
爬蟲那些事兒-任務排程系統設計
前言
對於一家資訊媒體公司而言,爬蟲可以說是第一道,也是最重要的補給線與產品線。爬蟲聚焦於開發與維護各類網路資訊抓取工具,通過獲取到數量大、質量高的資料,為運營、演算法、大資料等各個部門提供資料支援,保證公司的業務良好執行,而排程則是許多抓取程式中比較重要的一環。
一 、任務排程系統設計的重要性
分散式系統中比如Hadoop、MapReduce程式設計模型、還有其它大資料系統都會設計到任務排程。搜尋引擎爬蟲、新聞聚合公司爬蟲面對的抓取url種子都是幾十萬、上百萬甚至更多,這麼多網頁種子需要去抓取資源如果沒有一個較好的排程系統,整個系統將會一片混亂。排程系統可以解決以下問題:

試想想如果一會一大堆種子要抓取,一會很長時間沒有任務這就導致,閒的時候機器是空閒的,忙的時候特別忙網路請求非常頻繁。
好的任務排程,能夠更有效的利用機器資源,達到負載均衡 ,同時提高抓取效率,也能保證資料的平均。
二、設計思路
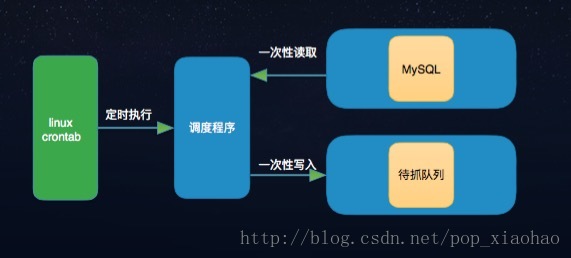
圖2-1
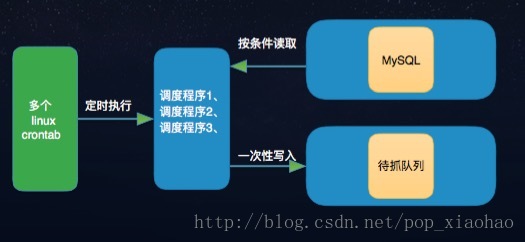
圖2-2
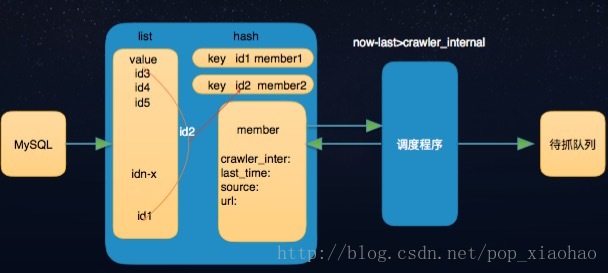
圖2-3
此排程系統是慢慢迭代開發,如圖2-1,之前的話種子不是特別多,就通過linux crontab 指令0 */5 * * * sh /data/get_xpath/start.sh 去執行,這樣的話無法做到去區分種子,隨著種子資料變多,這種機制完全不符合需求了。後來就採取區別對待如圖2-2,就是多個 crontab 多個程式分別排程不同週期的程式。這樣的解決方法也真是easy啊,當然還可以用另外一種方式進行處理,利用併發包中的Executors.newScheduledThreadPool(1);方式,執行多個scheduleWithFixedDelay方法去實現:程式碼如下,
private ScheduledExecutorService scheduExec = Executors.newScheduledThreadPool(1);
MyTask fifteenMinuTask = new MyTask(60*15);
scheduExec.scheduleWithFixedDelay(fifteenMinuTask, 0, 15, TimeUnit.MINUTES);
MyTask oneHourTask = new MyTask(60*60);
scheduExec.scheduleWithFixedDelay(oneHourTask, 0 , 1, TimeUnit.HOURS);
MyTask fourHourTask = new MyTask(60*60*4);
scheduExec.scheduleWithFixedDelay(fourHourTask, 0, 4, TimeUnit.HOURS);
MyTask twelveHourTask = new MyTask(60*60*12);
scheduExec.scheduleWithFixedDelay(twelveHourTask, 0, 12, TimeUnit.HOURS);
定義了四個任務排程方法,分別15分鐘,1小時,4小時和12小時排程一次~
圖2-3是最終的排程實現方式,上面的方法不能滿足需求,一個是經常性的對資料庫進行操作,操作效率不高,另外一個就是想修改排程頻率還是需要重新修改程式碼,也不能達到資料的平均化。最終形成圖2-3的模式,引入快取redis,通過定義一個list佇列和hash儲存結構來滿足需要,可以把起想象成多個環。按抓取週期分佈在這個週期的環裡,如

假設一組任務排程週期是10分鐘,讓這組資料平均分配到這600秒這個圓環上,然後不斷的輪詢這個圓 ,正常情況下就能保證相同週期的抓取任務能夠平均的推送到抓取系統中。
資料結構實現是不斷迴圈list,pop一條然後放到列尾,然後去hash去判斷是否應該推送:now() -last_push_time > = crawler_internal 噹噹前時間減去上一次推送時間就推送到抓取佇列中。
另外說明:當程式執行久了之後,排程可能不那麼均衡,就有隔一段時間進行初始化的操作,刪除redis 相關資料,重新載入最新資料。另外還有就是對資料進行更新,因為資料庫中的種子表是不斷新增以及更新,同時也會涉及到種子下架和排程週期調整。這些都需要考慮的。
以上就是爬蟲中排程系統的實現方案,通過這種土辦法最終達到需求。~