
希爾排序與快速排序
阿新 • • 發佈:2019-01-31
上節講的歸併排序執行速度比簡單排序塊,但是它需要的空間是原始陣列空間的兩倍;通常這是一個嚴重的缺點
希爾排序,希爾排序的時間複雜度是O(N*(logN)^2)。希爾排序是基於插入排序的。希爾排序又叫縮小增量排序,它是基於插入排序的增強版。
基本思想:把記錄按步長進行分組,對每組記錄採用直接插入的方法進行排序。隨著步長的縮小,所分成的組包含的記錄就越來越多,當步長的值減小到1時
,整個資料合成一組,構成一組有序的記錄,則完成排序。
過程如下圖所示:
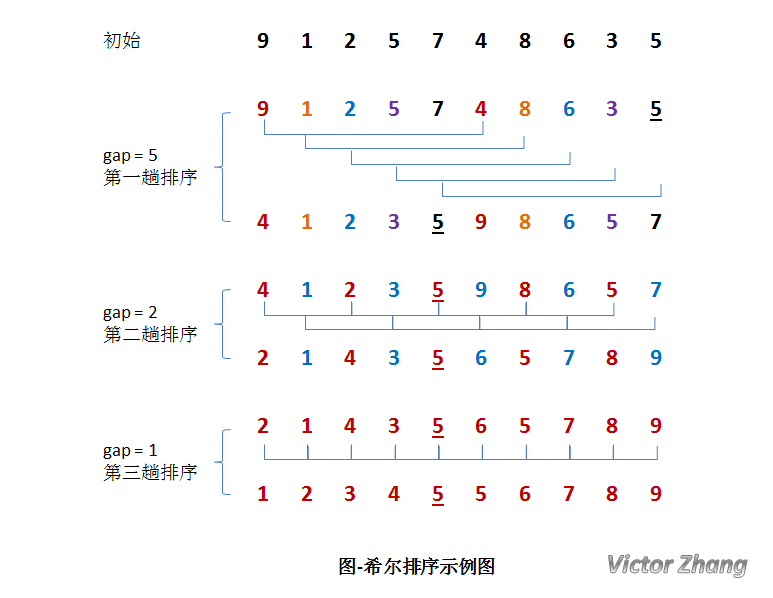
具體的執行步驟是:
1,在第一趟排序過程中,我們不妨設gap1=N/2=5,即為相隔距離為5的元素組成一組,可以分為5組。接下來,按照直接插入排序的方法對每個組進行排序。
2,第二趟排序中,我們把上次的gap縮小一半,即為gap2=gap1/2=2(取整數)。這樣每相隔距離為2的元素組成一組,可以分為2組。按照直接插入排序的方法
對每個組進行排序。
3,在第三趟排序中,再次把gap縮小一半,即為gap3=gap2/2=1。這樣相隔距離為1的元素組成一組,即只有一組。按照直接插入排序的演算法對每個組進行排序。此時排序結束。
注意希爾排序是不穩定的排序。
核心程式碼:
毫無疑問,快速排序是最流行的排序演算法,大多是情況下,快速排序都是最快的,執行時間是O(N*logN)級別。它是一種既不浪費空間也不浪費時間的排序演算法。
方法其實很簡單:給一個序列“6 1 2 7 9 3 4 5 10 8”兩端開始“探測”。以第一個數作為基準數(6),先從右向左找一個小於6的數,再從左向右找一個大於6的數,然後交換他們。這裡可以用兩個變數i和j,分別指向最左邊和最右邊。我們為這兩個變數起一個好聽的名字“哨兵i”和“哨兵j”。剛開始的時候讓哨兵i指向>序列的最左邊(即為i=0),指向數字6.讓哨兵j指向序列的最右邊(即為i=9),指向數字8.如圖:

首先哨兵j開始出動。因為此處設定的基準數是最左邊的數,所以需要讓哨兵j先出動,這一點非常重要。哨兵j一步一步的向左挪動(即為j--),直到找到一個小於6的數停下來。接下來哨兵i再一步一步向右挪動(即為i++),直到找到一個大於6的數停下來。最後哨兵j停在了數字5面前,哨兵i停在了數字7面前。如圖:
6 1 2 5 9 3 4 7 10 8
到此,第一次交換結束。接下來開始哨兵j繼續向左挪動(注意,每次必須數哨兵j先出發)。他發現了4(比基準數6要小,滿足要求)之後停了下來。哨兵i也繼續向右挪動,他發現了9(比基準數6大,滿足要求)之後停了下來。如下圖:
6 1 2 5 4 3 9 7 10 8
第二次交換結束後,“探測”繼續。哨兵j繼續向左挪動,他發現了3(比基準數6小,滿足要求)之後停了下來。哨兵i繼續向右挪動,糟糕!此時哨兵i和哨兵
j相遇,哨兵i和哨兵j都走到了3面前。說明此時“探測”結束。我們將基準數6和3進行交換。如下圖:
3 1 2 5 4 6 9 7 10 8
此時,第一輪“探測結束”。此時以基準數6為分界點,6左邊的數小雨等於6,6右邊的數大於等於6.
將以6為分界點的兩個子序列:3 1 2 5 4和9 7 10 8再次進行快速排序.整個圖的處理過程如下圖所示:

注意:快速排序的最差時間複雜度為O(N^2),它的平均複雜度為O(NlogN),它是基於“二分”的思想。
程式碼實現:
希爾排序,希爾排序的時間複雜度是O(N*(logN)^2)。希爾排序是基於插入排序的。希爾排序又叫縮小增量排序,它是基於插入排序的增強版。
基本思想:把記錄按步長進行分組,對每組記錄採用直接插入的方法進行排序。隨著步長的縮小,所分成的組包含的記錄就越來越多,當步長的值減小到1時
,整個資料合成一組,構成一組有序的記錄,則完成排序。
過程如下圖所示:
具體的執行步驟是:
1,在第一趟排序過程中,我們不妨設gap1=N/2=5,即為相隔距離為5的元素組成一組,可以分為5組。接下來,按照直接插入排序的方法對每個組進行排序。
2,第二趟排序中,我們把上次的gap縮小一半,即為gap2=gap1/2=2(取整數)。這樣每相隔距離為2的元素組成一組,可以分為2組。按照直接插入排序的方法
對每個組進行排序。
3,在第三趟排序中,再次把gap縮小一半,即為gap3=gap2/2=1。這樣相隔距離為1的元素組成一組,即只有一組。按照直接插入排序的演算法對每個組進行排序。此時排序結束。
注意希爾排序是不穩定的排序。
核心程式碼:
public void shellsort(int[] list){ int gap=list.length/2; while(gap>=1){ for(int i=gap;i<list.length;i++){ int j=i-gap; int temp=list[i]; if(j>=0&&list[j]>temp){ list[i]=list[j]; list[j]=temp; } } gap=gap/2; } printAll(list); }
毫無疑問,快速排序是最流行的排序演算法,大多是情況下,快速排序都是最快的,執行時間是O(N*logN)級別。它是一種既不浪費空間也不浪費時間的排序演算法。
方法其實很簡單:給一個序列“6 1 2 7 9 3 4 5 10 8”兩端開始“探測”。以第一個數作為基準數(6),先從右向左找一個小於6的數,再從左向右找一個大於6的數,然後交換他們。這裡可以用兩個變數i和j,分別指向最左邊和最右邊。我們為這兩個變數起一個好聽的名字“哨兵i”和“哨兵j”。剛開始的時候讓哨兵i指向>序列的最左邊(即為i=0),指向數字6.讓哨兵j指向序列的最右邊(即為i=9),指向數字8.如圖:
首先哨兵j開始出動。因為此處設定的基準數是最左邊的數,所以需要讓哨兵j先出動,這一點非常重要。哨兵j一步一步的向左挪動(即為j--),直到找到一個小於6的數停下來。接下來哨兵i再一步一步向右挪動(即為i++),直到找到一個大於6的數停下來。最後哨兵j停在了數字5面前,哨兵i停在了數字7面前。如圖:


6 1 2 5 9 3 4 7 10 8
到此,第一次交換結束。接下來開始哨兵j繼續向左挪動(注意,每次必須數哨兵j先出發)。他發現了4(比基準數6要小,滿足要求)之後停了下來。哨兵i也繼續向右挪動,他發現了9(比基準數6大,滿足要求)之後停了下來。如下圖:


6 1 2 5 4 3 9 7 10 8
第二次交換結束後,“探測”繼續。哨兵j繼續向左挪動,他發現了3(比基準數6小,滿足要求)之後停了下來。哨兵i繼續向右挪動,糟糕!此時哨兵i和哨兵
j相遇,哨兵i和哨兵j都走到了3面前。說明此時“探測”結束。我們將基準數6和3進行交換。如下圖:



3 1 2 5 4 6 9 7 10 8
此時,第一輪“探測結束”。此時以基準數6為分界點,6左邊的數小雨等於6,6右邊的數大於等於6.
將以6為分界點的兩個子序列:3 1 2 5 4和9 7 10 8再次進行快速排序.整個圖的處理過程如下圖所示:
注意:快速排序的最差時間複雜度為O(N^2),它的平均複雜度為O(NlogN),它是基於“二分”的思想。
程式碼實現:
public void quicksort(int[] n,int left,int right){
int dp;
if(left<=right){
dp=partion(n,left,right);
quicksort(n,left,dp-1);
quicksort(n,dp+1,right);
}
}
public void partion(int[] n,int left,int right){
int pro=n[left];
int start=left;
int temp=0;
while(left<right){
while(left<right&&n[right]>=pro){
right--;
}
if(left<right){
temp=n[right];
}
while(left<right&&n[left]<=pro){
left++;
}
if(left<right){
n[right--]=n[left]
n[left++]=temp
}
}
n[start]=n[left];
n[left]=pro;
return left;
}