
RBF(徑向基函式)神經網路
自己的總結:
1、輸入層到隱藏層之間不是通過權值和閾值進行連線的,而是通過輸入樣本與隱藏層點之間的距離(與中心點的距離)連線的。
2、得到距離之後,將距離代入徑向基函式,得到一個數值。數值再與後邊的權值相乘再求總和,就得到了相應輸入的輸出。
3、在訓練網路之前,需要確定中心點的個數,和中心點的位置。以及求出隱藏層各徑向基函式的方差(寬窄程度)。和隱藏層和輸出層之間的權值。
4、中心點個數、中心點位置、方差、權值都可以通過下文所述的方法求出來。
5、徑向基函式也是一種基,可以通過對其線性組合,來對非線性函式進行擬合。
6、RBF神經網路只需要瞭解其中的原理。然後給了訓練資料,求出上述幾個引數,再輸入測試資料,就可以預測輸出了。
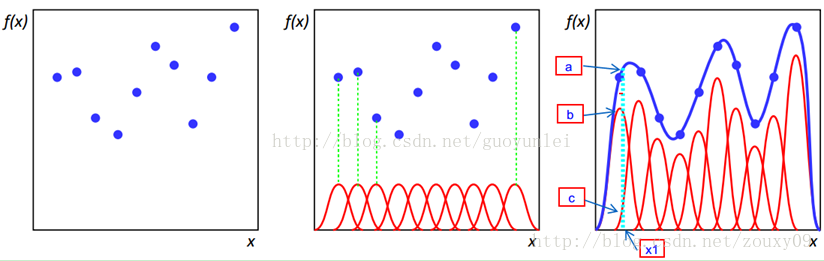
如第三個圖,徑向基函式的
RBF網路能夠逼近任意的非線性函式,可以處理系統內的難以解析的規律性,具有良好的泛化能力,並有很快的學習收斂速度,已成功應用於非線性函式逼近、時間序列分析、資料分類、模式識別、資訊處理、影象處理、系統建模、控制和故障診斷等。
簡單說明一下為什麼RBF網路學習收斂得比較快。當網路的一個或多個可調引數(權值或閾值)對任何一個輸出都有影響時,這樣的網路稱為全域性逼近網路。由於對於每次輸入,網路上的每一個權值都要調整,從而導致全域性逼近網路的學習速度很慢。BP網路就是一個典型的例子。
如果對於輸入空間的某個區域性區域只有少數幾個連線權值影響輸出,則該網路稱為區域性逼近網路。常見的區域性逼近網路有RBF網路、小腦模型(CMAC)網路、B樣條網路等。
徑向基函式解決插值問題
完全內插法要求插值函式經過每個樣本點,即 。樣本點總共有P個。
。樣本點總共有P個。
RBF的方法是要選擇P個基函式,每個基函式對應一個訓練資料,各基函式形式為 ,由於距離是徑向同性的,因此稱為徑向基函式。||X-Xp||表示差向量的模,或者叫2範數。
,由於距離是徑向同性的,因此稱為徑向基函式。||X-Xp||表示差向量的模,或者叫2範數。
基於為徑向基函式的插值函式為:


輸入X是個m維的向量,樣本容量為P,P>m。可以看到輸入資料點Xp是徑向基函式φp的中心。
隱藏層的作用是把向量從低維m對映到高維P,低維線性不可分的情況到高維就線性可分了。
將插值條件代入:

寫成向量的形式為 ,顯然Φ是個規模這P對稱矩陣,且與X的維度無關,當Φ可逆時,有
,顯然Φ是個規模這P對稱矩陣,且與X的維度無關,當Φ可逆時,有 。
。
對於一大類函式,當輸入的X各不相同時,Φ就是可逆的。下面的幾個函式就屬於這“一大類”函式:
1)Gauss(高斯)函式

2)Reflected Sigmoidal(反常S型)函式

3)Inverse multiquadrics(擬多二次)函式

σ稱為徑向基函式的擴充套件常數,它反應了函式影象的寬度,σ越小,寬度越窄,函式越具有選擇性。
完全內插存在一些問題:
1)插值曲面必須經過所有樣本點,當樣本中包含噪聲時,神經網路將擬合出一個錯誤的曲面,從而使泛化能力下降。
由於輸入樣本中包含噪聲,所以我們可以設計隱藏層大小為K,K<P,從樣本中選取K個(假設不包含噪聲)作為Φ函式的中心。

2)基函式個數等於訓練樣本數目,當訓練樣本數遠遠大於物理過程中固有的自由度時,問題就稱為超定的,插值矩陣求逆時可能導致不穩定。
擬合函式F的重建問題滿足以下3個條件時,稱問題為適定的:
- 解的存在性
- 解的唯一性
- 解的連續性
不適定問題大量存在,為解決這個問題,就引入了正則化理論。
正則化理論
正則化的基本思想是通過加入一個含有解的先驗知識的約束來控制對映函式的光滑性,這樣相似的輸入就對應著相似的輸出。
尋找逼近函式F(x)通過最小化下面的目標函式來實現:

加式的第一項好理解,這是均方誤差,尋找最優的逼近函式,自然要使均方誤差最小。第二項是用來控制逼近函式光滑程度的,稱為正則化項,λ是正則化引數,D是一個線性微分運算元,代表了對F(x)的先驗知識。曲率過大(光滑度過低)的F(x)通常具有較大的||DF||值,因此將受到較大的懲罰。
直接給出(1)式的解:

權向量 ********************************(2)
********************************(2)
G(X,Xp)稱為Green函式,G稱為Green矩陣。Green函式與運算元D的形式有關,當D具有旋轉不變性和平移不變性時, 。這類Green函式的一個重要例子是多元Gauss函式:
。這類Green函式的一個重要例子是多元Gauss函式:
 。
。
正則化RBF網路
輸入樣本有P個時,隱藏層神經元數目為P,且第p個神經元採用的變換函式為G(X,Xp),它們相同的擴充套件常數σ。輸出層神經元直接把淨輸入作為輸出。輸入層到隱藏層的權值全設為1,隱藏層到輸出層的權值是需要訓練得到的:逐一輸入所有的樣本,計算隱藏層上所有的Green函式,根據(2)式計算權值。
廣義RBF網路
Cover定理指出:將複雜的模式分類問題非線性地對映到高維空間將比投影到低維空間更可能線性可分。
廣義RBF網路:從輸入層到隱藏層相當於是把低維空間的資料對映到高維空間,輸入層細胞個數為樣本的維度,所以隱藏層細胞個數一定要比輸入層細胞個數多。從隱藏層到輸出層是對高維空間的資料進行線性分類的過程,可以採用單層感知器常用的那些學習規則,參見神經網路基礎和感知器。
注意廣義RBF網路只要求隱藏層神經元個數大於輸入層神經元個數,並沒有要求等於輸入樣本個數,實際上它比樣本數目要少得多。因為在標準RBF網路中,當樣本數目很大時,就需要很多基函式,權值矩陣就會很大,計算複雜且容易產生病態問題。另外廣RBF網與傳統RBF網相比,還有以下不同:
- 徑向基函式的中心不再限制在輸入資料點上,而由訓練演算法確定。
- 各徑向基函式的擴充套件常數不再統一,而由訓練演算法確定。
- 輸出函式的線性變換中包含閾值引數,用於補償基函式在樣本集上的平均值與目標值之間的差別。
因此廣義RBF網路的設計包括:
結構設計--隱藏層含有幾個節點合適
引數設計--各基函式的資料中心及擴充套件常數、輸出節點的權值。
下面給出計算資料中心的兩種方法:
- 資料中心從樣本中選取。樣本密集的地方多采集一些。各基函式採用統一的偏擴充套件常數:

dmax是所選資料中心之間的最大距離,M是資料中心的個數。擴充套件常數這麼計算是為了避免徑向基函式太尖或太平。 - 自組織選擇法,比如對樣本進行聚類、梯度訓練法、資源分配網路等。各聚類中心確定以後,根據各中心之間的距離確定對應徑向基函式的擴充套件常數。

λ是重疊係數。
接下來求權值W時就不能再用 了,因為對於廣義RBF網路,其行數大於列數,此時可以求Φ偽逆。
了,因為對於廣義RBF網路,其行數大於列數,此時可以求Φ偽逆。

資料中心的監督學習演算法
最一般的情況,RBF函式中心、擴充套件常數、輸出權值都應該採用監督學習演算法進行訓練,經歷一個誤差修正學習的過程,與BP網路的學習原理一樣。同樣採用梯度下降法,定義目標函式為

ei為輸入第i個樣本時的誤差訊號。

上式的輸出函式中忽略了閾值。
為使目標函式最小化,各引數的修正量應與其負梯度成正比,即

具體計算式為

上述目標函式是所有訓練樣本引起的誤差總和,匯出的引數修正公式是一種批處理式調整,即所有樣本輸入一輪後調整一次。目標函式也可以為瞬時值形式,即當前輸入引起的誤差

此時引數的修正值為:

下面我們就分別用本文最後提到的聚類的方法和資料中心的監督學習方法做一道練習題。
考慮Hermit多項式的逼近問題

訓練樣本這樣產生:樣本數P=100,xi且服從[-4,4]上的均勻分佈,樣本輸出為F(xi)+ei,ei為新增的噪聲,服從均值為0,標準差為0.1的正態分佈。
(1)用聚類方法求資料中心和擴充套件常數,輸出權值和閾值用偽逆法求解。隱藏節點數M=10,隱藏節點重疊係數λ=1,初始聚類中心取前10個訓練樣本。
#include<iostream>
#include<algorithm>
#include<limits>
#include<cassert>
#include<cmath>
#include<ctime>
#include<cstdlib>
#include<vector>
#include<iomanip>
#include"matrix.h"
using namespace std;
const int P=100;
//輸入樣本的數量
vector<double>
X(P); //輸入樣本
Matrix<double>
Y(P,1); //輸入樣本對應的期望輸出
const int M=10;
//隱藏層節點數目
vector<double>
center(M); //M個Green函式的資料中心
vector<double>
delta(M); //M個Green函式的擴充套件常數
Matrix<double>
Green(P,M); //Green矩陣
Matrix<double>
Weight(M,1); //權值矩陣
/*Hermit多項式函式*/
inline double Hermit(double x){
相關推薦RBF(徑向基函式)神經網路自己的總結: 1、輸入層到隱藏層之間不是通過權值和閾值進行連線的,而是通過輸入樣本與隱藏層點之間的距離(與中心點的距離)連線的。 2、得到距離之後,將距離代入徑向基函式,得到一個數值。數值再與後邊的權值相乘再求總和,就得到了相應輸入的輸出。 3、在訓練網路之前,需要確定中心點的個數,和中心點 高斯核函式(徑向基函式)數學表示所謂徑向基函式 (Radial Basis Function 簡稱 RBF), 就是某種沿徑向對稱的標量函式。 通常定義為空間中任一點x到某一中心xc之間歐氏距離的單調函式 , 可記作 k(||x-xc||), 其作用往往是區域性的 , 即當x遠離xc時函式取值很 (python原始碼)基於tensorflow的徑向基向量bp神經網路基於tensorflow的rbf神經網路_python原始碼實現該網路結果比較簡單,輸入層--徑向基層--輸出層,其中需要迭代優化的是:“徑向基層”--“輸出層”之間的權重(weights和biases)。#encoding:utf-8 import numpy as np 吳恩達機器學習(第十章)---神經網路的反向傳播演算法一、簡介 我們在執行梯度下降的時候,需要求得J(θ)的導數,反向傳播演算法就是求該導數的方法。正向傳播,是從輸入層從左向右傳播至輸出層;反向傳播就是從輸出層,算出誤差從右向左逐層計算誤差,注意:第一層不計算,因為第一層是輸入層,沒有誤差。 二、如何計算 設為第l層,第j個的誤差。 吳恩達機器學習(第九章)---神經網路神經網路是非線性的分類演算法。模擬人類的神經系統進行計算。 1、原因 當特徵數很大的時候(比如100個),那麼在假設函式的時候要考慮太多項,包含x1x2,x1x3,x2x3等等,不能僅僅單個考慮x1,x2等,這樣一來,在擬合過程中的計算量就會非常大。 2、基本概念 其中,藍色的 (轉載)(牆裂推薦)神經網路的基本工作原理作者:SoftwareTeacher 來源:CSDN 原文:https://blog.csdn.net/SoftwareTeacher/article/details/83991254 版權宣告:本文為博主原創文章,轉載請附上博文連結! --------------- 徑向基函式(RBF)神經網路RBF網路能夠逼近任意的非線性函式,可以處理系統內的難以解析的規律性,具有良好的泛化能力,並有很快的學習收斂速度,已成功應用於非線性函式逼近、時間序列分析、資料分類、模式識別、資訊處理、影象處理、系統建模、控制和故障診斷等。 簡單說明一下為什麼RBF網路學習收斂得比較快。當網路的一個或多個可調引數(權值或閾 神經網路學習筆記(五) 徑向基函式神經網路徑向基函式神經網路 首先介紹一下網路結構: 1.輸入層為向量,維度為m,樣本個數為n,線性函式為傳輸函式。 2.隱藏層與輸入層全連線,層內無連線,隱藏層神經元個數與樣本個數相等,也就是n,傳輸函式為徑向基函式。 3.輸出層為線性輸出。 理論 徑向基(RBF)神經網路RBF網路能夠逼近任意非線性的函式。可以處理系統內難以解析的規律性,具有很好的泛化能力,並且具有較快的學 習速度。當網路的一個或多個可調引數(權值或閾值)對任何一個輸出都有影響時,這樣的網路稱為全域性逼近網路。 由於對於每次輸入,網路上的每一個權值都要調整,從而導致全域性逼 神經網路學習筆記(一) RBF徑向基函式神經網路RBF徑向基函式神經網路 初學神經網路,以下為綜合其他博主學習材料及本人理解所得。 一、RBF神經網路的基本思想 1. 用RBF作為隱單元的“基”構成隱含層空間,將輸入向量直接(不通過權對映)對映到隱空間。 2.當RBF的中心點確定後,對映關係也就確定。(中心點通常通 徑向基(RBF)神經網路python實現from numpy import array, append, vstack, transpose, reshape, \ dot, true_divide, mean, exp, sqrt, log, \ loadtxt, savet 深度學習之徑向基函式神經網路RBFNN徑向基函式(Radial Basis Function)神經網路是具有唯一最佳逼近(克服區域性極小值問題)、訓練簡潔、學習收斂速度快等良好效能的前饋型神經網路,目前已證明RBFNN能夠以任意精度逼近任意連續的非線性網路,被廣泛用於函式逼近、語音識別、模式識別、影象處理、自 pytorch入門(2)-------神經網路的構建https://blog.csdn.net/broken_promise/article/details/81174760 一、神經網路的構建: 激勵函式的選擇,如果層數較少的神經網路,激勵函式有多種選擇,在影象卷積神經網路中,激勵函式選擇ReLu,在迴圈神經網路中,選擇ReL或者Tanh。 所有的層結 深度學習筆記(四)——神經網路和深度學習(淺層神經網路)1.神經網路概覽 神經網路的結構與邏輯迴歸類似,只是神經網路的層數比邏輯迴歸多一層,多出來的中間那層稱為隱藏層或中間層。從計算上來說,神經網路的正向傳播和反向傳播過程只是比邏輯迴歸多了一次重複的計算。正向傳播過程分成兩層,第一層是輸入層到隱藏層,用上標[1]來表示;第二層是隱藏層到輸出層,用上標 (轉載)深度學習基礎(3)——神經網路和反向傳播演算法原文地址:https://www.zybuluo.com/hanbingtao/note/476663 轉載在此的目的是自己做個筆記,日後好複習,如侵權請聯絡我!! 在上一篇文章中,我們已經掌握了機器學習的基本套路,對模型、目標函式、優化演算法這些概念有了一定程度的理解,而且已經會訓練單個的感知器或者 Keras搭建第一個分類(Classification)神經網路(mnist手寫體數字分類)我們使用mnist資料集,這個資料集有手寫體數字0-9的圖片,一共10類,我們對這個資料集中的手寫體數字圖片進行分類。 如果mnist資料集無法自動下載,可能是因為from keras.datasets import mnist自動下載資料集的網址被牆,請手動下載並按下面程式碼中註釋進行相應 四.徑向基函式網路BP神經網路是一種全域性逼近網路,學習速度慢,本次介紹一種結構簡單,收斂速度快,能夠逼近任意非線性函式的網路——徑向基函式網路。(Radial Basis Function, RBF)是根據生物神經元有區域性響應的原理而將基函式引入到神經網路中。 為什麼RBF網路學習收斂得比較快?當網路的一個或多個可調引數 吳恩達深度學習筆記(3)-神經網路如何實現監督學習?神經網路的監督學習(Supervised Learning with Neural Networks) 關於神經網路也有很多的種類,考慮到它們的使用效果,有些使用起來恰到好處,但事實表明,到目前幾乎所有由神經網路創造的經濟價值,本質上都離不開一種叫做監督學習的機器學習類別,讓我們舉例看看。 機器學習筆記(六)神經網路引入及多分類問題實踐一、 神經網路引入 我們將從計算機視覺直觀的問題入手,提出引入非線性分類器的必要性。首先,我們希望計算機能夠識別圖片中的車。顯然,這個問題對於計算機來說是很困難的,因為它只能看到畫素點的數值。 應用機器學習,我們需要做的就是提供大量帶標籤的圖片作為訓練集,有的圖片是一輛車,有的圖片不是一輛車,最終我們 吳恩達《神經網路與深度學習》課程筆記歸納(二)-- 神經網路基礎之邏輯迴歸上節課我們主要對深度學習(Deep Learning)的概念做了簡要的概述。我們先從房價預測的例子出發,建立了標準的神經網路(Neural Network)模型結構。然後從監督式學習入手,介紹了Standard NN,CNN和RNN三種不同的神經網路模型。接著介紹了兩種不 |