
降維方法-LDA線性判別分析
降維-LDA線性判別分析
【機器學習】LDA線性判別分析
1. LDA的基本思想
2. LDA求解方法
3. 將LDA推廣到多分類
4. LDA算法流程
5. LDA和PCA對比
【附錄1】瑞利商與廣義瑞利商
線性判別分析 (Linear Discriminant Analysis,LDA)是一種經典的線性學習方法,在二分類問題上因為最早由[Fisher,1936]提出,亦稱"Fisher判別分析"。(嚴格說來LDA與Fisher判別分析稍有不同,LDA假設了各類樣本的協方差矩陣相同且滿秩。)
1. LDA的基本思想
LDA的基本思想是: 給定訓練樣例集,設法將樣例投影到一條直線上,使得同類樣例的投影點盡可能接近、異類樣例的投影點盡可能遠離,在對新樣本進行分類時,將其投影到同樣的這條直線上,再根據投影點的位置來確定新樣本的類別。圖3.3給出了一個二維示意圖。
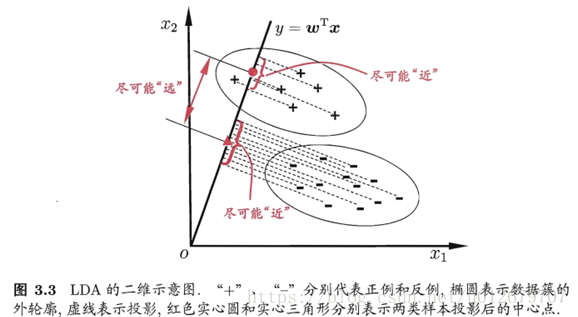
2. LDA求解方法
問:LDA最終要求什麽?
求投影空間W。 假設要投影到d維空間,W為這最大的d個特征值對應的特征向量張成的矩陣。所以問題轉化為求解特征向量w
求解過程如下:
給定數據集,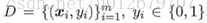
若將數據投影到直線w上,則兩類樣本的中心在直線上的投影分別為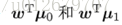
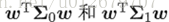
由於直線是一維空間,因此
本著同類樣例的投影點盡可能接近、異類樣例的投影點盡可能遠離的原則,欲使同類樣例的投影點盡可能接近,可以讓同類樣例投影點的協方差盡可能小,即


定義"類內散度矩陣"

以及"類間散度矩陣"

則式 (3.32)可重寫為

這就是LDA欲最大化的目標,即Sw與Sb的"廣義瑞利商" (Rayleigh)。根據廣義瑞利商的性質,我們知道我們的J(w)最大值為矩陣
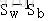

如何求解w呢?(w向量決定投影方向)
如何確定ω呢? 註意到式(3.35)的分子和分母都是關於ω的二次項,因此式(3.35)的解與ω的長度無關,只與其方向有關。(why? 二次項的性質,若w是一個解,則對於任意常數α,αw也是式(3.35)的解.)
不失一般性,令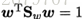

由拉格朗日乘子法,上式等價於

其中λ是拉格朗日乘子。註意到
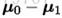

代入式 (3.37) 即得

3. 將LDA推廣到多分類
如何將LDA推廣到多分類任務中?
假定存在N個類,且第i類示例數為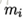
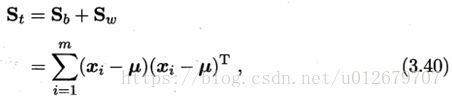
其中μ是所有示例的均值向量。將類內散度矩陣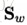

其中,
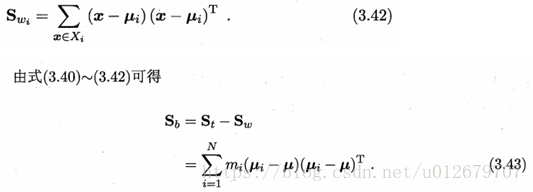
例如:三類問題如下直觀圖所示:

顯然,多分類 LDA 可以有多種實現方法:使用
常見的一種實現是采用優化目標:

其中的tr()為矩陣的跡,一個n×n的對角矩陣A的主對角線(從左上方至右下方的對角線)上各個元素的總和被稱為矩陣A的跡(或跡數),一般記作tr(A)。 這個優化目標實際上等價於求解N-1個w(特征向量)組合成W。
若將W視為一個投影矩陣,則多分類LDA將樣本投影到N-1維空間,N-1通常遠小於數據原有的屬性數(維度)。於是,可通過這個投影來減小樣本點的維數,且投影過程中使用了類別信息,因此LDA也常被視為一種經典的監督降維技術(可用於特征提取)。
附:另一種多類推廣原理解釋:

問: LDA是什麽?基本原理?
LDA是線性判別分析,LDA的基本思想是: 給定訓練樣例集,設法將樣例投影到一條直線上,使得同類樣例的投影點盡可能接近、異類樣例的投影點盡可能遠離,在對新樣本進行分類時,將其投影到同樣的這條直線上,再根據投影點的位置來確定新樣本的類別。
問:LDA最終要求什麽?
求投影空間W。
問:W是如何構成的?
假設要投影到d維空間,W為這最大的d個特征值對應的特征向量張成的矩陣。
分析一下,既然LDA的二分類的訓練過程,是將訓練樣本點投影到一條直線上(降維到一維),那麽投影空間就是一條直線,W=(w1)是最大特征值對應的特征向量,代表這條直線一維空間(W=(w1)=n*1維度)。如果是多分類情況,多分類LDA將樣本投影到d維空間,d通常遠小於數據原有的屬性數(維度),那麽投影空間W=(w1,w2,…w(d) )為最大的d個特征值對應的特征向量張成的矩陣,則投影矩陣W=n*d維度。
註意:上述w1是向量,在樣本是n維向量,類別數為k時,w1應是n維向量,則投影到d維空間時,投影空間W=(w1,w2,…w(d) )=n*d維度
問:LDA降維最多降到多少?(類別數為k)
LDA降維最多降到類別數k-1的維數。由於投影矩陣W是一個利用了樣本的類別得到的投影矩陣(n*d,一般d<<n),而
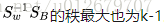
再問:為什麽最大維度不是類別數k呢?
因為

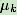
和
不是線性無關的, 前k-1個
和
可以表示線性表出第k個
i ),因此

4. LDA算法流程

以上就是使用LDA進行降維的算法流程。
實際上LDA除了可以用於降維以外,還可以用於分類。一個常見的LDA分類基本思想是假設各個類別的樣本數據符合高斯分布,這樣利用LDA進行投影後,可以利用極大似然估計計算各個類別投影數據的均值和方差,進而得到該類別高斯分布的概率密度函數。當一個新的樣本到來後,我們可以將它投影,然後將投影後的樣本特征分別帶入各個類別的高斯分布概率密度函數,計算它屬於這個類別的概率,最大的概率對應的類別即為預測類別。
5. LDA和PCA對比
LDA用於降維,和PCA有很多相同,也有很多不同的地方,因此值得好好的比較一下兩者的降維異同點。
首先我們看看相同點:
1)兩者均可以對數據進行降維。
2)兩者在降維時均使用了矩陣特征分解的思想。(求特征值、特征向量)
3)兩者都假設數據符合高斯分布。
我們接著看看不同點:
1)LDA是有監督的降維方法,而PCA是無監督的降維方法
2)LDA降維最多降到類別數k-1的維數,而PCA沒有這個限制。
3)LDA除了可以用於降維,還可以用於分類。
4)LDA選擇分類性能最好的投影方向,而PCA選擇樣本點投影具有最大方差的方向。
這點可以從下圖形象的看出,在不同數據分布下LDA和PCA降維的優勢不同。二者各有優缺。


附: LDA算法的主要優點有:
1)在降維過程中可以使用類別的先驗知識經驗,而像PCA這樣的無監督學習則無法使用類別先驗知識。
2)LDA在樣本分類信息依賴均值而不是方差的時候,比PCA之類的算法較優。
LDA算法的主要缺點有:
1)LDA不適合對非高斯分布樣本進行降維,PCA也有這個問題。
2)LDA降維最多降到類別數k-1的維數,如果我們降維的維度大於k-1,則不能使用LDA。當然目前有一些LDA的進化版算法可以繞過這個問題。
3)LDA在樣本分類信息依賴方差而不是均值的時候,降維效果不好。
4)LDA可能過度擬合數據。
---------------------------------------------- 附錄 ------------------------------------------------
【附錄1】瑞利商與廣義瑞利商
首先來看看瑞利商的定義。瑞利商是指這樣的函數:
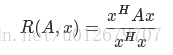
其中為非零向量,而為的Hermitan矩陣。所謂的Hermitan矩陣就是滿足共軛轉置矩陣和自己相等的矩陣,即
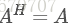
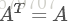
瑞利商有一個非常重要的性質,即它的最大值等於矩陣A 最大的特征值,而最小值等於矩陣A 的最小的特征值,也就是滿足:
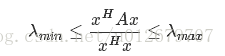 當向量x 是標準正交基時,即滿足
當向量x 是標準正交基時,即滿足  時,瑞利商退化為:
時,瑞利商退化為: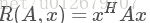
 。 這個形式在譜聚類和PCA中都有出現。
以上就是瑞利商的內容,現在我們再看看廣義瑞利商。廣義瑞利商是指這樣的函數
。 這個形式在譜聚類和PCA中都有出現。
以上就是瑞利商的內容,現在我們再看看廣義瑞利商。廣義瑞利商是指這樣的函數 :
:
 其中x為非零向量,而A,B為n*n的Hermitan矩陣。B為正定矩陣。
它的最大值和最小值是什麽呢?其實我們只要通過將其通過標準化就可以轉化為瑞利商的格式。我們令
其中x為非零向量,而A,B為n*n的Hermitan矩陣。B為正定矩陣。
它的最大值和最小值是什麽呢?其實我們只要通過將其通過標準化就可以轉化為瑞利商的格式。我們令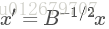 則分母轉化為:
則分母轉化為:
 而分子轉化為:
而分子轉化為:
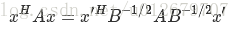
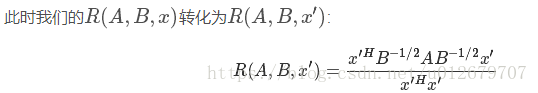
利用前面的瑞利商的性質,我們可以很快的知道 
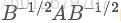
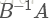

------------------------------------------- END -------------------------------------
參考:周誌華《機器學習》
降維方法-LDA線性判別分析