
機器學習流程介紹
本文只是對機器學習的流程做一個簡單的描述,每個環節涉及的東西很多,不是本文介紹的範圍,對其中比較重要的知識點稍微提及一下,具體的可以參考其他文章學習。先上一張流程圖。
機器學習從資料準備到上線流程:
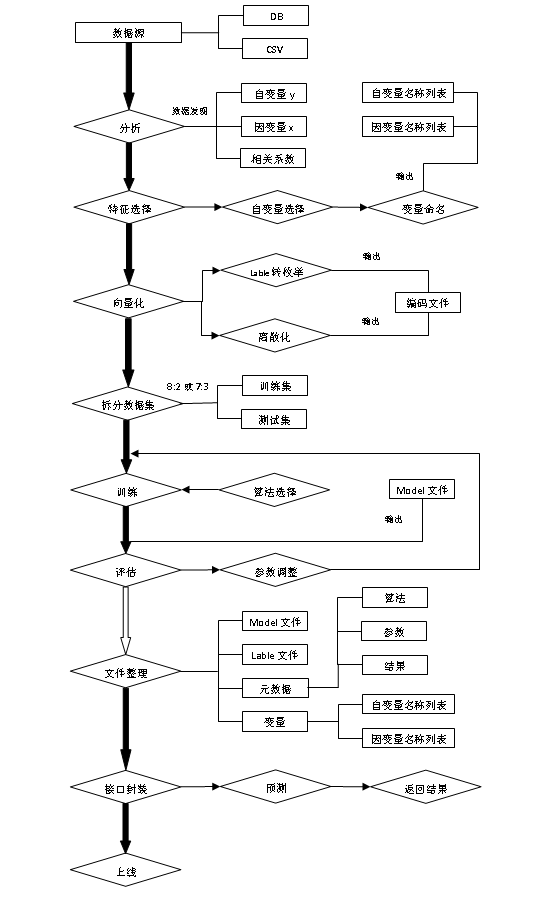
接下來根據流程圖,逐步分析機器學習的流程。
1. 資料來源:
機器學習的第一個步驟就是收集資料,這一步非常重要,因為收集到的資料的質量和數量將直接決定預測模型是否能夠建好。我們可以將收集的資料去重複、標準化、錯誤修正等等,儲存成資料庫檔案或者csv格式檔案,為下一步資料的載入做準備。
2. 分析:
這一步驟主要是資料發現,比如找出每列的最大、最小值、平均值、方差、中位數、三分位數、四分位數、某些特定值(比如零值)所佔比例
3. 特徵選擇:
特徵的好壞很大程度上決定了分類器的效果。將上一步驟確定的自變數進行篩選,篩選可以手工選擇或者模型選擇,選擇合適的特徵,然後對變數進行命名以便更好的標記。命名檔案要存下來,在預測階段的時候會用到。
4. 向量化:
向量化是對特徵提取結果的再加工,目的是增強特徵的表示能力,防止模型過於複雜和學習困難,比如對連續的特徵值進行離散化,label值對映成列舉值,用數字進行標識。這一階段將產生一個很重要的檔案:
5. 拆分資料集:
需要將資料分為兩部分。用於訓練模型的第一部分將是資料集的大部分。第二部分將用於評估我們訓練有素的模型的表現。通常以8:2或者7:3進行資料劃分。不能直接使用訓練資料來進行評估,因為模型只能記住“問題”。
6. 訓練:
進行模型訓練之前,要確定合適的演算法,比如線性迴歸、決策樹、隨機森林、邏輯迴歸、梯度提升、SVM等等。選擇演算法的時候最佳方法是測試各種不同的演算法,然後通過交叉驗證選擇最好的一個。但是,如果只是為問題尋找一個“足夠好”的演算法,或者一個起點,也是有一些還不錯的一般準則的,比如如果訓練集很小,那麼高偏差/低方差分類器(如樸素貝葉斯分類器)要優於低偏差
7. 評估:
訓練完成之後,通過拆分出來的訓練的資料來對模型進行評估,通過真實資料和預測資料進行對比,來判定模型的好壞。模型評估的常見的五個方法:混淆矩陣、提升圖&洛倫茲圖、基尼係數、ks曲線、roc曲線。混淆矩陣不能作為評估模型的唯一標準,混淆矩陣是算模型其他指標的基礎。
混淆矩陣
預測資料 | |||
J | G | ||
真實資料 | J | X1 | X2 |
G | X3 | X4 | |
備註:X1為作出正確判斷的否定記錄
X2為作出錯誤判斷的肯定記錄
X3為作出錯誤判斷的否定記錄
X4為作出正確判斷的肯定記錄
可以通過以下三個指標來評估模型的好壞:
準確率:P = X4/ ( X2 + X4)
召回率:R = X4/ ( X3 + X4)
調和平均數:F = 2PR/ ( R + P )
完成評估後,如果想進一步改善訓練,我們可以通過調整模型的引數來實現,然後重複訓練和評估的過程。
8. 檔案整理:
模型訓練完之後,要整理出四類檔案,確保模型能夠正確執行,四類檔案分別為:Model檔案、Lable編碼檔案、元資料檔案(演算法,引數和結果)、變數檔案(自變數名稱列表、因變數名稱列表)。
9. 介面封裝:
通過封裝封裝服務介面,實現對模型的呼叫,以便返回預測結果。
10. 上線: