
spark1.2.0版本搭建偽分散式環境
2、安裝和配置scala:
第一步:上傳scala安裝包 並解壓


第二步 配置SCALA_HOME環境變數到bash_profile

第三步 source 使配置環境變數生效:

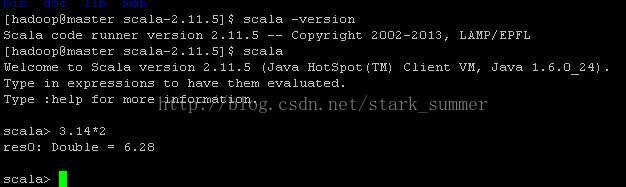
第四步 驗證scala:
4、安裝和配置spark:
第一步 解壓spark:


第二步 配置SPARK_HOME環境變數:

第三步 使用source生效:

進入spark的conf目錄:
第四步 修改slaves檔案,首先開啟該檔案:


slaves修改後:

第五步 配置spark-env.sh
首先把spark-env.sh.template拷貝到spark-env.sh:

然後 開啟“spark-env.sh”檔案:
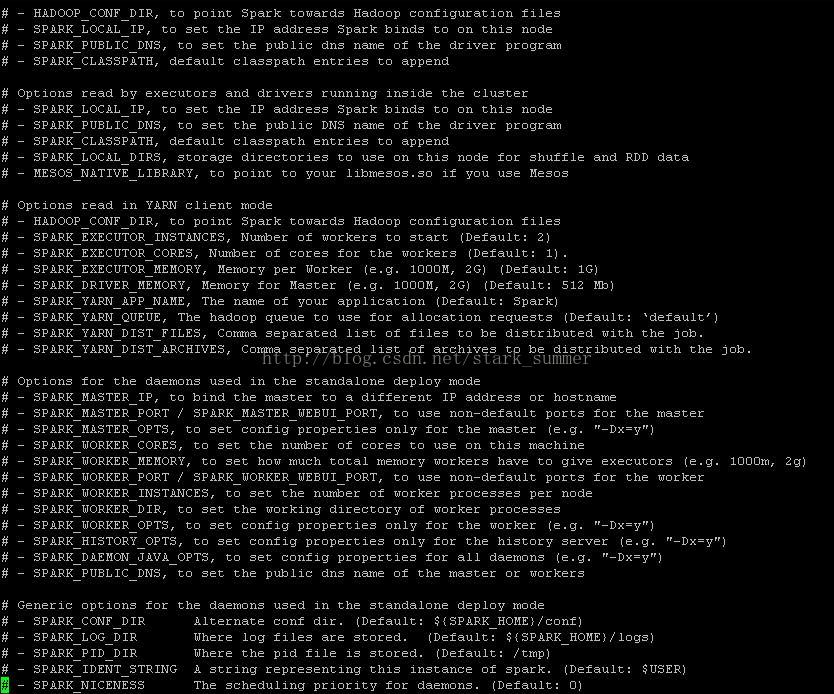
spark-env.sh檔案修改後:

5、啟動spark偽分散式幫檢視資訊:
第一步 先保證hadoop叢集或者偽分散式啟動成功,使用jps看下程序資訊:

如果沒有啟動,進入hadoop的sbin目錄執行 ./start-all.sh
第二步 啟動spark:
進入spark的sbin目錄下執行“start-all.sh”:
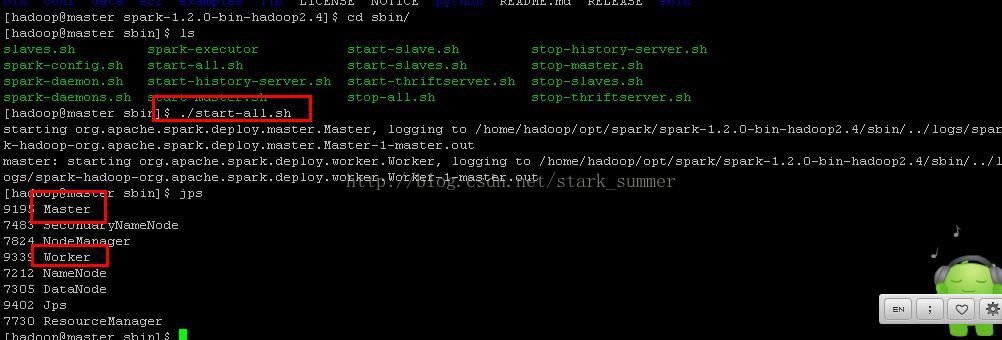
此刻 我們看到有新程序“Master” 和"Worker"
我們訪問“http://master:8080/”,進如spark的web控制檯頁面:

從頁面上可以看到一個Worker節點的資訊。
我們進入spark的bin目錄,使用“spark-shell”控制檯:
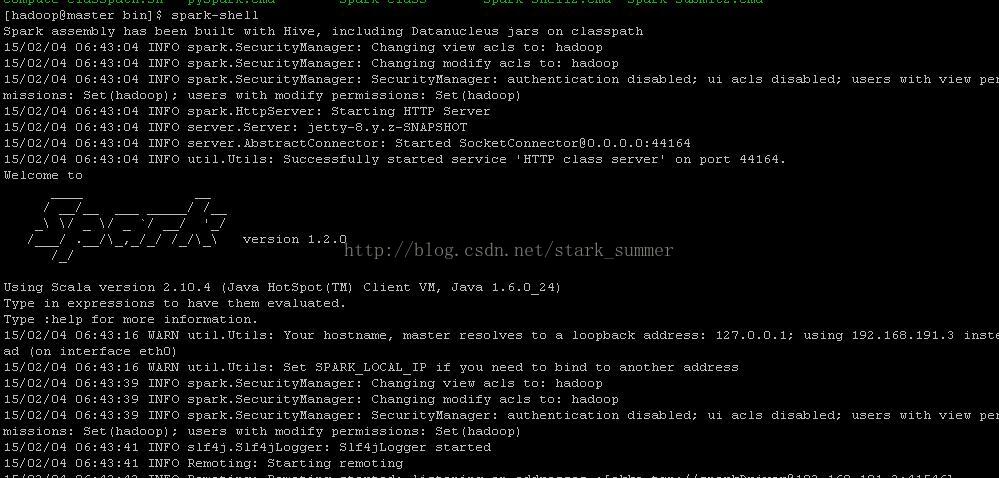

通過訪問"http://master:4040",進入spark-shell web控制檯頁面:
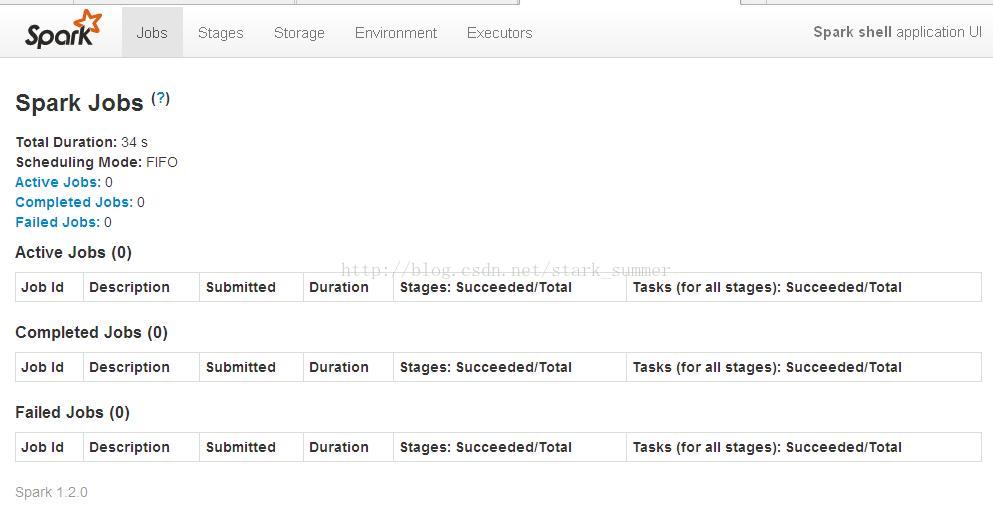
6、測試spark偽分散式:
我們使用之前上傳到hdfs中的/data/test/README.txt檔案進行mapreduce
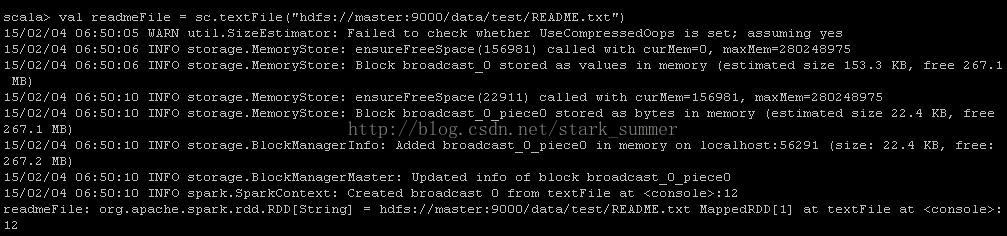
取得hdfs檔案:

對讀取的檔案進行一下操作:
使用collect命令提交併執行job:
readmeFile.collect

檢視spark-shell web控制檯:
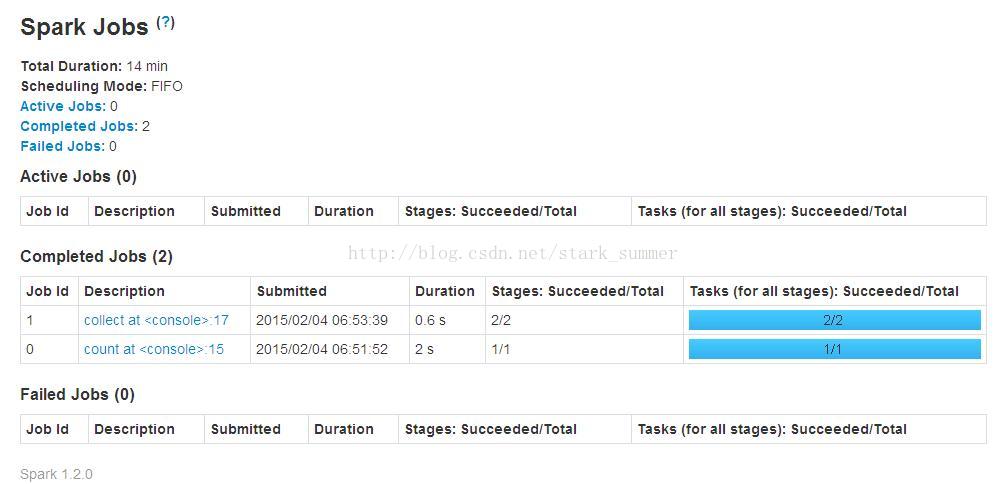
states:

埠整理:
master埠是7077
master webui是8080
spark shell webui埠是4040