
簡單易學的機器學習演算法——極限學習機(ELM)
阿新 • • 發佈:2019-01-30
一、極限學習機的概念
極限學習機(Extreme Learning Machine) ELM,是由黃廣斌提出來的求解單隱層神經網路的演算法。
ELM最大的特點是對於傳統的神經網路,尤其是單隱層前饋神經網路(SLFNs),在保證學習精度的前提下比傳統的學習演算法速度更快。
二、極限學習機的原理
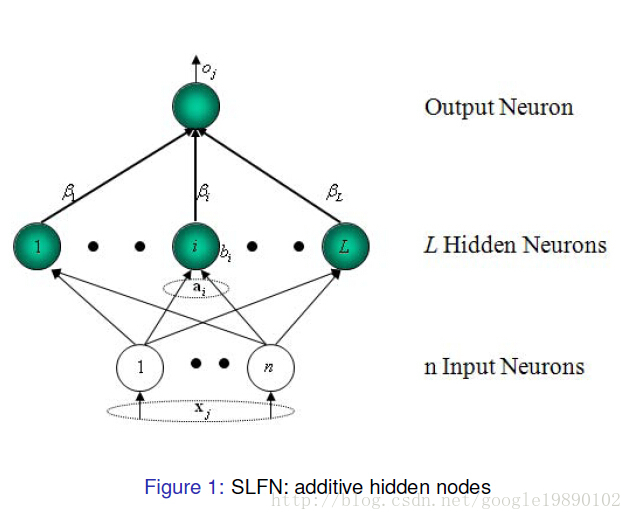
ELM是一種新型的快速學習演算法,對於單隱層神經網路,ELM可以隨機初始化輸入權重和偏置並得到相應的輸出權重。
(選自黃廣斌老師的PPT)
對於一個單隱層神經網路(見Figure 1),假設有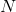
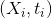
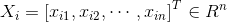
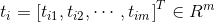
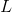
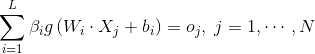
其中,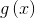
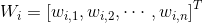 為輸出權重,
為輸出權重,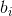
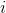
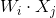
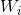
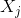
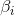
單隱層神經網路學習的目標是使得輸出的誤差最小,可以表示為
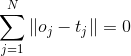
即存在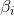
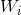
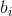
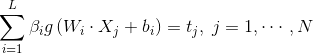
可以矩陣表示為
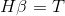
其中,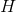
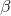
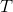
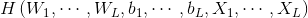
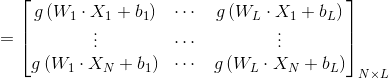
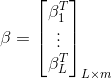
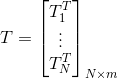
為了能夠訓練單隱層神經網路,我們希望得到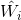
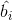
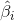
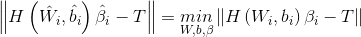
其中,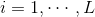
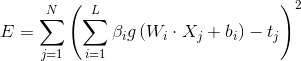
傳統的一些基於梯度下降法的演算法,可以用來求解這樣的問題,但是基本的基於梯度的學習演算法需要在迭代的過程中調整所有引數。而在ELM演算法中, 一旦輸入權重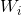
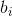
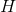
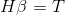
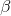
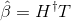
其中,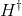
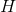 的範數是最小的並且唯一。
的範數是最小的並且唯一。
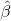
三、實驗
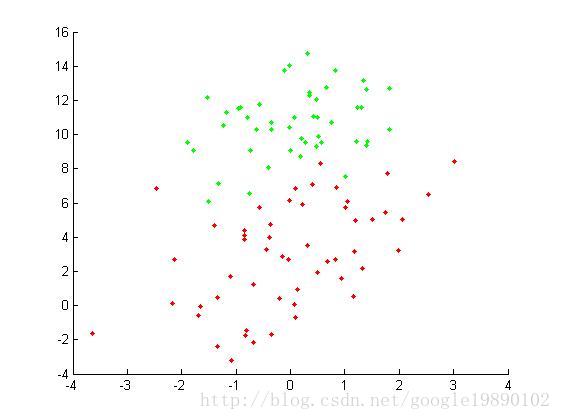
原始資料集我們採用統計錯誤率的方式來評價實驗的效果,其中錯誤率公式為:
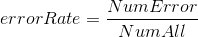
對於這樣一個簡單的問題,
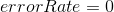 。MATLAB程式碼主程式
。MATLAB程式碼主程式%% 主函式,二分類問題 %匯入資料集 A = load('testSet.txt'); data = A(:,1:2);%特徵 label = A(:,3);%標籤 [N,n] = size(data); L = 100;%隱層節點個數 m = 2;%要分的類別數 %--初始化權重和偏置矩陣 W = rand(n,L)*2-1; b_1 = rand(1,L); ind = ones(N,1); b = b_1(ind,:);%擴充成N*L的矩陣 tempH = data*W+b; H = g(tempH);%得到H %對輸出做處理 temp_T=zeros(N,m); for i = 1:N if label(i,:) == 0 temp_T(i,1) = 1; else temp_T(i,2) = 1; end end T = temp_T*2-1; outputWeight = pinv(H)*T; %--畫出圖形 x_1 = data(:,1); x_2 = data(:,2); hold on for i = 1 : N if label(i,:) == 0 plot(x_1(i,:),x_2(i,:),'.g'); else plot(x_1(i,:),x_2(i,:),'.r'); end end output = H * outputWeight; %---計算錯誤率 tempCorrect=0; for i = 1:N [maxNum,index] = max(output(i,:)); index = index-1; if index == label(i,:); tempCorrect = tempCorrect+1; end end errorRate = 1-tempCorrect./N;
啟用函式
function [ H ] = g( X )
H = 1 ./ (1 + exp(-X));
end
黃老師提供的極限學習機的程式碼:點選開啟連結