svm演算法 最通俗易懂講解
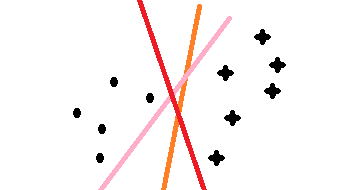
最近在學習svm演算法,藉此文章記錄自己的學習過程,在學習很多處借鑑了z老師的講義和李航的統計,若有不足的地方,請海涵;svm演算法通俗的理解在二維上,就是找一分割線把兩類分開,問題是如下圖三條顏色都可以把點和星劃開,但哪條線是最優的呢,這就是我們要考慮的問題;
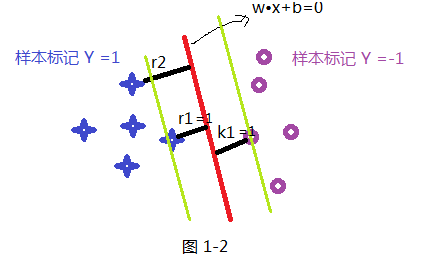
首先我們先假設一條直線為 W•X+b =0 為最優的分割線,把兩類分開如下圖所示,那我們就要解決的是怎麼獲取這條最優直線呢?及W 和 b 的值;在SVM中最優分割面(超平面)就是:能使支援向量和超平面最小距離的最大值;
我們的目標是尋找一個超平面,使得離超平面比較近的點能有更大的間距。也就是我們不考慮所有的點都必須遠離超平面,我們關心求得的超平面能夠讓所有點中離它最近的點具有最大間距。
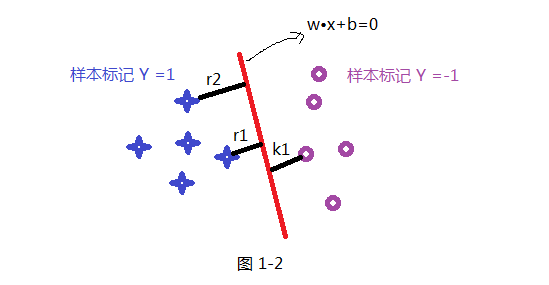
如上面假設藍色的星星類有5個樣本,並設定此類樣本標記為Y =1,紫色圈類有5個樣本,並設定此類標記為 Y =-1,共 T ={(X₁ ,Y₁) , (X₂,Y₂) (X₃,Y₃) .........} 10個樣本,超平面(分割線)為wx+b=0; 樣本點到超平面的幾何距離為:
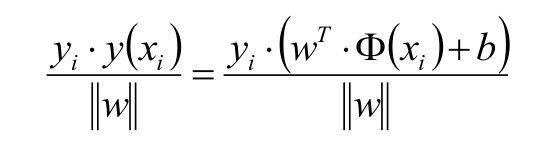
此處要說明一下:函式距離和幾何距離的關係;定義上把 樣本| w▪x₁+b|的距離叫做函式距離,而上面公式為幾何距離,你會發現當w 和b 同倍數增加時候,函式距離也會通倍數增加;簡單個例子就是,樣本 X₁ 到 2wX₁+2b
=0的函式距離是wX₁ +b =0的函式距離的 2倍;而幾何矩陣不變;
下面我們就要談談怎麼獲取超平面了?!
超平面就是滿足支援向量到其最小距離最大,及是求:max [支援向量到超平面的最小距離] ;那隻要算出支援向量到超平面的距離就可以了吧 ,而支援向量到超平面的最小距離可以表示如下公式:
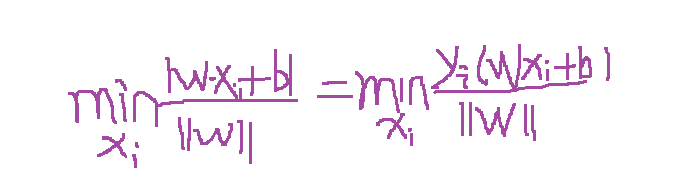
故最終優化的的公式為:
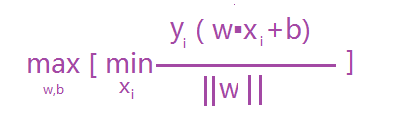
根據函式距離和幾何距離可以得知,w和b增加時候,幾何距離不變,故怎能通過同倍數增加w和 b使的支援向量(距離超平面最近的樣本點)上樣本代入 y(w*x+b) =1,而不影響上面公式的優化,樣本點距離如下:如上圖其r1函式距離為1,k1函式距離為1,而其它
樣本點的函式距離大於1,及是:y(w•x+b)>=1,把此條件代入上面優化公式候,可以獲取新的優化公式1-3:
公式1-3見下方:優化最大化分數,轉化為優化最小化分母,為了優化方便轉化為公式1-4
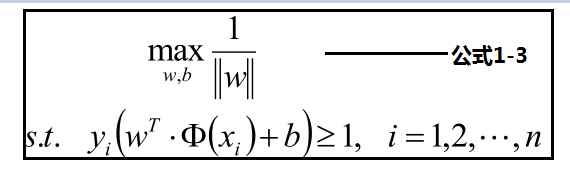
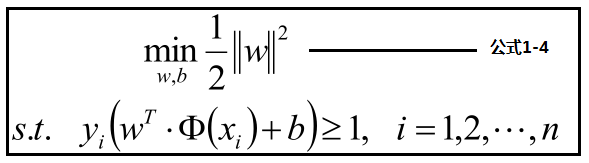
為了優化上面公式,使用拉格朗日公式和KTT條件優化公式轉化為:
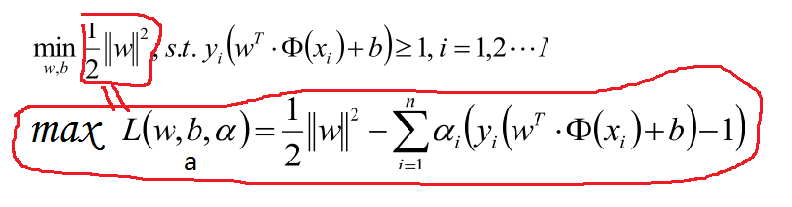
對於上面的優化公式在此說明一下:比如我們的目標問題是 minf(x)。可以建構函式L(a,b,x):
L(a,b,x)=f(x)+a⋅g(x)+b⋅h(x),a≥0此時 f(x)
與 maxa,bL(a,b,x)
是等價的。因為 h(x)=0,g(x)≤0,a⋅g(x)≤0,所以只有在a⋅g(x)=0
的情況下
L(a,b,x) 才能取得最大值,因此我們的目標函式可以寫為minxmaxa,bL(a,b,x)。如果用對偶表示式:maxa,bminxL(a,b,x),
由於我們的優化是滿足強對偶的(強對偶就是說對偶式子的最優值是等於原問題的最優值的),所以在取得最優值x∗
的條件下,它滿足 :
f(x∗)=maxa,bminxL(a,b,x)=minxmaxa,bL(a,b,x)=f(x∗),
結合上面的一度的對偶說明故我們的優化函式如下面,其中a >0
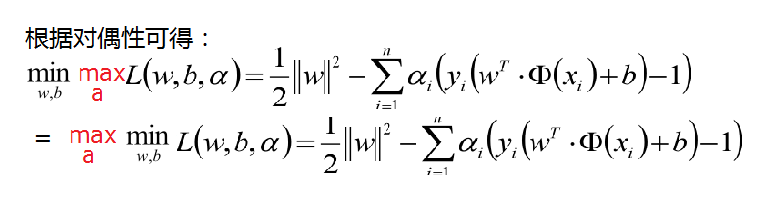
現在的優化方案到上面了,先求最小值,對 w 和 b 分別求偏導可以獲取如下公式:
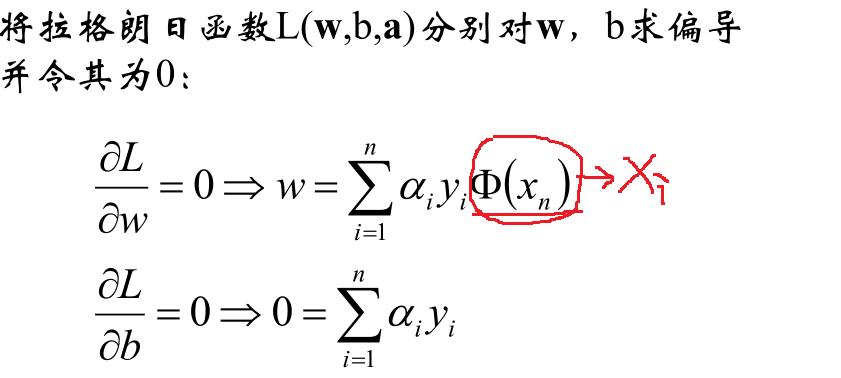
把上式獲取的引數代入公式優化max值:
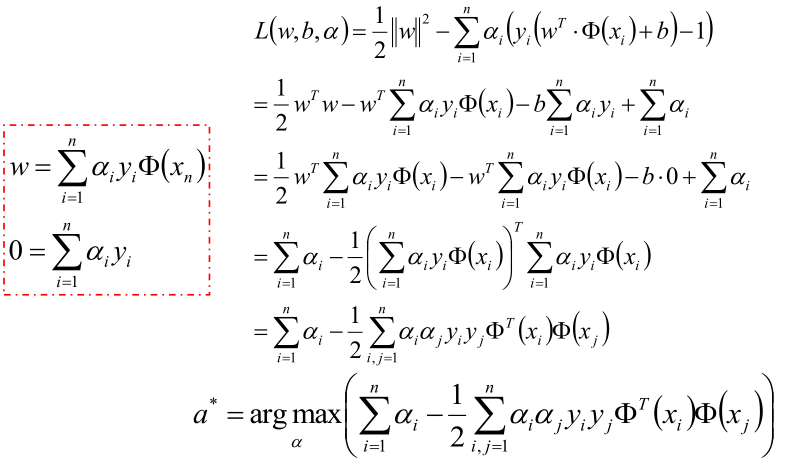
化解到最後一步,就可以獲取最優的a值:


以上就可以獲取超平面!
但在正常情況下可能存在一些特異點,將這些特異點去掉後,剩下的大部分點都能線性可分的,有些點線性不可以分,意味著此點的函式距離不是大於等於1,而是小於1的,為了解決這個問題,我們引進了鬆弛變數 ε>=0; 這樣約束條件就會變成為:
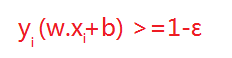
故原先的優化函式變為:
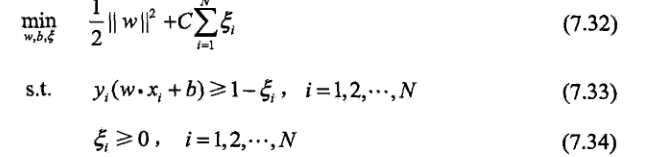
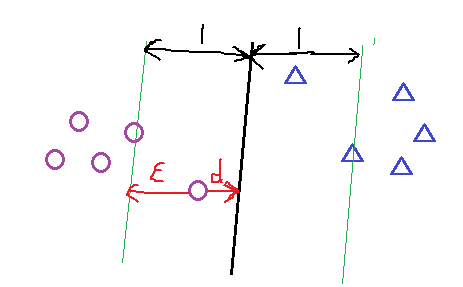
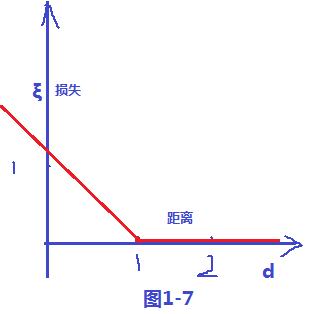
對加入鬆弛變數後有幾點說明如下圖所以;距離小於1的樣本點離超平面的距離為d ,在綠線和超平面之間的樣本點都是由損失的,
其損失變數和距離d 的關係,可以看出 ξ = 1-d , 當d >1的時候會發現ξ =0,當 d<1 的時候
ξ = 1-d ;故可以畫出損失函式圖,如下圖1-7;樣式就像翻書一樣,我們把這個損失函式叫做 hinge損失;
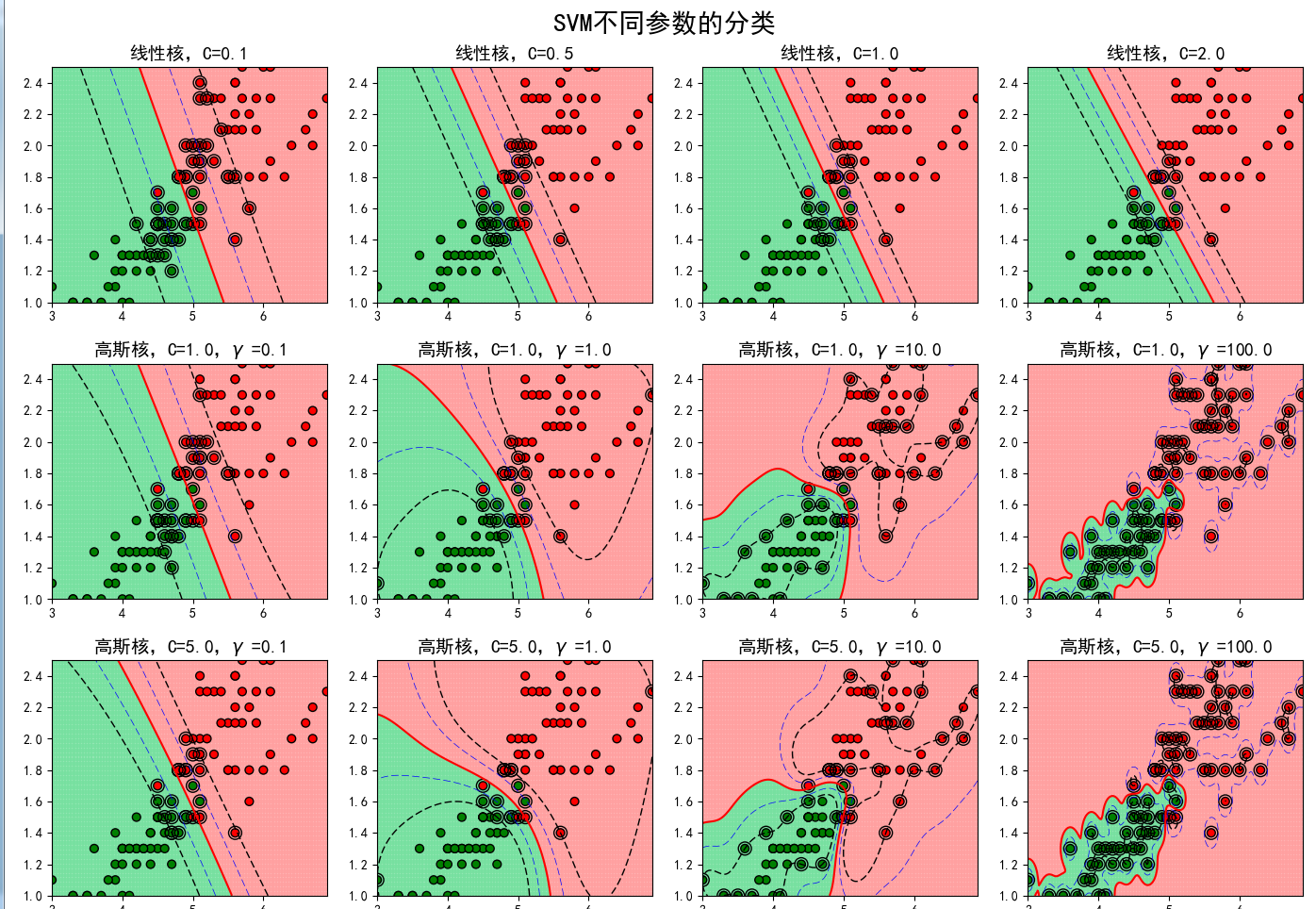
下面我們簡單的就來討論一下核函式:核函式的作用其實很簡單就是把低維對映到高維中,便於分類。核函式有高斯核等,下面就直接上圖看引數對模型的影響,從下圖可以瞭解,當C變化時候,容錯變小,泛化能力變小;當選擇高斯核函式的時候,隨時R引數調大,準確高提高,最終有過擬合風險;
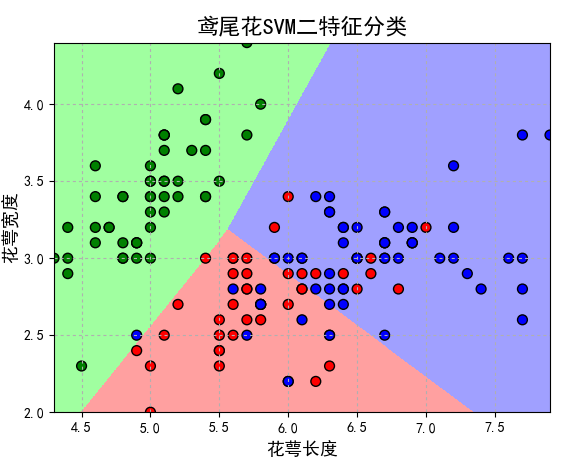
下面就直接上程式碼了(鳶尾花SVM二特徵分類):
iris_feature = u'花萼長度', u'花萼寬度', u'花瓣長度', u'花瓣寬度'
if __name__ == "__main__":
path = 'iris.data' # 資料檔案路徑
data = pd.read_csv(path, header=None)
x, y = data[range(4)], data[4]
y = pd.Categorical(y).codes
x = x[[0, 1]]
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1, train_size=0.6)
# 分類器
clf = svm.SVC(C=0.3, kernel='linear', decision_function_shape='ovo')
clf.fit(x_train, y_train.ravel())
# 準確率
print clf.score(x_train, y_train) # 精度
print '訓練集準確率:', accuracy_score(y_train, clf.predict(x_train))
print clf.score(x_test, y_test)
print '測試集準確率:', accuracy_score(y_test, clf.predict(x_test))
x1_min, x2_min = x.min()
x1_max, x2_max = x.max()
x1, x2 = np.mgrid[x1_min:x1_max:500j, x2_min:x2_max:500j] # 生成網格取樣點
grid_test = np.stack((x1.flat, x2.flat), axis=1) # 測試點
print 'grid_test = \n', grid_test
Z = clf.decision_function(grid_test)
Z = Z[:,0].reshape(x1.shape)
print "decision_function:",Z
grid_hat = clf.predict(grid_test)
grid_hat = grid_hat.reshape(x1.shape)
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
plt.figure(facecolor='w')
plt.pcolormesh(x1, x2, grid_hat, cmap=cm_light)
plt.scatter(x[0], x[1], c=y, edgecolors='k', s=50, cmap=cm_dark) # 樣本
plt.scatter(x_test[0], x_test[1], s=120, facecolors='none', zorder=10) # 圈中測試集樣本
plt.xlabel(iris_feature[0], fontsize=13)
plt.ylabel(iris_feature[1], fontsize=13)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.title(u'鳶尾花SVM二特徵分類', fontsize=16)
plt.grid(b=True, ls=':')
plt.show()