
深度強化學習——從DQN到DDPG
引言
深度強化學習最近取得了很多進展,並在機器學習領域得到了很多的關注。傳統的強化學習侷限於動作空間和樣本空間都很小,且一般是離散的情境下。然而比較複雜的、更加接近實際情況的任務則往往有著很大的狀態空間和連續的動作空間。實現端到端的控制也是要求能處理高維的,如影象、聲音等的資料輸入。前些年開始興起的深度學習,剛好可以應對高維的輸入,如果能將兩者結合,那麼將使智慧體同時擁有深度學習的理解能力和強化學習的決策能力。2013和2015年DeepMind的DQN可謂是將兩者成功結合的開端,它用一個深度網路代表價值函式,依據強化學習中的Q-Learning,為深度網路提供目標值,對網路不斷更新直至收斂。DQN用到了兩個關鍵技術,一是用來打破樣本間關聯性的樣本池,二是使訓練穩定性和收斂性更好的固定目標網路。DQN可以應對高維輸入,而對高維的動作輸出則束手無策。隨後,同樣是DeepMind提出的DDPG,則可以解決有著高維或者說連續動作空間的情境。它包含一個策略網路用來生成動作,一個價值網路用來評判動作的好壞,並吸取DQN的成功經驗,同樣使用了樣本池和固定目標網路,是一種結合了深度網路的Actor-Critic方法。
一、強化學習
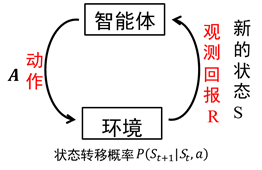
智慧體在完成某項任務時,如上圖所示,首先通過動作A與周圍環境進行互動,在動作A和環境的作用下,智慧體會產生新的狀態,同時環境會給出一個立即回報。如此迴圈下去,智慧體與環境進行不斷地互動從而產生很多資料。強化學習演算法利用產生的資料修改自身的動作策略,再與環境互動,產生新的資料,並利用新的資料進一步改善自身的行為,經過數次迭代學習後,智慧體能最終地學到完成相應任務的最優動作(最優策略)。這就是一個強化學習的過程。
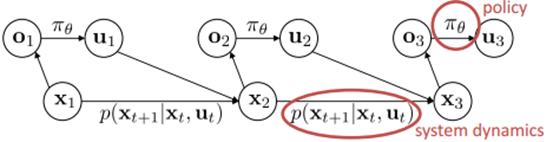
強化學習所面對的是一個連續決策過程。這一問題框架基於一個MDP過程,即馬爾科夫決策過程,如上圖所示。智慧體面對的環境有一個狀態空間X,智慧體自己有一個動作空間U,智慧體根據狀態的觀察值O來進行決策。環境動態模型或者說轉移概率描述了狀態間是如何轉化的,策略描述了智慧體如何決策。
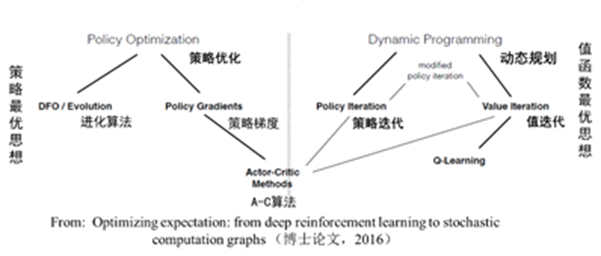
如上圖所示,強化學習根據以策略為中心還是以值函式最優可以分為兩大類,策略優化 方法和動態規劃方法。其中策略優化方法又分為進化演算法和策略梯度方法;動態規劃方法分為策略迭代演算法和值迭代演算法。策略迭代演算法和值迭代演算法可以用廣義策略迭代方法進行統一描述。另外,強化學習演算法根據策略是否是隨機的,分為確定性策略強化學習和隨機性策略強化學習。根據轉移概率是否已知可以分為基於模型的強化學習和無模型的強化學習演算法。另外,強化學習演算法中的回報函式r十分關鍵,根據回報函式是否已知,可以分為強化學習和逆向強化學習。逆向強化學習是根據專家演示將回報函式學習出來。
二、策略梯度
策略梯度方法中,將策略引數化表示為,計算出關於動作的策略函式梯度,不斷調整動作,靠近最優策略。策略梯度的計算公式已由相關學者推導得到,且有兩種策略梯度,一是隨機性策略梯度,二是確定性策略梯度。
1、隨機性策略梯度:
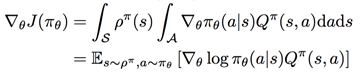
2、確定性策略梯度:
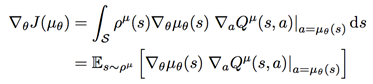
證明可參考相關論文。總之,策略梯度的直觀理解是調整策略函式的引數,使得其給出的動作可以獲得較大的Q值。
Actor-Critic方法是一種很重要的強化學習演算法,其是一種時序差分方法(TD method),結合了基於值函式的方法和基於策略函式的方法。其中策略函式為行動者(Actor),給出動作;價值函式為評價者(Critic),評價行動者給出動作的好壞,併產生時序差分訊號,來指導價值函式和策略函式的更新。其框架如下圖:

將此方法與深度學習結合的話,則是分別用兩個深度網路去代表價值函式和策略函式。之後所介紹的DDPG就是基於這樣一種Actor-Critic架構的深度強化學習方法。
三、DQN
DeepMind在2013年提出的DQN演算法(2015年提出了DQN的改進版本)可以說是深度學習和強化學習的第一次成功結合。要想將深度學習融合進強化學習,是有一些很關鍵的問題需要解決的,其中的兩個問題如下:
1、深度學習需要大量有標籤的資料樣本;而強化學習是智慧體主動獲取樣本,樣本量稀疏且有延遲。
2、深度學習要求每個樣本相互之間是獨立同分布的;而強化學習獲取的相鄰樣本相互關聯,並不是相互獨立的。
若想將這兩者結合,必須解決包括上面兩點在內的問題。
DQN具體來說,是基於經典強化學習演算法Q-Learning,用深度神經網路擬合其中的Q值的一種方法。Q-Learning演算法提供給深度網路目標值,使其進行更新。先來看Q-Learning的演算法流程圖:
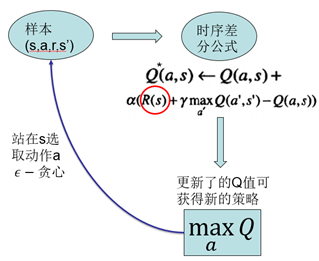
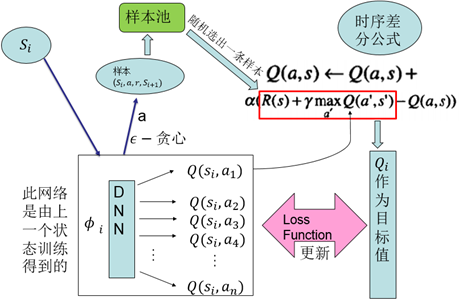
智慧體採用off-policy即執行的和改進的不是同一個策略,這通過方法實現。用這種方式取樣,並以線上更新的方式,每採集一個樣本進行一次對Q函式的更新。更新所依據的是時序差分公式。以更新後的Q函式得到新的策略。而這種經典強化學習演算法的侷限性在於,無法應對高維的輸入,且無法應用於大的動作空間,特別的,無法應用於連續動作輸出。DQN所做的是用一個深度神經網路進行端到端的擬合,發揮深度網路對高維資料輸入的處理能力。其2013年版本結構如下:
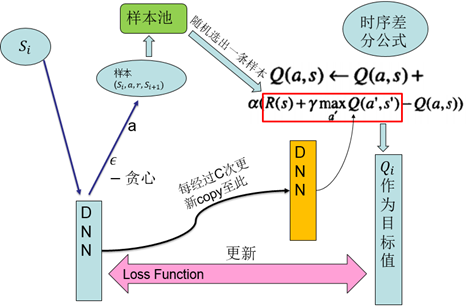
在2015年又釋出了其改進版本:
其有兩個關鍵技術:
1、樣本池(experience reply):將採集到的樣本先放入樣本池,然後從樣本池中隨機選出一條樣本用於對網路的訓練。這種處理打破了樣本間的關聯,使樣本間相互獨立。
2、固定目標值網路(fixed Q-target):計算網路目標值需用到現有的Q值,現用一個更新較慢的網路專門提供此Q值。這提高了訓練的穩定性和收斂性。
四、DDPG
DQN是一種基於值函式的方法,基於值函式的方法難以應對的是大的動作空間,特別是連續動作情況。因為網路難以有這麼多輸出,且難以在這麼多輸出之中搜索最大的Q值。而DDPG是基於上面所講到的Actor-Critic方法,在動作輸出方面採用一個網路來擬合策略函式,直接輸出動作,可以應對連續動作的輸出及大的動作空間。
再來回顧一下Acror-Critic結構。如下圖:
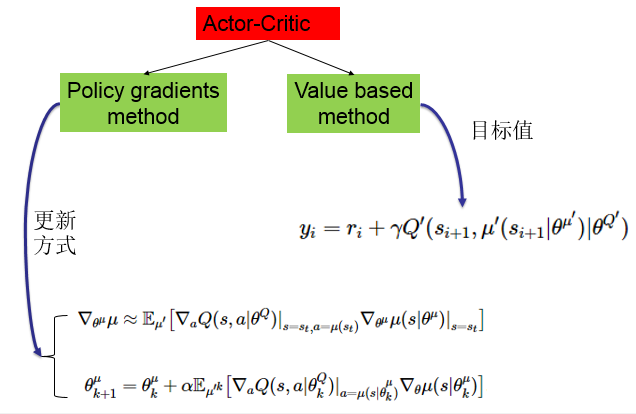
該結構包含兩個網路,一個策略網路(Actor),一個價值網路(Critic)。策略網路輸出動作,價值網路評判動作。兩者都有自己的更新資訊。策略網路通過梯度計算公式進行更新,而價值網路根據目標值進行更新。
DDPG採用了DQN的成功經驗。即採用了樣本池和固定目標值網路這兩項技術。也就是說這兩個網路分別有一個變化較慢的副本,該變化較慢的網路提供給更新資訊中需要的一些值。DDPG的整體結構如下:
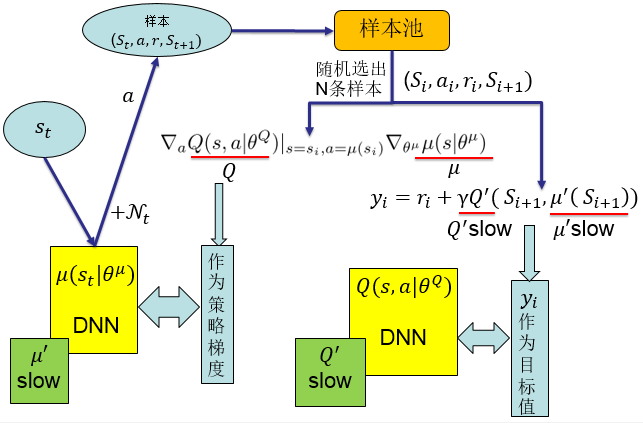
DDPG方法是深度學習和強化學習的又一次成功結合,是深度強化學習發展過程中很重要的一個研究成果。其可以應對高維的輸入,實現端對端的控制,且可以輸出連續動作,使得深度強化學習方法可以應用於較為複雜的有大的動作空間和連續動作空間的情境。
參考文獻:
[1] Silver D, Lever G, Heess N, et al. Deterministic Policy Gradient
Algorithms[C]// International Conference on Machine Learning. 2014:387-395.
[2] Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through
deep reinforcement learning.[J]. Nature, 2015, 518(7540):529.
[3] Mnih V, Kavukcuoglu K, Silver D, et al. Playing Atari with Deep
Reinforcement Learning[J]. Computer Science, 2013.
[4] Lillicrap T P, Hunt J J, Pritzel A, et al. Continuous control with deep
reinforcement learning[J]. Computer Science, 2015, 8(6):A187.
注:前四張圖片來自別處,如有侵權立即修改。文字及後五張彩色圖片為自己寫的和畫的,尤其是圖片畫得很用心~