
推薦系統中的矩陣分解
阿新 • • 發佈:2019-01-27
在推薦場景中, 我們可以把user對item的行為, 用評分矩陣表示.
,為使用者集合, , 為item集合.
以商品為例,比如說使用者u1對商品p1加購物車, 那就令 , 使用者u1對商品p2做出購買行為, 那就令 .
問題描述
在真實場景中, 使用者只會對部分item做出反饋, 所以矩陣是非常稀疏的.
推薦的task就是預測出使用者可能感興趣的未見商品.
我們假設使用者喜歡某個商品是因為使用者的特徵偏好與該商品的特徵能夠吻合起來.
那這些特徵是什麼呢? 以音樂推薦為例, 見圖1
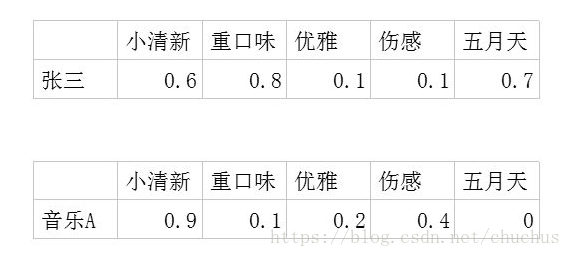
figure 1 音樂推薦中, latent space 的一種假設
這些特徵我們不必人為定義, 可以引入latent space的假定, 有個潛在的特徵.
使用者對每個特徵都有一個偏好程度, 用矩陣表示, 每個物品都有一個特徵的吻合程度, 用表示,所以我們的任務就是求出這兩個矩陣, 然後對進行補全, 找出得分高的未見商品推薦給使用者.
問題定義
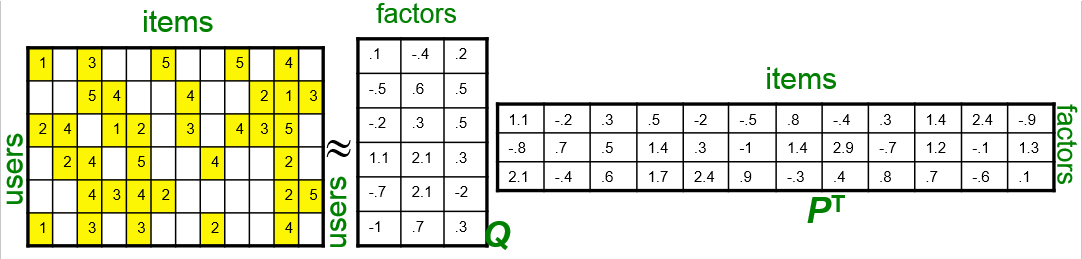
figure 矩陣分解示意, 網路盜圖,符號跟上面公式不一樣
求解方法
式1 為目標函式. 求解方法通常為 alternating least squares (ALS), 交替最小二乘法.