
深入理解——召回率(recall) 準確率(precision) 精度(accuracy) 錯誤率(error)
精度(accuracy)和錯誤率(error)
這個最常用,用在常見的分類任務中,比如有雞,鴨,鵝,狗,貓若干,讓模型一一回答他們的類別,見到扁嘴脖子長還會嘎嘎叫的,回答為鴨,預測正確,否則回答錯誤。最後 (回答正確個數) 除以 (雞鴨鵝狗貓總數) = 精度.

錯誤率則是1-精度
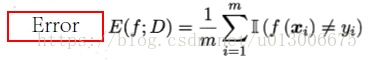
儘管精度或錯誤率能夠衡量模型的分類能力,但很多場景下精度高並不代表這個模型就好。舉個例子,比如在病情診斷過程中,需要模型判斷體檢樣片呈現的是“健康”,“早期”,還是“晚期”三個情況,該模型能夠到達95%的精度,即給100個樣片,能夠保證誤判控制在5個以內。看似很不錯,但是體檢有一個特點,就是大多數人都是健康的,即我哪怕瞎猜都健康也能達到至少80%的精度,但事實上漏掉的那些才是真正important的,所以我們進一步需要查準率和查全率這樣的指標。
查準率(precision)和查全率(recall)
先搬一段周志華書中的解釋,其實已經解釋的非常好了,下面我依據個人理解再進一步補充一些。



什麼時候查準率會很高,那就是隻挑選最有把握的,比如在安防監控異常事件監測時,在模型訓練好之後投入使用時,你可以調整閾值,使模型選擇得分最高的一些場景報警,而忽略那些不太有把握的,此時在預測了100個場景之後,很可能模型只報警了10次,在這10次報警中有8次確實是危險場景,即正確報警(TP),另外2次則是誤報(FP),即並沒有危險事件發生,這時候查準率就會很高,為8/10=80%。但是我們會發現,剩下90次未報警的場景中,會有很多得分偏低但確實有危險發生的場景被未報警,比如有30次漏掉(FN)的話,那查全率就是8/(8+30)=21.05%,這時就是為了查準而放棄了很多可疑場景,導致查全率特別低。
所以,查準率和查全率往往是一對矛盾的量,想要保證查準率就需要捨棄一些查全率,在實際應用中,需要設定好閾值,也就是在“不要亂報”(得分很高時才報,拿不準的就放過,此時查準率高)和“寧可錯殺一千,不可放過一個”(只要得分足夠高,就列為嫌疑犯,此時查全率高)中做好權衡。
那有沒有可能使這兩者同時高呢?當然有可能,這取決於你模型的能力,設想下面幾種情況:假設你訓練的模型是上帝,對所有的二分類問題都能準確的回答是或不是,也就是能做到Accuracy為100%。在這種情況下,就能保證查準率和查全率同為為100%。此時,如果模型的能力略有降低,Accuracy降到95%左右,此時模型在對100個視訊做了預測之後,報警35次,其中有33次是正確的(TP),2次是誤報,另外還有5次漏報,則此時查準率為33/35=94.3%,查全率為33/38=86.9。也就是說盡管二者是矛盾的,但他的的表現和Accuracy有著必然的聯絡。如果你的模型預測能力很差,那麼如果你想保證較高的查準率,這必須大幅度犧牲查全率,反過來也是一樣,要想保證查全率,就要大幅犧牲查準率;但如果你的模型預測能力還可以,那麼二者相互犧牲的代價就不會那麼大;一旦你的模型預測能力報表,則相互犧牲的程度就更低,甚至可以使二者都很高。所以Accuracy是查準率和查全率的重要保證。
誤報率 漏報率
在真正理解了這兩個量之後,還有必要了解一下誤報率(虛報率)和漏報率,誤報率=1-查準率,漏報率=1-查全率。
這些個概念恐怕用久了之後才能真正理解和掌握,筆者也是邊學邊理解和記錄,其中一定有錯誤的地方,希望大家及時質疑和指正, 共同進步~