
資料探勘-決策樹ID3分類演算法的C++實現
阿新 • • 發佈:2019-01-24
資料探勘課上面老師介紹了下決策樹ID3演算法,我抽空餘時間把這個演算法用C++實現了一遍。
決策樹演算法是非常常用的分類演算法,是逼近離散目標函式的方法,學習得到的函式以決策樹的形式表示。其基本思路是不斷選取產生資訊增益最大的屬性來劃分樣例集和,構造決策樹。資訊增益定義為結點與其子結點的資訊熵之差。資訊熵是夏農提出的,用於描述資訊不純度(不穩定性),其計算公式是
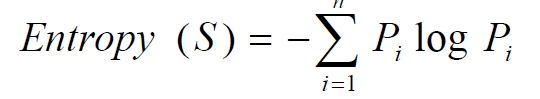
Pi為子集合中不同性(而二元分類即正樣例和負樣例)的樣例的比例。這樣資訊收益可以定義為樣本按照某屬性劃分時造成熵減少的期望,可以區分訓練樣本中正負樣本的能力,其計算公司是

我實現該演算法針對的樣例集合如下
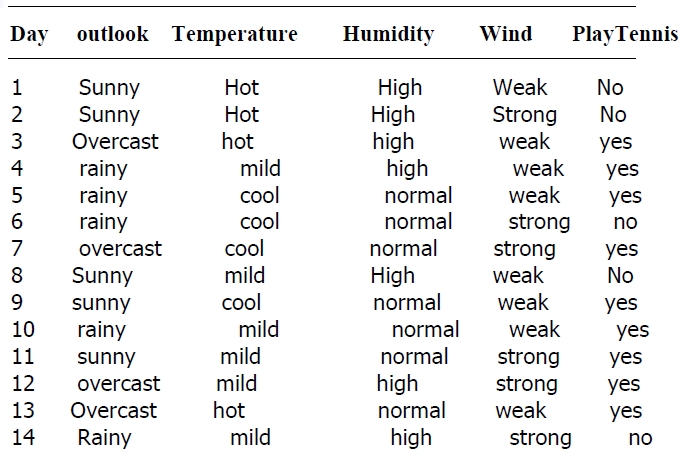
該表記錄了在不同氣候條件下是否去打球的情況,要求根據該表用程式輸出決策樹
C++程式碼如下,程式中有詳細註釋
輸入的訓練資料如下#include <iostream> #include <string> #include <vector> #include <map> #include <algorithm> #include <cmath> using namespace std; #define MAXLEN 6//輸入每行的資料個數 //多叉樹的實現 //1 廣義表 //2 父指標表示法,適於經常找父結點的應用 //3 子女連結串列示法,適於經常找子結點的應用 //4 左長子,右兄弟表示法,實現比較麻煩 //5 每個結點的所有孩子用vector儲存 //教訓:資料結構的設計很重要,本演算法採用5比較合適,同時 //注意維護剩餘樣例和剩餘屬性資訊,建樹時橫向遍歷考迴圈屬性的值, //縱向遍歷靠遞迴呼叫 vector <vector <string> > state;//例項集 vector <string> item(MAXLEN);//對應一行例項集 vector <string> attribute_row;//儲存首行即屬性行資料 string end("end");//輸入結束 string yes("yes"); string no("no"); string blank(""); map<string,vector < string > > map_attribute_values;//儲存屬性對應的所有的值 int tree_size = 0; struct Node{//決策樹節點 string attribute;//屬性值 string arrived_value;//到達的屬性值 vector<Node *> childs;//所有的孩子 Node(){ attribute = blank; arrived_value = blank; } }; Node * root; //根據資料例項計算屬性與值組成的map void ComputeMapFrom2DVector(){ unsigned int i,j,k; bool exited = false; vector<string> values; for(i = 1; i < MAXLEN-1; i++){//按照列遍歷 for (j = 1; j < state.size(); j++){ for (k = 0; k < values.size(); k++){ if(!values[k].compare(state[j][i])) exited = true; } if(!exited){ values.push_back(state[j][i]);//注意Vector的插入都是從前面插入的,注意更新it,始終指向vector頭 } exited = false; } map_attribute_values[state[0][i]] = values; values.erase(values.begin(), values.end()); } } //根據具體屬性和值來計算熵 double ComputeEntropy(vector <vector <string> > remain_state, string attribute, string value,bool ifparent){ vector<int> count (2,0); unsigned int i,j; bool done_flag = false;//哨兵值 for(j = 1; j < MAXLEN; j++){ if(done_flag) break; if(!attribute_row[j].compare(attribute)){ for(i = 1; i < remain_state.size(); i++){ if((!ifparent&&!remain_state[i][j].compare(value)) || ifparent){//ifparent記錄是否算父節點 if(!remain_state[i][MAXLEN - 1].compare(yes)){ count[0]++; } else count[1]++; } } done_flag = true; } } if(count[0] == 0 || count[1] == 0 ) return 0;//全部是正例項或者負例項 //具體計算熵 根據[+count[0],-count[1]],log2為底通過換底公式換成自然數底數 double sum = count[0] + count[1]; double entropy = -count[0]/sum*log(count[0]/sum)/log(2.0) - count[1]/sum*log(count[1]/sum)/log(2.0); return entropy; } //計算按照屬性attribute劃分當前剩餘例項的資訊增益 double ComputeGain(vector <vector <string> > remain_state, string attribute){ unsigned int j,k,m; //首先求不做劃分時的熵 double parent_entropy = ComputeEntropy(remain_state, attribute, blank, true); double children_entropy = 0; //然後求做劃分後各個值的熵 vector<string> values = map_attribute_values[attribute]; vector<double> ratio; vector<int> count_values; int tempint; for(m = 0; m < values.size(); m++){ tempint = 0; for(k = 1; k < MAXLEN - 1; k++){ if(!attribute_row[k].compare(attribute)){ for(j = 1; j < remain_state.size(); j++){ if(!remain_state[j][k].compare(values[m])){ tempint++; } } } } count_values.push_back(tempint); } for(j = 0; j < values.size(); j++){ ratio.push_back((double)count_values[j] / (double)(remain_state.size()-1)); } double temp_entropy; for(j = 0; j < values.size(); j++){ temp_entropy = ComputeEntropy(remain_state, attribute, values[j], false); children_entropy += ratio[j] * temp_entropy; } return (parent_entropy - children_entropy); } int FindAttriNumByName(string attri){ for(int i = 0; i < MAXLEN; i++){ if(!state[0][i].compare(attri)) return i; } cerr<<"can't find the numth of attribute"<<endl; return 0; } //找出樣例中佔多數的正/負性 string MostCommonLabel(vector <vector <string> > remain_state){ int p = 0, n = 0; for(unsigned i = 0; i < remain_state.size(); i++){ if(!remain_state[i][MAXLEN-1].compare(yes)) p++; else n++; } if(p >= n) return yes; else return no; } //判斷樣例是否正負性都為label bool AllTheSameLabel(vector <vector <string> > remain_state, string label){ int count = 0; for(unsigned int i = 0; i < remain_state.size(); i++){ if(!remain_state[i][MAXLEN-1].compare(label)) count++; } if(count == remain_state.size()-1) return true; else return false; } //計算資訊增益,DFS構建決策樹 //current_node為當前的節點 //remain_state為剩餘待分類的樣例 //remian_attribute為剩餘還沒有考慮的屬性 //返回根結點指標 Node * BulidDecisionTreeDFS(Node * p, vector <vector <string> > remain_state, vector <string> remain_attribute){ //if(remain_state.size() > 0){ //printv(remain_state); //} if (p == NULL) p = new Node(); //先看搜尋到樹葉的情況 if (AllTheSameLabel(remain_state, yes)){ p->attribute = yes; return p; } if (AllTheSameLabel(remain_state, no)){ p->attribute = no; return p; } if(remain_attribute.size() == 0){//所有的屬性均已經考慮完了,還沒有分盡 string label = MostCommonLabel(remain_state); p->attribute = label; return p; } double max_gain = 0, temp_gain; vector <string>::iterator max_it = remain_attribute.begin(); vector <string>::iterator it1; for(it1 = remain_attribute.begin(); it1 < remain_attribute.end(); it1++){ temp_gain = ComputeGain(remain_state, (*it1)); if(temp_gain > max_gain) { max_gain = temp_gain; max_it = it1; } } //下面根據max_it指向的屬性來劃分當前樣例,更新樣例集和屬性集 vector <string> new_attribute; vector <vector <string> > new_state; for(vector <string>::iterator it2 = remain_attribute.begin(); it2 < remain_attribute.end(); it2++){ if((*it2).compare(*max_it)) new_attribute.push_back(*it2); } //確定了最佳劃分屬性,注意儲存 p->attribute = *max_it; vector <string> values = map_attribute_values[*max_it]; int attribue_num = FindAttriNumByName(*max_it); new_state.push_back(attribute_row); for(vector <string>::iterator it3 = values.begin(); it3 < values.end(); it3++){ for(unsigned int i = 1; i < remain_state.size(); i++){ if(!remain_state[i][attribue_num].compare(*it3)){ new_state.push_back(remain_state[i]); } } Node * new_node = new Node(); new_node->arrived_value = *it3; if(new_state.size() == 0){//表示當前沒有這個分支的樣例,當前的new_node為葉子節點 new_node->attribute = MostCommonLabel(remain_state); } else BulidDecisionTreeDFS(new_node, new_state, new_attribute); //遞迴函式返回時即回溯時需要1 將新結點加入父節點孩子容器 2清除new_state容器 p->childs.push_back(new_node); new_state.erase(new_state.begin()+1,new_state.end());//注意先清空new_state中的前一個取值的樣例,準備遍歷下一個取值樣例 } return p; } void Input(){ string s; while(cin>>s,s.compare(end) != 0){//-1為輸入結束 item[0] = s; for(int i = 1;i < MAXLEN; i++){ cin>>item[i]; } state.push_back(item);//注意首行資訊也輸入進去,即屬性 } for(int j = 0; j < MAXLEN; j++){ attribute_row.push_back(state[0][j]); } } void PrintTree(Node *p, int depth){ for (int i = 0; i < depth; i++) cout << '\t';//按照樹的深度先輸出tab if(!p->arrived_value.empty()){ cout<<p->arrived_value<<endl; for (int i = 0; i < depth+1; i++) cout << '\t';//按照樹的深度先輸出tab } cout<<p->attribute<<endl; for (vector<Node*>::iterator it = p->childs.begin(); it != p->childs.end(); it++){ PrintTree(*it, depth + 1); } } void FreeTree(Node *p){ if (p == NULL) return; for (vector<Node*>::iterator it = p->childs.begin(); it != p->childs.end(); it++){ FreeTree(*it); } delete p; tree_size++; } int main(){ Input(); vector <string> remain_attribute; string outlook("Outlook"); string Temperature("Temperature"); string Humidity("Humidity"); string Wind("Wind"); remain_attribute.push_back(outlook); remain_attribute.push_back(Temperature); remain_attribute.push_back(Humidity); remain_attribute.push_back(Wind); vector <vector <string> > remain_state; for(unsigned int i = 0; i < state.size(); i++){ remain_state.push_back(state[i]); } ComputeMapFrom2DVector(); root = BulidDecisionTreeDFS(root,remain_state,remain_attribute); cout<<"the decision tree is :"<<endl; PrintTree(root,0); FreeTree(root); cout<<endl; cout<<"tree_size:"<<tree_size<<endl; return 0; }
Day Outlook Temperature Humidity Wind PlayTennis 1 Sunny Hot High Weak no 2 Sunny Hot High Strong no 3 Overcast Hot High Weak yes 4 Rainy Mild High Weak yes 5 Rainy Cool Normal Weak yes 6 Rainy Cool Normal Strong no 7 Overcast Cool Normal Strong yes 8 Sunny Mild High Weak no 9 Sunny Cool Normal Weak yes 10 Rainy Mild Normal Weak yes 11 Sunny Mild Normal Strong yes 12 Overcast Mild High Strong yes 13 Overcast Hot Normal Weak yes 14 Rainy Mild High Strong no end
程式輸出決策樹如下
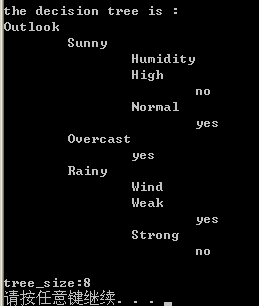
可以用圖形表示為
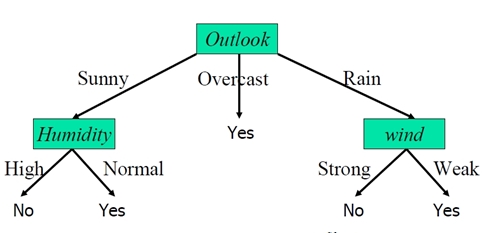
有了決策樹後,就可以根據氣候條件做預測了
例如如果氣候資料是{Sunny,Cool,Normal,Strong} ,根據決策樹到左側的yes葉節點,可以判定會去游泳。
另外在編寫這個程式時在資料結構的設計上面走了彎路,多叉樹的實現有很多方法,本演算法採用每個結點的所有孩子用vector儲存比較合適,同時注意維護剩餘樣例和剩餘屬性資訊,建樹時橫向遍歷靠迴圈屬性的值,縱向遍歷靠遞迴呼叫 ,總體是DFS,樹和圖的遍歷在程式設計時經常遇到,得熟練掌握。程式有些地方的效率還得優化,有不足的點地方還望大家拍磚。