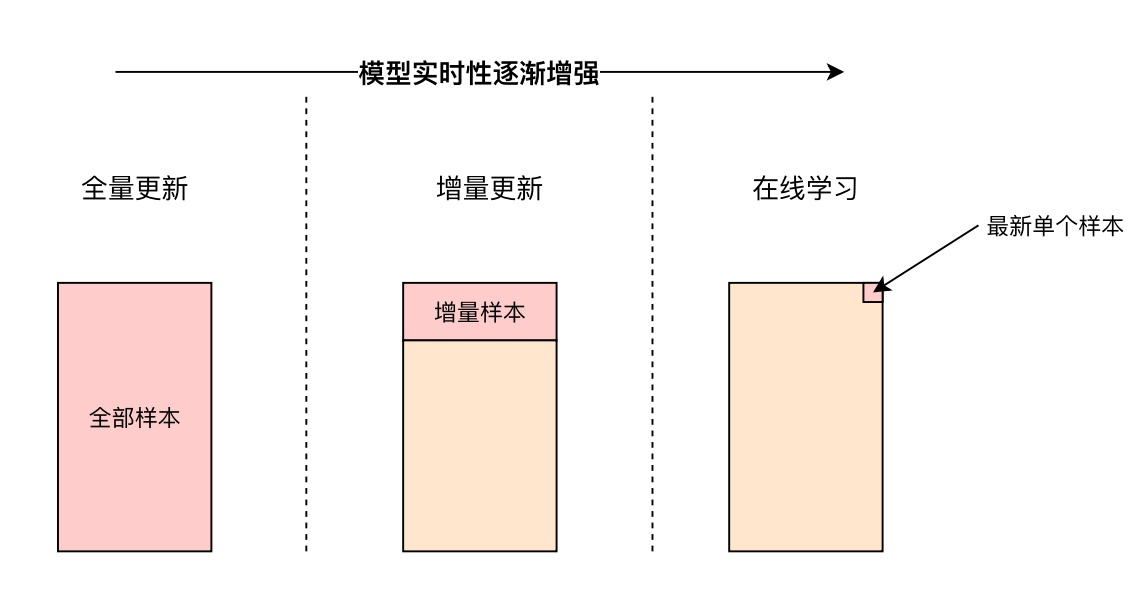
2. “模型實時性”
與“特徵實時性”相比,推薦系統模型的實時性往往是從更全域性的角度考慮問題,博主認知有限,就不展開介紹了。
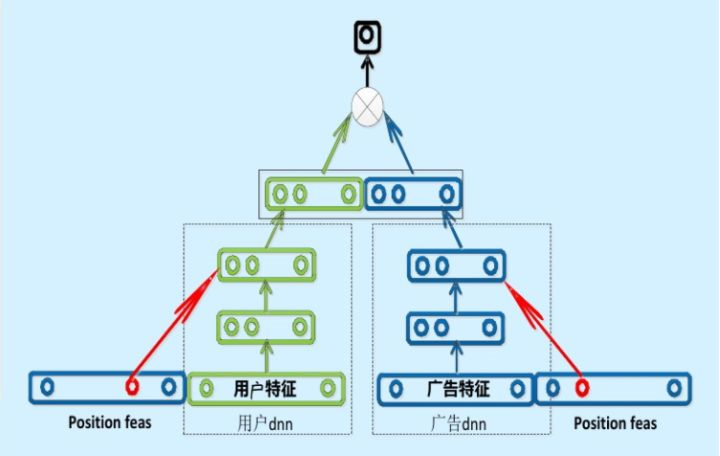
3. “服務實時性”:雙塔模型
很多公司採用“複雜網路離線訓練,生成embedding存入記憶體資料庫,線上實現LR或淺層NN等輕量級模型擬合優化目標”的上線方式。
以百度的雙塔模型舉例說明:
(1)分別用複雜網路對“使用者特徵”和“廣告特徵”進行embedding,這就形成了兩個獨立的“塔”,因此稱為雙塔模型。
(2)在完成雙塔模型的訓練後,可以把最終的使用者embedding和廣告embedding存入記憶體資料庫。
(3)線上推理時,只需要實現最後一層的邏輯,從記憶體資料庫中取出使用者/廣告的embedding,通過簡單計算即可得到預估結果。
最後感嘆一句,深度學習CTR模型的發展實在是太迅速了,很多新模型就不繼續介紹了,要保持學習啊!
本文參考了大佬的知乎專欄:https://zhuanlan.zhihu.com/p/51117616
如果你對智慧推薦感興趣,歡迎先瀏覽我的另一篇隨筆:智慧推薦演算法演變及學習筆記
如果您對資料探勘感興趣,歡迎瀏覽我的另一篇部落格:資料探勘比賽/專案全流程介紹
如果您對人工智慧演算法感興趣,歡迎瀏覽我的另一篇部落格:人工智慧新手入門學習路線和學習資源合集(含AI綜述/python/機器學習/深度學習/tensorflow)
如果你是計算機專業的應屆畢業生,歡迎瀏覽我的另外一篇部落格:如果你是一個計算機領域的應屆生,你如何準備求職面試?
如果你是計算機專業的本科生,歡迎瀏覽我的另外一篇部落格:如果你是一個計算機領域的本科生,你可以選擇學習什麼?
如果你是計算機專業的研究生,歡迎瀏覽我的另外一篇部落格:如果你是一個計算機領域的研究生,你可以選擇學習什麼?
如果你對金融科技感興趣,歡迎瀏覽我的另一篇部落格:如果你想了解金融科技,不妨先了解金融科技有哪些可能?
之後博主將持續分享各大演算法的學習思路和學習筆記:hello world: 我的部落格寫作