
阿里CTR預估:使用者行為長序列建模
本文將介紹Alibaba發表在KDD’19 的論文《Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction》。文章針對長序列使用者行為建模的問題從線上系統和演算法兩方面進行改進,已經成功部署在阿里巴巴的廣告系統。
使用深度學習對使用者興趣建模在離線評估階段帶來了顯著提升,但是線上部署時面對大量的流量請求難以實時推理,尤其是在對長序列使用者行為資料,系統的延時和儲存代價幾乎是隨著行為長度線性增長。為了解決長序列建模的挑戰,作者從兩個方面進行考慮:
1.從線上角度考慮,引入UIC(user interest center),從整個模型中分離出最消耗資源的。UIC依賴於使用者的行為觸發
2.從演算法角度考慮,引入記憶架構,MIMN(Multi-channel user Interest Memory Network),捕捉長序列行為
Theoretically, the co-design solution of UIC and MIMN enables us to handle the user interest modeling with unlimited length of sequential behavior data.
無限長?帶著懷疑又好奇態度拜讀下這篇大作。
- UIC
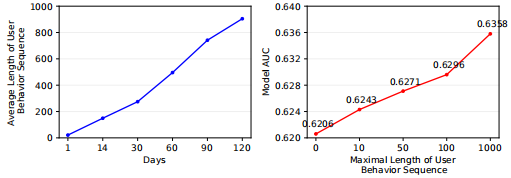
首先為什麼需要建模使用者的長序列行為?下圖是使用基礎模型(DIN)在不同長度行為序列上實驗的結果,可以看出當長度到達1000時AUC相比長度100時增加了0.6%。
圖(A)是一個典型的CTR實時預估系統架構,主要由特徵管理元件、模型管理元件和預測伺服器組成。為了保證系統低延時和高吞吐量,使用者的行為特徵通常被儲存在額外的儲存系統,阿里使用的是自研TAIR。當新的流量請求到達時,特徵更新到預測伺服器參與實時推理計算,阿里使用DIEN實驗發現,當行為序列長度達到150時,系統延時和吞吐量已經到達邊緣了,更不用說1000的長度。
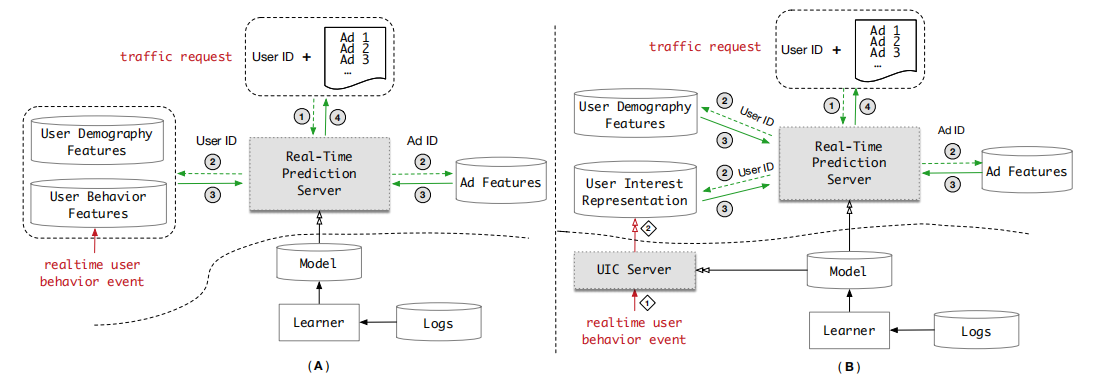
對使用者長期行為建模有兩個主要的限制:
1)儲存限制
阿里擁有6億使用者,如果每個使用者最大行為長度為150,至少需要1T的儲存空間;長度到1000時,需要6T儲存空間。更大的記憶體消耗,將會導致計算複雜度增加
2)延時限制
CTR預估模組根據輸入的候選商品集合,輸出對應的概率,這個過程通常需要在10ms內完成。DIEN在行為長度達到1000時,在500QPS延時達到了200ms,難以滿足線上廣告系統500QPS30ms的限制。
為了解決上述提到的長序列行為建模的問題,作者設計了UIC(user interest center)模組。圖(B)是UIC模組的示意,(A)(B)的區別在於使用者興趣表示計算,在(B)中,UIC會為每個使用者維持一個最新的興趣表示,UIC的更新僅取決於使用者的行為,不再是流量觸發,可以做到無延時。實際應用證明,UIC+DIEN將1000長度的200ms減少到19ms在500QPS下。
- MIMN
從演算法模型來看,建模長序列相當困難,RNN無法勝任,attention機制雖然可以更加有效的處理長序列,但是需要儲存所有原始的使用者行為序列,儲存和計算代價太大。MIMN借鑑神經圖靈機的思想,對長序列進行建模。下圖是MIMN的架構
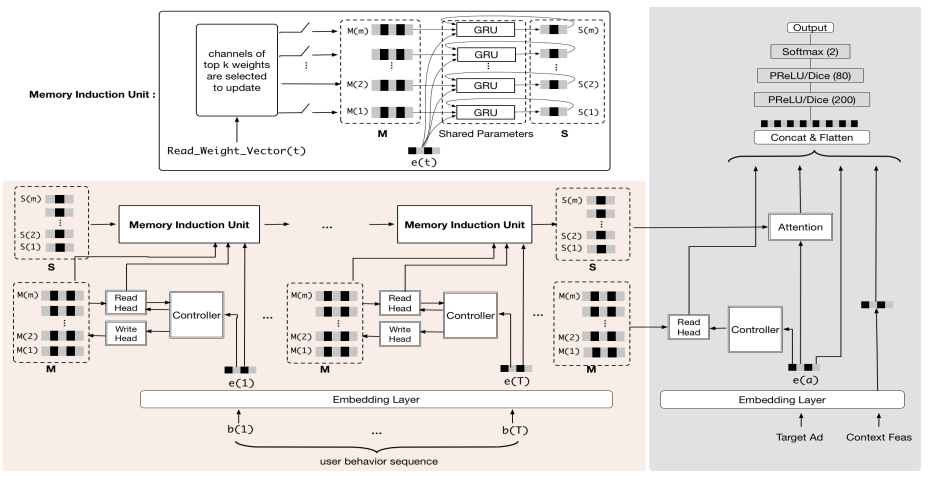
UIC儲存MIMN的外部記憶,當用戶產生新行為時進行更新。通過這種方式,UIC可以遞增的從行為序列中捕獲使用者的興趣,但是當儲存資源有限時,固定維度的向量表達能力有限。作者提出了記憶利用正則化增加UIC單元的表示能力,同時提出了記憶歸納單元捕獲高階資訊。
神經圖靈機
神經圖靈機使用一個記憶網路儲存資訊,通過讀寫控制器進行記憶讀寫。
記憶利用正則化
標準NTM存在記憶利用不平衡問題,導致記憶利用不充分。作者根據不同的記憶塊,正則化寫權重。
記憶歸納單元
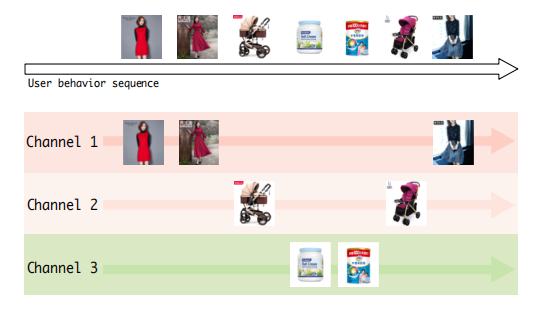
記憶歸納單元將每個記憶塊作為一個使用者興趣通道。在時間步t選擇一個k個通道,對選中的通道更新
\[
S_t(i)=GRU(S_{t+1}(i),M_t(i),e_t)
\]
可以實現下面的結果
enen……,回家了有點懶,剩下的部分下次更新……
references:
[1] Alibaba. Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction. KDD