
論文閱讀:《Convolutional Pose Machines》CVPR 2016
概述
本文使用CNN進行人體姿態估計,它的主要貢獻在於使用順序化的卷積架構來表達空間資訊和紋理資訊。順序化的卷積架構表現在網路分為多個階段,每一個階段都有監督訓練的部分。前面的階段使用原始圖片作為輸入,後面階段使用之前階段的特徵圖作為輸入,主要是為了融合空間資訊,紋理資訊和中心約束。另外,對同一個卷積架構同時使用多個尺度處理輸入的特徵和響應,既能保證精度,又考慮了各部件之間的遠近距離關係。
網路結構以及流程
演算法流程:
1. 計算各個尺度下,各部件的相應圖
2. 對於每一個部件,累加所有尺度的相應圖,得到總的響應圖
3. 在各部件的總響應圖下,找到相應的最大點,即為該部件的位置所在
網路結構:
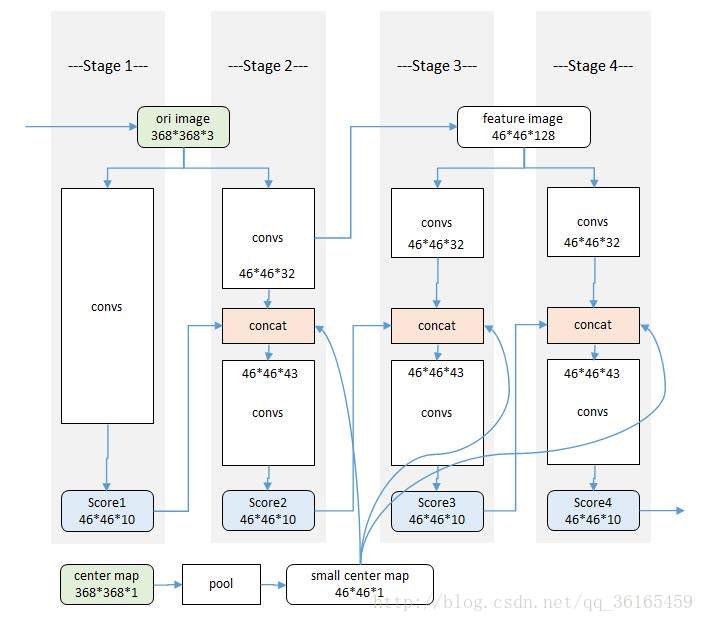
這是檢測半身部件的順序化卷積架構,其部件一共是9個(不包括背景)。綠色的ori部分是原始輸入圖片,綠色的center map部分是一個高斯函式模版,用於將響應歸一到中心部分。白色的convs是相同的卷積架構部分。藍色的score部分是經過卷積層的相應圖,即空間資訊。橙色的concat部分是串聯結構,用於融合卷積層的中間結果,上一階段的響應圖以及高斯模版生成的中心約束。
具體的各個階段的構造如下:
Stage1:原始圖片經過卷積層,得到初始響應圖。卷積層的結構如下:
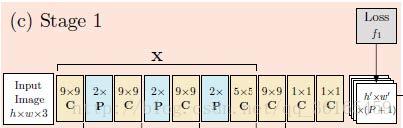
即7層卷積,3層池化層,原始輸入圖片是368*368,經過3次池化得到46*46大小。又因為是半身結構,只有9個關節點,加上背景1,因此輸出的響應圖大小是46*46*10。
Stage2:輸入也是原始圖片,但是在卷積層的中段,加入一個串聯的結構,用來融合三部分的資訊——一是stage1的響應圖,二是階段性卷積結果,三是高斯模版生成的中心約束。這裡比較巧妙的是,串聯後的結果尺度不變,深度變為10+32+1 = 43。
Stage3:輸入的不再是原始圖片,而是stage2的階段性卷積結果,即中間層特徵圖。之後的結構和stage2是一樣。至於stage4也和stage3結構一樣。
訓練細節
1. 資料增強:對原始圖片進行隨機縮放,旋轉,映象
2. 標定:在每個關節點的位置放置一個高斯響應,來構造響應圖的真值。對於含有多個人的影象,生成兩種真值響應,一是在每個人的相應關節位置,放置高斯響應。二是隻在標定的人的相應關節位置,放置高斯響應。
3. 中繼監督,多個loss:如果直接對整個網路進行梯度下降,則輸出層在經過多層反向傳播會大幅度的減小,解決方法就是在每個階段都輸出一個loss,可保證底層引數正常更新。