
HBase並行寫機制(mvcc)
HBase在保證高效能的同時,為使用者提供了便於理解的一致性資料模型MVCC (Multiversion Concurrency Control),即多版本併發控制技術,把資料庫的行鎖與行的多個版本結合起來,從而去提高資料庫系統的併發效能。
要理解mvcc,首先需知道為什麼需要進行併發控制,我們知道關係型資料庫一般都提供了跨越所有資料的ACID特性,為了效能考慮,HBase只提供了基於單行的ACID,維基上是這樣介紹ACID的:
- 原子性(Atomicity):事務作為一個整體被執行,包含在其中的對資料庫的操作要麼全部被執行,要麼都不執行。
- 一致性(Consistency):事務應確保資料庫的狀態從一個一致狀態轉變為另一個一致狀態。一致狀態的含義是資料庫中的資料應滿足完整性約束。
- 隔離性(Isolation):多個事務併發執行時,一個事務的執行不應影響其他事務的執行。
- 永續性(Durability):已被提交的事務對資料庫的修改應該永久儲存在資料庫中。

具體寫入資料時是以KeyValue為資料單位的,對於上圖中的資料來說,實際寫入時有四個KeyValue,每個寫入執行緒負責寫入兩個KeyValue,如果HBase沒有相應的併發控制,則這四個KeyValue寫入MemStore的順序是無法預料的,可能會出現以下情況:

最終得到的結果是:

這樣就得到了不一致的結果。顯然我們需要對併發寫操作進行同步。最簡單的一種方案是在對某一行進行操作之前,首先顯式對該行進行加鎖操作,加鎖成功後才進行相應操作,否則只能等待獲取鎖,此時,寫入流程如下:
- (0) 獲取行鎖
- (1) 寫WAL檔案
- (2) 更新MemStore:將每個cell寫入到memstore
- (3) 釋放行鎖
引入行鎖的機制後,就可以避免併發情景下,對同一行資料進行操作(寫入或更新)時出現數據交錯的情況。
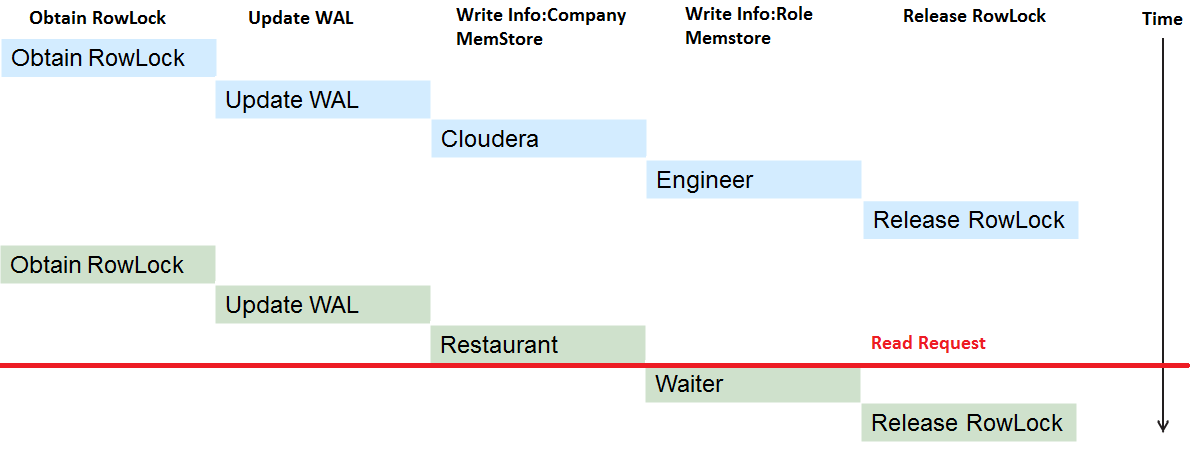
如上圖所示,如果讀取請求正好在Waiter被寫入MemStore之前被執行,最終得到的結果是:

可見需要對讀和寫也進行併發控制,不然會得到不一致的資料。最簡單的方案就是讀和寫公用一把鎖。這樣雖然保證了ACID特性,但是讀寫操作同時搶佔鎖會互相影響各自的效能。
最簡單的方案是和寫入一樣,在讀取操作前後分別加入獲取鎖與釋放鎖的步驟,這樣的話,效能一下子就下來了。HBase使用了一種mvcc的策略來避免讀取的鎖操作。mvcc對於寫操作:
- (w1) 獲取行鎖後,每個寫操作都立即分配一個寫序號
- (w2) 寫操作在儲存每個資料cell時都要帶上寫序號
- (w3) 寫操作需要申明以這個寫序號來完成本次寫操作
對於讀操作:
- (r1) 每個讀操作開始都分配一個讀序號,也稱為讀取點
- (r2) 讀取點的值是所有的寫操作完成序號中的最大整數(所有的寫操作完成序號<=讀取點)
- (r3) 對某個(row,column)的讀取操作r來說,結果是滿足寫序號為“寫序號<=讀取點這個範圍內”的最大整數的所有cell值的組合
使用了MVCC策略的執行過程如下:

採用MVCC後,每一次寫操作都有一個寫序號(即w1步),每個cell資料寫memstore操作都有一個寫序號(w2,例如:“Cloudera [wn=1]”)),並且每次寫操作完成也是基於這個寫序號(w3)。
如果在“Restaurant [wn=2]” 這步之後,“Waiter [wn=2]”這步之前,開始一個讀操作。根據規則r1和r2,讀的序號為1。根據規則3,讀操作以序號1讀到的值是:

這樣就實現了以無鎖的方式讀取到一致的資料了。
總結:
引入MVCC後寫入操作流程如下:
- (0) 獲取行鎖
- (0a) 獲取寫序號
- (1) 寫WAL檔案
- (2) 更新MemStore:將每個cell寫入到memstore
- (2a) 以寫序號完成操作
- (3) 釋放行鎖
參考英文:https://blogs.apache.org/hbase/tags/mvcc