
關於召回率和準確率的理解
最近一直在做相關推薦方面的研究與應用工作,召回率與準確率這兩個概念偶爾會遇到,
知道意思,但是有時候要很清晰地向同學介紹則有點轉不過彎來。
召回率和準確率是資料探勘中預測、網際網路中的搜尋引擎等經常涉及的兩個概念和指標。
召回率:Recall,又稱“查全率”——還是查全率好記,也更能體現其實質意義。
準確率:Precision,又稱“精度”、“正確率”。
以檢索為例,可以把搜尋情況用下圖表示:
| 相關 | 不相關 | |
| 檢索到 | A | B |
| 未檢索到 | C | D |
A:檢索到的,相關的 (搜到的也想要的)
B:檢索到的,但是不相關的 (搜到的但沒用的)
C:未檢索到的,但卻是相關的 (沒搜到,然而實際上想要的)
D:未檢索到的,也不相關的 (沒搜到也沒用的)
如果我們希望:被檢索到的內容越多越好,這是追求“查全率”,即A/(A+C),越大越好。
如果我們希望:檢索到的文件中,真正想要的、也就是相關的越多越好,不相關的越少越好,
這是追求“準確率”,即A/(A+B),越大越好。
“召回率”與“準確率”雖然沒有必然的關係(從上面公式中可以看到),在實際應用中,是相互制約的。
要根據實際需求,找到一個平衡點。
往往難以迅速反應的是“召回率”。我想這與字面意思也有關係,從“召回”的字面意思不能直接看到其意義。
“召回”在中文的意思是:把xx調回來。“召回率”對應的英文“recall”,
recall除了有上面說到的“order sth to return”的意思之外,還有“remember”的意思。
Recall:the ability to remember sth. that you have learned or sth. that has happened in the past.當我們問檢索系統某一件事的所有細節時(輸入檢索query查詢詞),
Recall指:檢索系統能“回憶”起那些事的多少細節,通俗來講就是“回憶的能力”。
“能回憶起來的細節數” 除以 “系統知道這件事的所有細節”,就是“記憶率”,
也就是recall——召回率。簡單的,也可以理解為查全率。
根據自己的知識總結的,定義應該肯定對了,在某些表述方面可能有錯誤的地方。
假設原始樣本中有兩類,其中:
1:總共有 P個類別為1的樣本,假設類別1為正例。
2:總共有N個類別為0 的樣本,假設類別0為負例。
經過分類後:
3:有 TP個類別為1 的樣本被系統正確判定為類別1,FN 個類別為1 的樣本被系統誤判定為類別 0,
顯然有P=TP+FN;
4:有 FP 個類別為0 的樣本被系統誤判斷定為類別1,TN 個類別為0 的樣本被系統正確判為類別 0,
顯然有N=FP+TN;
那麼:
精確度(Precision):
P = TP/(TP+FP) ; 反映了被分類器判定的正例中真正的正例樣本的比重(
準確率(Accuracy)
A = (TP + TN)/(P+N) = (TP + TN)/(TP + FN + FP + TN);
反映了分類器統對整個樣本的判定能力——能將正的判定為正,負的判定為負
召回率(Recall),也稱為 True Positive Rate:
R = TP/(TP+FN) = 1 - FN/T; 反映了被正確判定的正例佔總的正例的比重
轉移性(Specificity,不知道這個翻譯對不對,這個指標用的也不多),
也稱為 True NegativeRate
S = TN/(TN + FP) = 1 – FP/N; 明顯的這個和召回率是對應的指標,
只是用它在衡量類別0 的判定能力。
F-measure or balanced F-score
F = 2 * 召回率 * 準確率/ (召回率+準確率);這就是傳統上通常說的F1 measure,
需要有不同的指標。 當總共有個100 個樣本(P+N=100)時,假如只有一個正例(P=1),
那麼只考慮精確度的話,不需要進行任何模型的訓練,直接將所有測試樣本判為正例,
那麼 A 能達到 99%,非常高了,但這並沒有反映出模型真正的能力。另外在統計訊號分析中,
對不同類的判斷結果的錯誤的懲罰是不一樣的。舉例而言,雷達收到100個來襲 導彈的訊號,
其中只有 3個是真正的導彈訊號,其餘 97 個是敵方模擬的導彈訊號。假如系統判斷 98 個
(97 個模擬訊號加一個真正的導彈訊號)訊號都是模擬訊號,那麼Accuracy=98%,
很高了,剩下兩個是導彈訊號,被截掉,這時Recall=2/3=66.67%,
Precision=2/2=100%,Precision也很高。但剩下的那顆導彈就會造成災害。
因此在統計訊號分析中,有另外兩個指標來衡量分類器錯誤判斷的後果:
漏警概率(Missing Alarm)
MA = FN/(TP + FN) = 1 – TP/T = 1 - R; 反映有多少個正例被漏判了
(我們這裡就是真正的導彈訊號被判斷為模擬訊號,可見MA此時為 33.33%,太高了)
虛警概率(False Alarm)
FA = FP / (TP + FP) = 1 – P;反映被判為正例樣本中,有多少個是負例。
統計訊號分析中,希望上述的兩個錯誤概率儘量小。而對分類器的總的懲罰舊
是上面兩種錯誤分別加上懲罰因子的和:COST = Cma *MA + Cfa * FA。
不同的場合、需要下,對不同的錯誤的懲罰也不一樣的。像這裡,我們自然希望對漏警的懲罰大,
因此它的懲罰因子 Cma 要大些。
個人觀點:雖然上述指標之間可以互相轉換,但在模式分類中,
一般用 P、R、A 三個指標,不用MA和 FA。而且統計訊號分析中,也很少看到用 R 的。
好吧,其實我也不是IR專家,但是我喜歡IR,最近幾年國內這方面研究的人挺多的,google和百度的強勢,也說明了這個方向的價值。當然,如果你是學IR的,不用看我寫的這些基礎的東西咯。如果你是初學者或者是其他學科的,正想了解這些科普性質的知識,那麼我這段時間要寫的這個"資訊檢索X科普"系列也許可以幫助你。(我可能寫的不是很快,見諒)
至於為什麼名字中間帶一個字母X呢? 
為什麼先講Precision和Recall呢?因為IR中很多演算法的評估都用到Precision和Recall來評估好壞。所以我先講什麼是"好人",再告訴你他是"好人"
查準與召回(Precision & Recall)
先看下面這張圖來理解了,後面再具體分析。下面用P代表Precision,R代表Recall
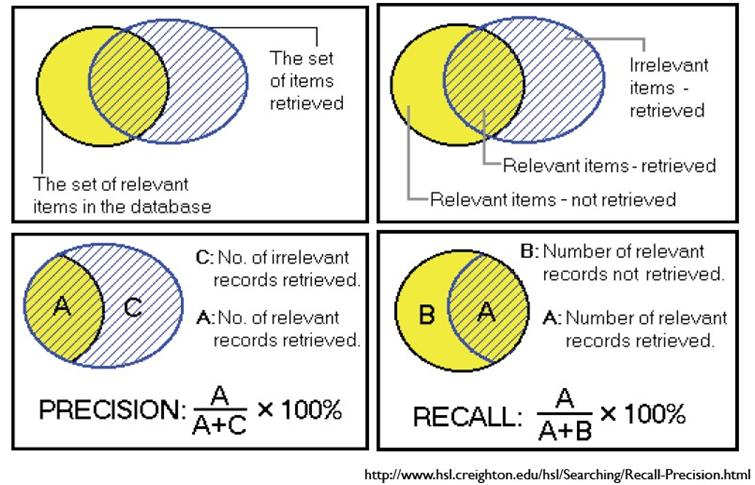
通俗的講,Precision 就是檢索出來的條目中(比如網頁)有多少是準確的,Recall就是所有準確的條目有多少被檢索出來了。
下面這張圖介紹True Positive,False Negative等常見的概念,P和R也往往和它們聯絡起來。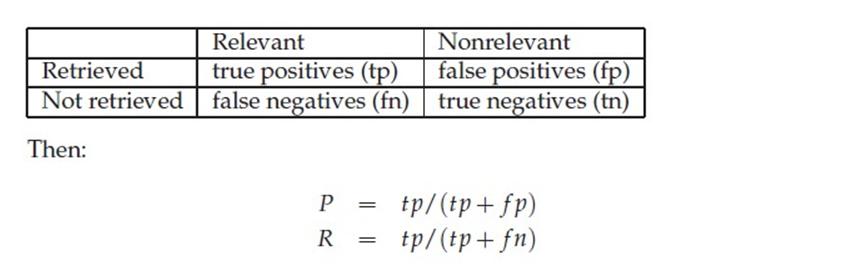
我們當然希望檢索的結果P越高越好,R也越高越好,但事實上這兩者在某些情況下是矛盾的。比如極端情況下,我們只搜出了一個結果,且是準確的,那麼P就是100%,但是R就很低;而如果我們把所有結果都返回,那麼必然R是100%,但是P很低。
因此在不同的場合中需要自己判斷希望P比較高還是R比較高。如果是做實驗研究,可以繪製Precision-Recall曲線來幫助分析(我應該會在以後介紹)。
F1 Measure
前面已經講了,P和R指標有的時候是矛盾的,那麼有沒有辦法綜合考慮他們呢?我想方法肯定是有很多的,最常見的方法應該就是F Measure了,有些地方也叫做F Score,都是一樣的。
F Measure是Precision和Recall加權調和平均:
F = (a^2+1)P*R / a^2P +R
當引數a=1時,就是最常見的F1了:
F1 = 2P*R / (P+R)
很容易理解,F1綜合了P和R的結果。